5.6 Warp Shuffle Instructions
Published on 2018-06-06 | Category: CUDA , Freshman | Comments: 0 | Views:
Abstract: This article introduces the usage of warp shuffle instructions.
Keywords: Warp Shuffle Instructions
Warp Shuffle Instructions
We previously covered shared memory, constant memory, and read-only memory. Today we study a rather special mechanism with an equally special name -- warp shuffle instructions.
Devices supporting warp shuffle instructions require compute capability 3.0 or above.
Shuffle instructions operate within a warp, allowing two threads to access each other's registers. This provides a new channel for information exchange between threads within a warp. We know that variables inside a kernel function reside in registers. A warp can be viewed as 32 kernels executing in parallel. In other words, the register variables in these 32 kernels are physically neighbors, providing the physical basis for mutual access. Threads within a warp exchange data without going through shared memory or global memory, making communication much more efficient. Warp shuffle instructions have extremely low latency and consume no memory.
Warp shuffle instructions are an excellent method for intra-warp thread communication.
First, let's introduce the concept of a "lane" -- simply the index within a warp. A lane ID ranges from [0, 31] and is unique within a warp. "Unique" means unique within a warp -- a thread block may have many identical lane indices, just as a grid has many identical threadIdx.x values. There is also a warp ID. You can calculate a thread's lane index within the current thread block and warp ID as follows:
unsigned int LaneID=threadIdx.x%32;
unsigned int warpID=threadIdx.x/32;
According to this formula, threadIdx.x = 1, 33, 65, etc. within a thread block all have laneID = 1.
Different Forms of Warp Shuffle Instructions
Warp shuffle instructions come in two sets: one for integer variables and one for floating-point variables. There are four forms of shuffle instructions in total.
For exchanging integer variables within a warp, the basic function is:
int __shfl(int var,int srcLane,int width=warpSize);
This instruction requires careful study because the inputs are quite confusing. Who is confusing? var is confusing -- an int value. This variable is obviously a variable in the current thread. What is passed to the function is not the value stored in this variable, but the variable name. In other words, the current thread has a variable called var. For example, if thread 1's var value is 1, thread 2's var value may not be 1. So, __shfl returns the var value -- whose var value? That of the srcLane thread. srcLane is not the current thread's lane; it is a relative thread position calculated from width. For example, if I want to get the var value from thread 3 with width=16, then lanes 0-15 receive the var value from position 0+3, i.e., lane 3's var value. Lanes 16-31 receive the var value from position 16+3=19.
This is very important -- although somewhat difficult, it is quite flexible. The default width is 32. We will simply call srcLane the "lane" below. Note that we must mentally understand that only when width is the default value is it truly the lane.
Diagram:
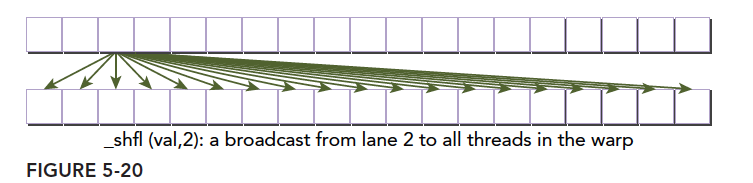
The next instruction's main feature is copying data from threads related to the calling thread:
int __shfl_up(int var,unsigned int delta,int width=warpSize);
This function makes the calling thread receive the var value from the thread whose lane index is the current lane minus delta. The width parameter is the same as in __shfl, defaulting to 32. The effect is as follows:
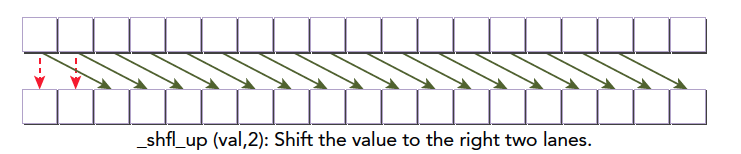
For other width values, based on our earlier explanation, the warp can be divided into blocks of size width, performing the operation shown above.
The leftmost two elements have no preceding delta thread, so they remain unchanged.
The next instruction is the reverse of the above:
int __shfl_down(int var,unsigned int delta,int width=warpSize);
The effect and parameters are identical to __shfl_up:
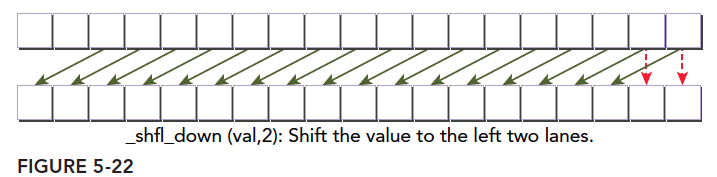
The last shuffle instruction is quite powerful and very flexible:
int __shfl_xor(int var,int laneMask,int width=warpSize);
XOR is the exclusive-or operation. Those who have studied hardware or have a solid grasp of C may know this is the most important operation in circuits, bar none. What is XOR? In logic, we assume only 0 and 1 signals, represented by "^":
0^0=0;
1^0=1;
0^1=1;
1^1=0;
A binary operation that returns true only when the two operands differ, false otherwise.
So __shfl_xor is a shuffle instruction that includes an XOR operation. How does it work?
If our input laneMask is 1 (binary: 000...001), and the current thread's index is a number between 0 and 31, we XOR laneMask with the current thread's index to get the target thread number. With laneMask = 1, XORing 1 with 0-31 gives:
000001^000000=000001;
000001^000001=000000;
000001^000010=000011;
000001^000011=000010;
000001^000100=000101;
000001^000101=000100;
.
.
.
000001^011110=011111;
000001^011111=011110;
This is the mapping between the current thread's lane index and the target thread's lane index. A diagram makes it very clear:
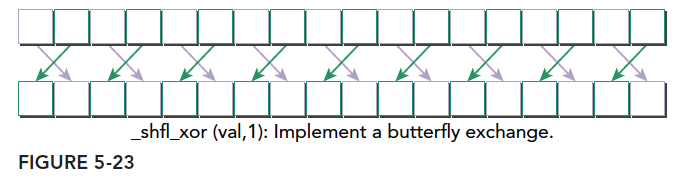
These are the four warp shuffle instructions for integer operations. The corresponding floating-point versions do not require changing the function name -- just change var to float, and the function will automatically overload.
Shared Memory Data within a Warps
Next, let's implement the code and observe the effect of each instruction. Shuffle instructions can be used with the following three integer variable types:
- Scalar variables
- Arrays
- Vector-type variables
Cross-Warp Value Broadcast
This is the effect of the __shfl function:
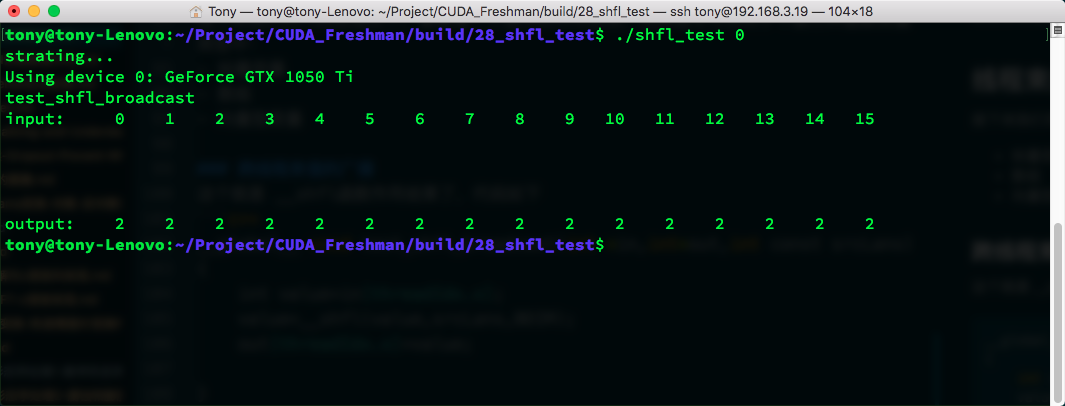
__global__ void test_shfl_broadcast(int *in,int*out,int const srcLane)
{
int value=in[threadIdx.x];
value=__shfl(value,srcLane,BDIM);
out[threadIdx.x]=value;
}
The process needs no explanation. Note that the var parameter corresponds to value, which is our target. srcLane is 2 here, so we obtain lane 2's value and assign it to the current thread. Hence, all lanes' values become 2:
Result:
Intra-Warp Upward Shift
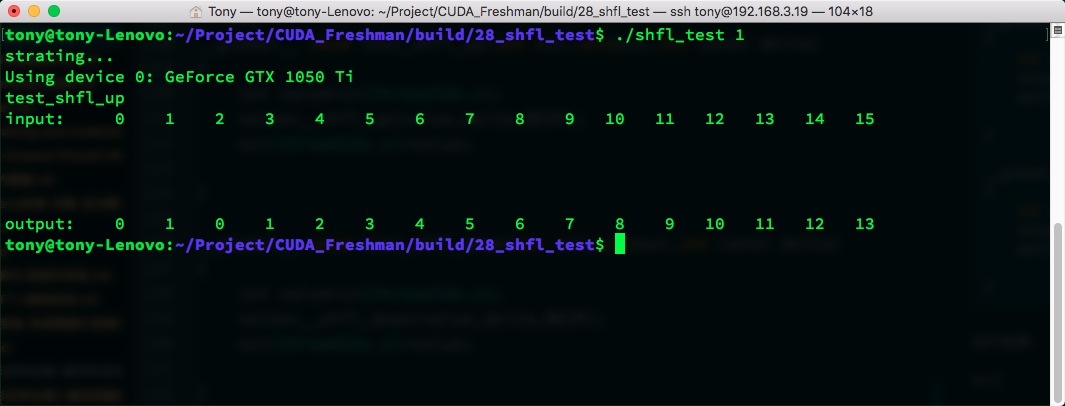
Using __shfl_up for upward shift:
__global__ void test_shfl_up(int *in,int*out,int const delta)
{
int value=in[threadIdx.x];
value=__shfl_up(value,delta,BDIM);
out[threadIdx.x]=value;
}
Result:
Intra-Warp Downward Shift
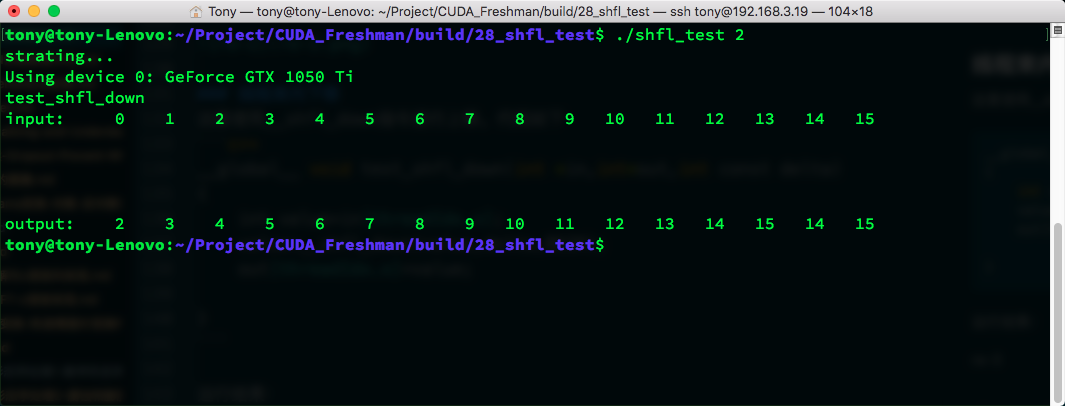
Using __shfl_down for downward shift:
__global__ void test_shfl_down(int *in,int*out,int const delta)
{
int value=in[threadIdx.x];
value=__shfl_down(value,delta,BDIM);
out[threadIdx.x]=value;
}
Result:
Intra-Warp Wrapped Movement
Then circular movement. We modify the __shfl parameters to change the static target to a dynamic one:
__global__ void test_shfl_wrap(int *in,int*out,int const offset)
{
int value=in[threadIdx.x];
value=__shfl(value,threadIdx.x+offset,BDIM);
out[threadIdx.x]=value;
}
With offset=2:
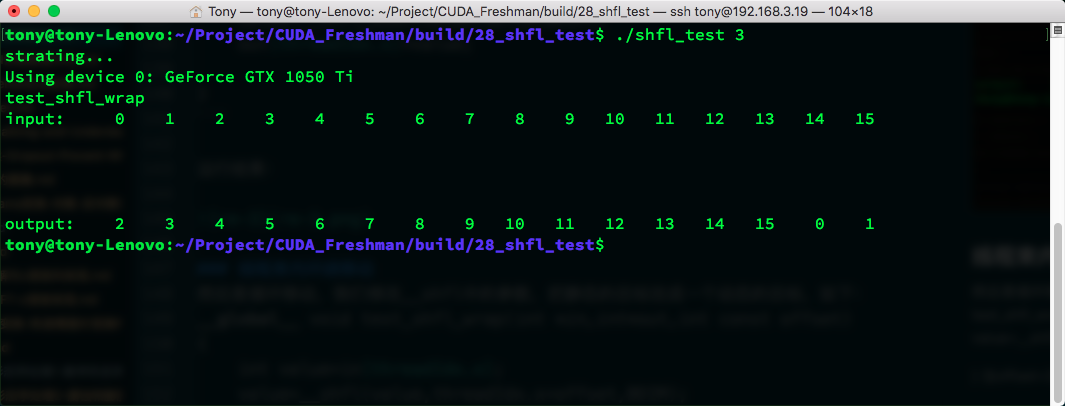
The first 14 elements' values are predictable, but elements 14 and 15 did not remain unchanged like in __shfl_down -- they obtained values from elements 0 and 1. We must conclude that __shfl's target thread calculation includes a modulo operation on width. The data we actually get comes from:
srcLane=srcLane%width;
This makes sense. Similarly, setting srcLane to -2 would give the corresponding upward wrapped movement.
Cross-Warp Butterfly Exchange
Now let's look at __shfl_xor. As I mentioned, this operation is very flexible -- you can compose any transformation you want. Let's start with the simple version from our theory:
__global__ void test_shfl_xor(int *in,int*out,int const mask)
{
int value=in[threadIdx.x];
value=__shfl_xor(value,mask,BDIM);
out[threadIdx.x]=value;
}
With mask set to 1:
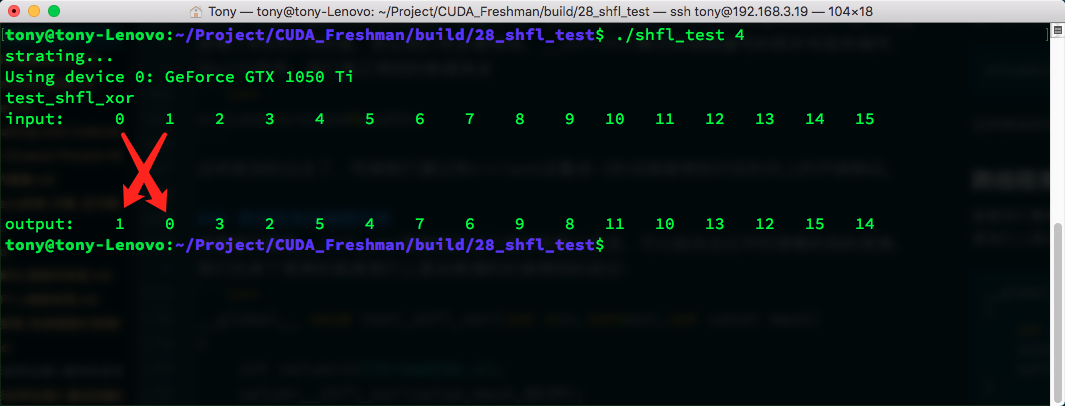
Can't help drawing an X pattern!
All as expected. Now let's look at something more advanced. I will also explain why arrays can be manipulated -- I was confused about this myself earlier.
Cross-Warp Array Value Exchange
We want to exchange arrays. If a thread has an array, we can exchange array positions. Here is a simple small array example:
__global__ void test_shfl_xor_array(int *in,int*out,int const mask)
{
//1.
int idx=threadIdx.x*SEGM;
//2.
int value[SEGM];
for(int i=0;i<SEGM;i++)
value[i]=in[idx+i];
//3.
value[0]=__shfl_xor(value[0],mask,BDIM);
value[1]=__shfl_xor(value[1],mask,BDIM);
value[2]=__shfl_xor(value[2],mask,BDIM);
value[3]=__shfl_xor(value[3],mask,BDIM);
//4.
for(int i=0;i<SEGM;i++)
out[idx+i]=value[i];
}
Where there is logic, code becomes complex. Let's walk through each step. First, we define a macro SEGM as 4. Each warp contains an array of SEGM size. Of course, this data resides in registers. If the array is too large, it may spill to local memory -- don't worry, it's still on-chip. This array is small enough that registers are sufficient.
Step by step:
- Calculate the array's starting address. Since our input data is 1D and each thread contains a SEGM-length segment, this calculates the starting position of the current thread's array.
- Declare the array, allocating register addresses (these are allocated at compile time), then read data from global memory.
- Compute the XOR between elements in the current thread's array and the target thread to exchange. With mask=1, this is equivalent to performing cross-warp butterfly exchanges on multiple register variables.
- Write the exchange results from registers back to global memory.
This looks complex but is essentially repeating the butterfly exchange above.
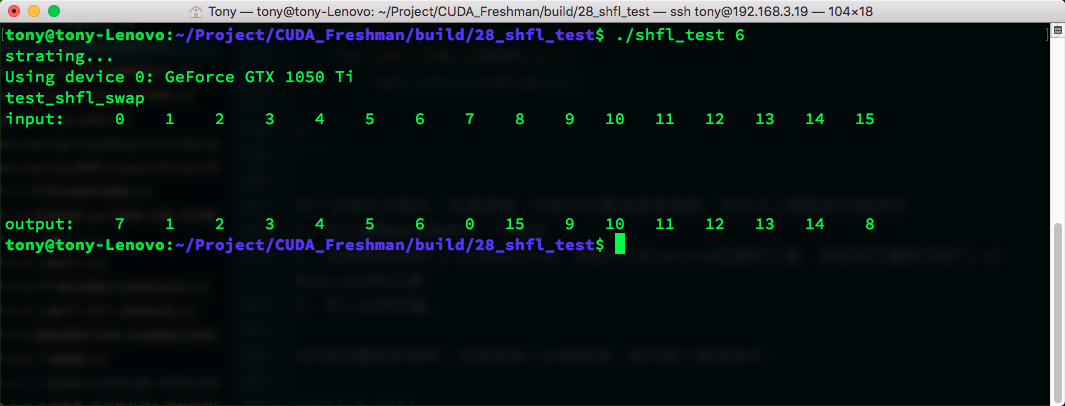
Big butterfly!
"Cross-warp" here means across the current warp, not crossing warps -- the title is somewhat confusing.
Cross-Warp Array Index Value Exchange
This next one is an extension -- exchanging a pair of values between two threads. This is also our first device function -- a function that can only be called by kernel functions:
__inline__ __device__
void swap(int *value,int laneIdx,int mask,int firstIdx,int secondIdx)
{
bool pred=((laneIdx%2)==0);
if(pred)
{
int tmp=value[firstIdx];
value[firstIdx]=value[secondIdx];
value[secondIdx]=tmp;
}
value[secondIdx]=__shfl_xor(value[secondIdx],mask,BDIM);
if(pred)
{
int tmp=value[firstIdx];
value[firstIdx]=value[secondIdx];
value[secondIdx]=tmp;
}
}
__global__ void test_shfl_swap(int *in,int* out,int const mask,int firstIdx,int secondIdx)
{
//1.
int idx=threadIdx.x*SEGM;
int value[SEGM];
for(int i=0;i<SEGM;i++)
value[i]=in[idx+i];
//2.
swap(value,threadIdx.x,mask,firstIdx,secondIdx);
//3.
for(int i=0;i<SEGM;i++)
out[idx+i]=value[i];
}
This process is somewhat complex. Each instruction's meaning is clear and similar to the array exchange above:
- Similar to the array exchange above -- not repeated.
- Exchange first and second within the array, then XOR the element at the second position, then re-exchange first and second.
- Write to global memory.
Step 2's description sounds simple but is actually quite involved. Let's draw a diagram:
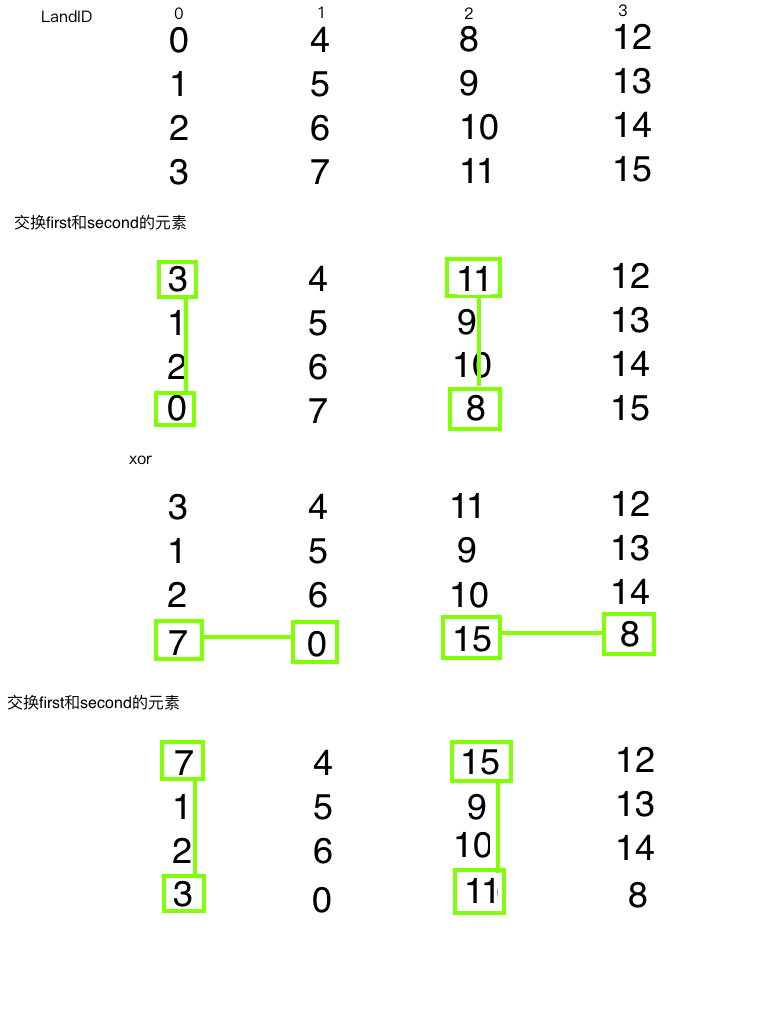
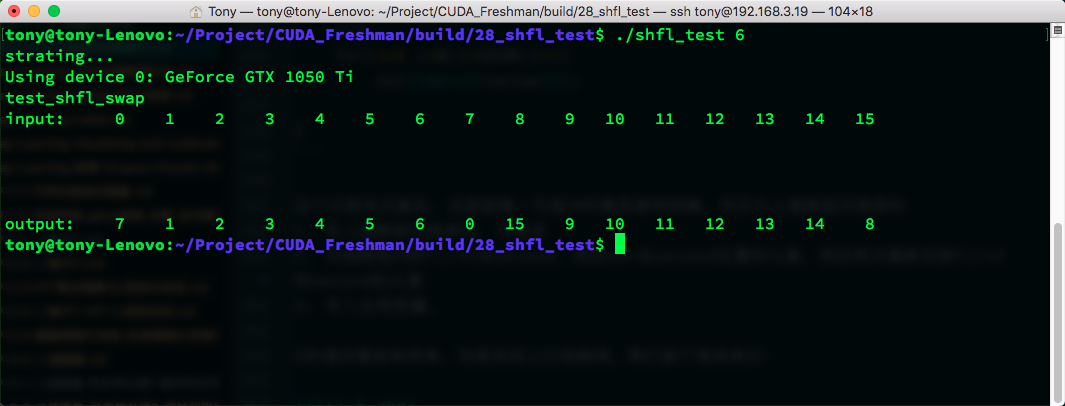
Referencing the code, green lines trace each transformation step. This should be understandable. Result:
Parallel Reduction Using Warp Shuffle Instructions
We have already introduced reduction algorithms in great detail -- from inter-block to intra-thread reduction, including shared memory and various unrolling methods. Today we use warp shuffle instructions to perform reduction, with the main goal of reducing data transfer latency between threads for faster efficiency.
We consider reduction at three levels:
- Warp-level reduction
- Block-level reduction
- Grid-level reduction
A thread block has multiple warps, each performing its own reduction. Each warp uses warp shuffle instructions instead of shared memory:
__inline__ __device__ int warpReduce(int localSum)
{
localSum += __shfl_xor(localSum, 16);
localSum += __shfl_xor(localSum, 8);
localSum += __shfl_xor(localSum, 4);
localSum += __shfl_xor(localSum, 2);
localSum += __shfl_xor(localSum, 1);
return localSum;
}
__global__ void reduceShfl(int * g_idata,int * g_odata,unsigned int n)
{
//set thread ID
__shared__ int smem[DIM];
unsigned int idx = blockDim.x*blockIdx.x+threadIdx.x;
//convert global data pointer to the
//1.
int mySum=g_idata[idx];
int laneIdx=threadIdx.x%warpSize;
int warpIdx=threadIdx.x/warpSize;
//2.
mySum=warpReduce(mySum);
//3.
if(laneIdx==0)
smem[warpIdx]=mySum;
__syncthreads();
//4.
mySum=(threadIdx.x<DIM)?smem[laneIdx]:0;
if(warpIdx==0)
mySum=warpReduce(mySum);
//5.
if(threadIdx.x==0)
g_odata[blockIdx.x]=mySum;
}
Code explanation:
- Read data from global memory and calculate the warp ID and current thread's lane ID.
- Compute the reduction result within the current warp using XOR. You need to manually compute the result of each thread with these powers of 2. Since each warp has only 32 threads, the highest binary bit is 16. XOR 16 computes 0+16, 1+17, 2+18, etc. After completion, the first 16 positions hold results, and positions 16-31 are copies. XOR 8 computes 0+8, 1+9, 2+10, etc., with the first 8 positions holding valid results. The rest copies the preceding answers. Finally, we get the current warp's reduction result.
- Store the warp result in shared memory.
- Repeat the process from step 2 on the data from step 3, performing a complete repetition.
- Store the final result in global memory.
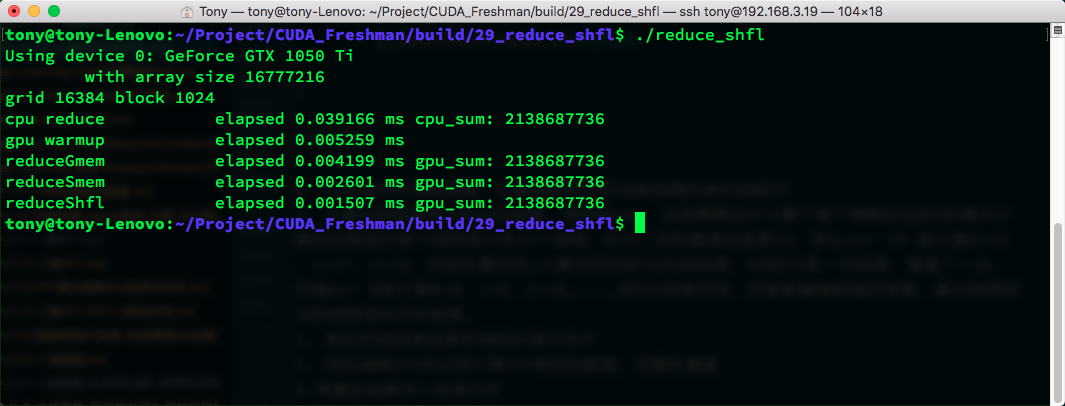
The other kernel functions have been introduced in previous articles. Through practice, we can see that reduction using warp shuffle instructions has the highest efficiency. The main reason is that data exchange uses registers without any memory involvement.
Complete code on GitHub: https://github.com/Tony-Tan/CUDA_Freshman (Stars are welcome!)
Summary
This article introduced some uses of warp shuffle instructions. Their appeal lies in not requiring memory for inter-thread data exchange, providing very high performance.
This completes our study of Chapter 5. Next, we enter the study of streams and events.