5.4 Coalesced Global Memory Access
Published on 2018-06-04 | Category: CUDA , Freshman | Comments: 0 | Views:
Abstract: This article introduces using shared memory for matrix transposition to reduce interleaved memory access.
Keywords: Coalesced Access, Transposition
Coalesced Global Memory Access
Remember our matrix transposition example from the global memory section: 4.4 Achievable Kernel Bandwidth
In Section 4.4, shared memory was the only tool available. To achieve maximum efficiency, we had to combine L1 and L2 caches in our programming to improve transposition efficiency. Since transposition can only choose between row-read/column-write or column-read/row-write, uncoalesced access is inevitable. Although we used L1 cache properties to improve performance, today we introduce our new tool -- shared memory. By completing the transposition in shared memory and then writing to global memory, we can avoid interleaved access.
Baseline Transposition Kernel
Before introducing our magical shared memory, it is best to first determine the limits of our problem. In other words, we need to clearly know our slowest case (the speed achievable with the simplest method) and the fastest theoretical speed. The theoretical speed may not be reachable but can be approached. The slowest speed can definitely be surpassed -- you can always write a slower program. So we use the simplest method as the lower bound, and reading by row then writing without transformation as the upper bound. We used this trick before in Section 4.4, where we actually broke through the limit (probably a timing issue). But normally, the limit is the best reference value.
Complete code on GitHub: https://github.com/Tony-Tan/CUDA_Freshman (Stars are welcome!)
Upper bound:
__global__ void copyRow(float * in,float * out,int nx,int ny)
{
int ix=threadIdx.x+blockDim.x*blockIdx.x;
int iy=threadIdx.y+blockDim.y*blockIdx.y;
int idx=ix+iy*nx;
if (ix<nx && iy<ny)
{
out[idx]=in[idx];
}
}
The lower bound is our "too young too naive" version -- the most conventional approach:
__global__ void transformNaiveRow(float * in,float * out,int nx,int ny)
{
int ix=threadIdx.x+blockDim.x*blockIdx.x;
int iy=threadIdx.y+blockDim.y*blockIdx.y;
int idx_row=ix+iy*nx;
int idx_col=ix*ny+iy;
if (ix<nx && iy<ny)
{
out[idx_col]=in[idx_row];
}
}
The first code snippet above does not actually perform transposition -- it is only for testing the upper bound. The second is the naive transposition discussed previously. Results:
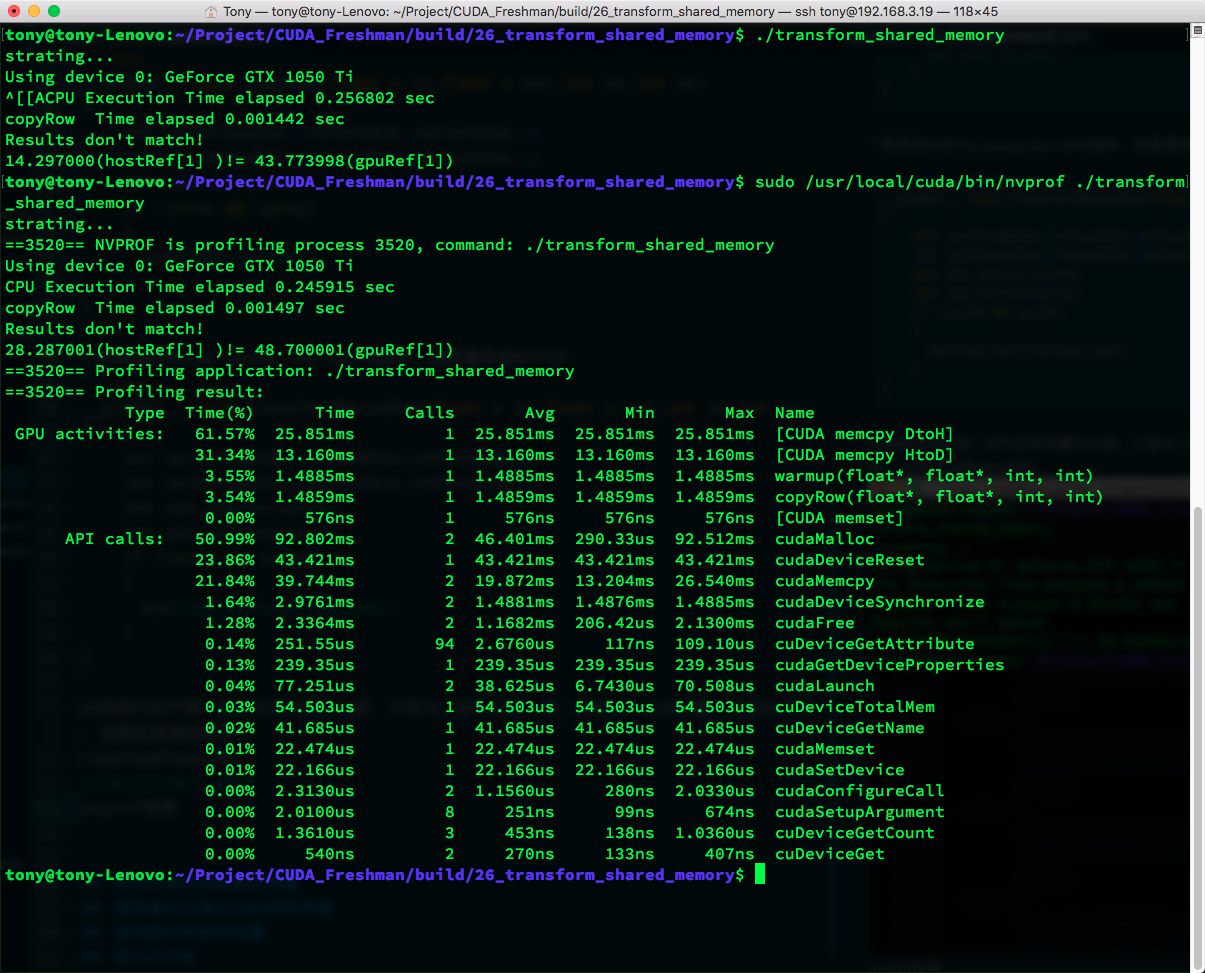
copyRow CPU timing and nvprof results:
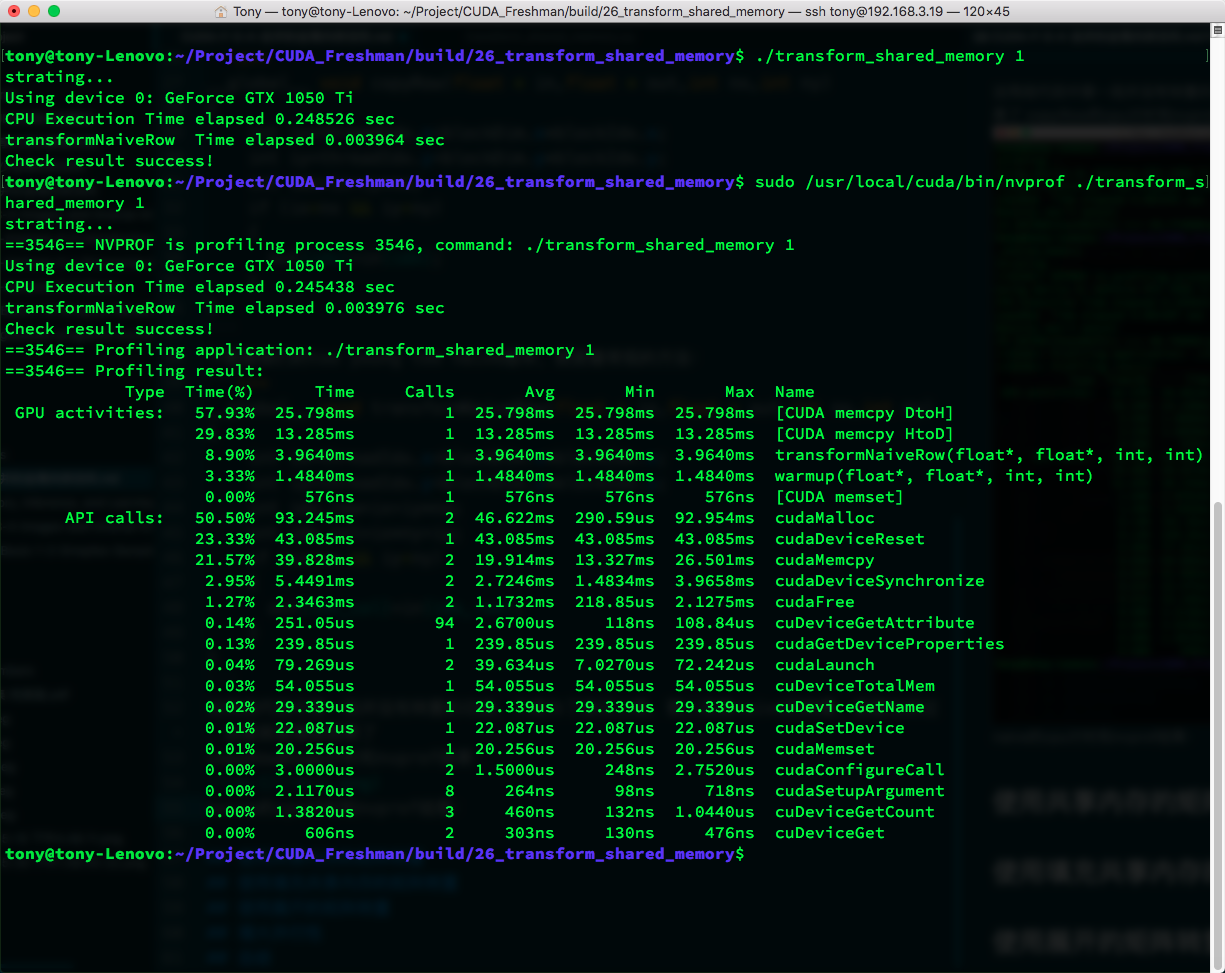
transformNaiveRow CPU timing and nvprof results:
We obtain the following table:
| Kernel | CPU Timing | nvprof Timing |
|---|---|---|
| copyRow | 0.001442 s | 1.4859 ms |
| transformNaiveRow | 0.003964 s | 3.9640 ms |
CPU timing is fairly accurate at larger data volumes. Our current matrix size is 2^12 x 2^12.
Next, the average number of transactions for global memory load and store requests (lower is better):
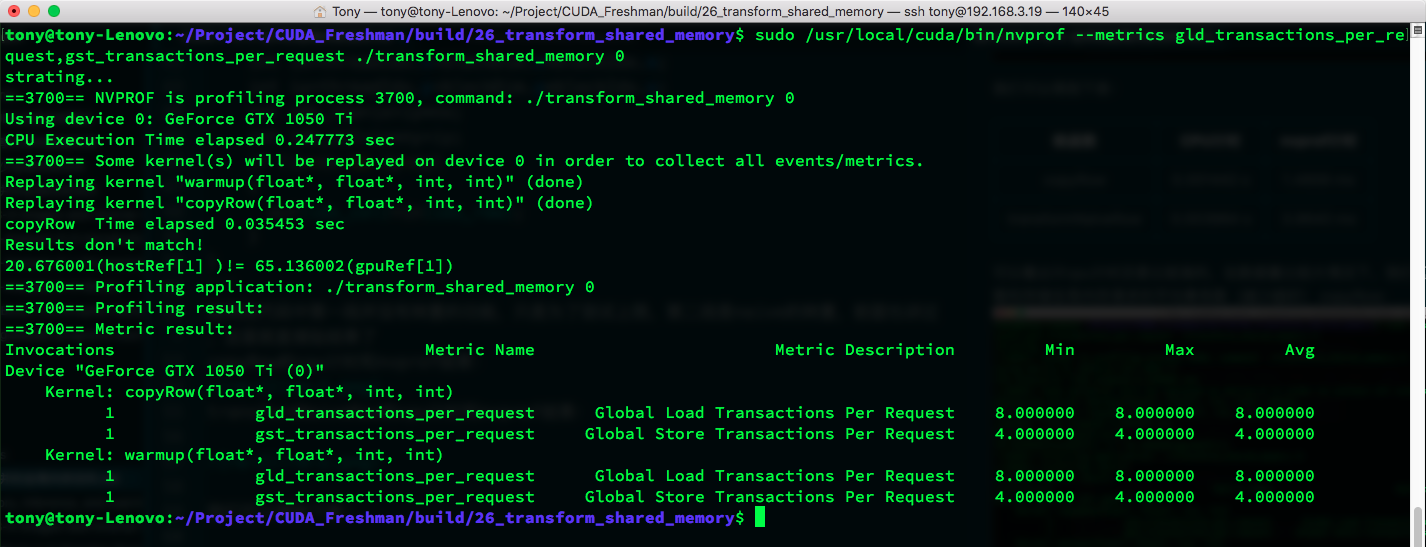
copyRow:
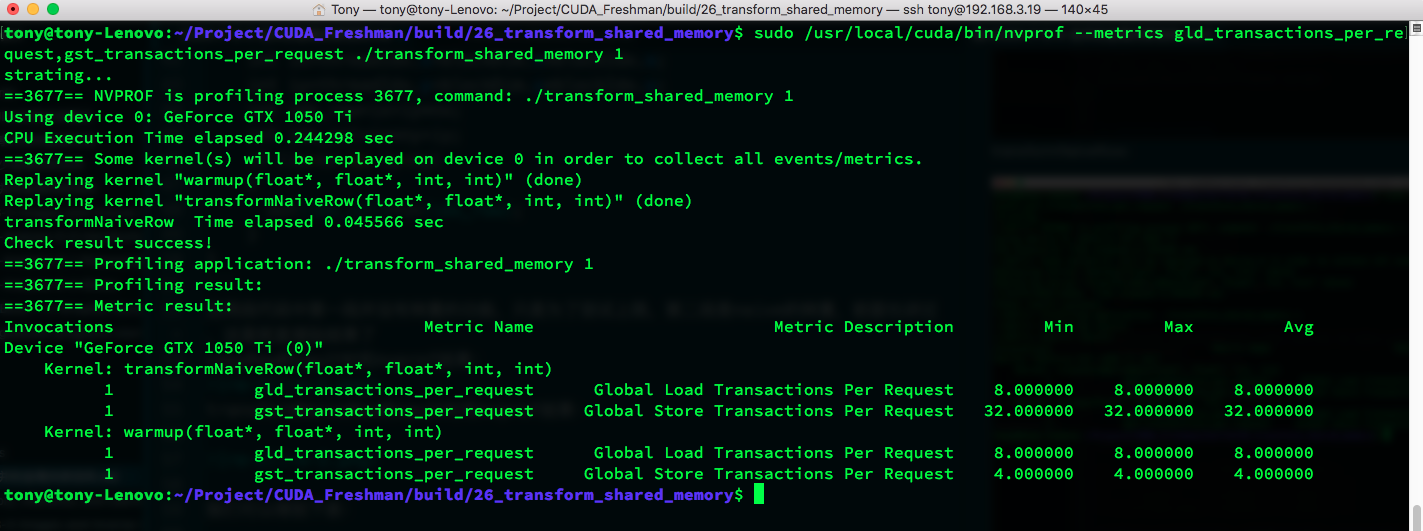
transformNaiveRow:
Now let's start using shared memory.
Matrix Transposition with Shared Memory
To avoid interleaved access, we can use 2D shared memory to cache the original matrix data, then read a column from shared memory and write it to a global memory row. Since reading columns from shared memory does not cause the severe latency of interleaved access, this approach can improve efficiency. However, as mentioned in the previous article, reading shared memory by column causes conflicts. So let's first use shared memory in the simplest way and test the performance improvement:
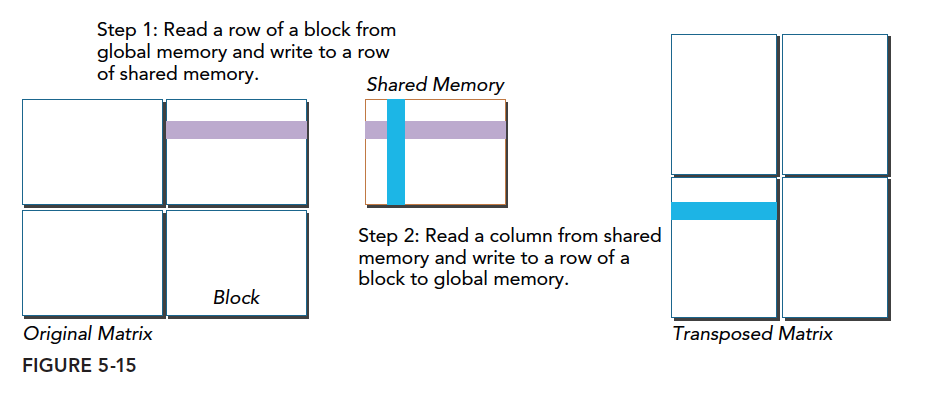
The diagram above shows our transposition process:
- Read data from global memory (by row) and write to shared memory (by row)
- Read a column from shared memory and write to a global memory row
From a serial perspective: we have a 2D matrix stored one-dimensionally in memory. Typically, we place a 2D matrix row by row into 1D memory. The transposition process can be understood as changing data from row-by-row (top to bottom) to column-by-column (left to right).
Since the process is simple, let's look directly at the code. We can use either square or rectangular shared memory; here we use rectangular shared memory for generality.
__global__ void transformSmem(float * in,float* out,int nx,int ny)
{
__shared__ float tile[BDIMY][BDIMX];
unsigned int ix,iy,transform_in_idx,transform_out_idx;
// 1
ix=threadIdx.x+blockDim.x*blockIdx.x;
iy=threadIdx.y+blockDim.y*blockIdx.y;
transform_in_idx=iy*nx+ix;
// 2
unsigned int bidx,irow,icol;
bidx=threadIdx.y*blockDim.x+threadIdx.x;
irow=bidx/blockDim.y;
icol=bidx%blockDim.y;
// 3
ix=blockIdx.y*blockDim.y+icol;
iy=blockIdx.x*blockDim.x+irow;
// 4
transform_out_idx=iy*ny+ix;
if(ix<nx&& iy<ny)
{
tile[threadIdx.y][threadIdx.x]=in[transform_in_idx];
__syncthreads();
out[transform_out_idx]=tile[icol][irow];
}
}
With the diagram below, let's trace through the code:
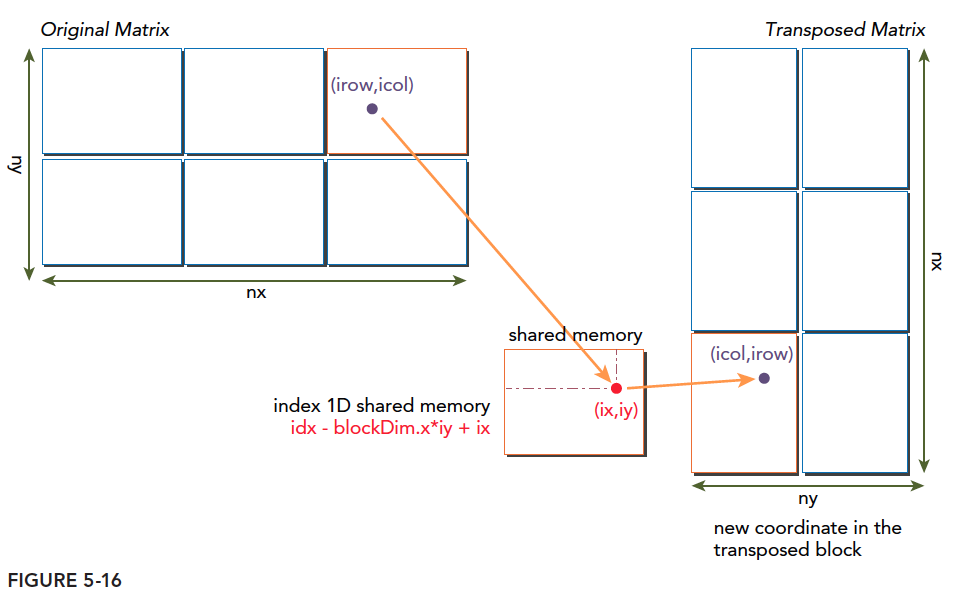
Code explanation (this is general-purpose code, not requiring the matrix to be square. Combining with the diagram above makes the process clearer):
- Calculate the global coordinates of threads in the current block (relative to the entire grid), and the corresponding 1D linear memory position.
- bidx represents the block index -- the linear position of the thread's coordinates within the block (converting 2D thread positions to 1D using row-by-row layout). Then perform the transposition -- change to column-by-column layout and calculate new 2D coordinates. The mapping from row-by-row to column-by-column is the transposition mapping. This only completes one block among many. The key is where to place it back.
- Calculate the target 2D global thread coordinates after transposition. Note that the pre-transposition row position becomes the post-transposition column position. This is the second step of transposition.
- Calculate the 1D global memory position corresponding to the post-transposition 2D coordinates.
- Read from global memory, write to shared memory, then write to the transposed position.
The above 5 processes can be understood as two steps:
- Transpose the matrix within shared memory. If you naively allocate two shared memory blocks and transpose between them, that is silly. It is also not recommended to read global memory by row and write by column (that was my initial idea). Instead, establish a transposition mapping to complete one block of the block-wise transposition.
- Find the new location of the transposed block and write it to global memory.
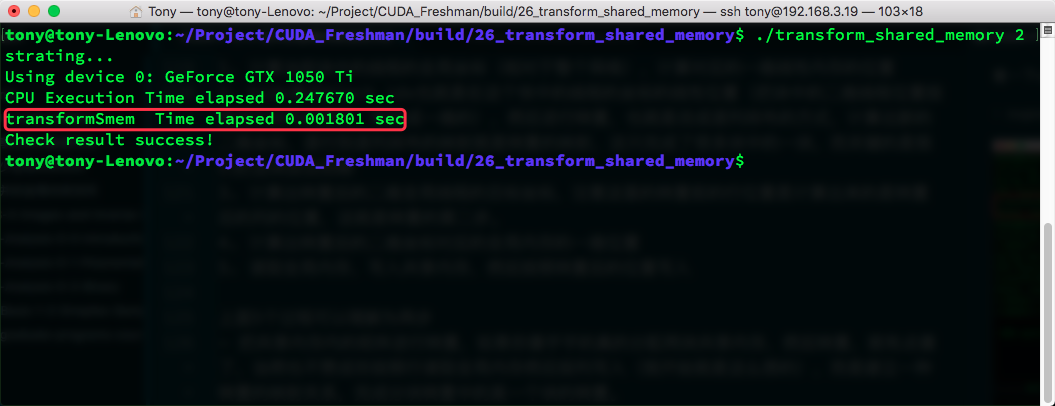
CPU timing:
nvprof results:
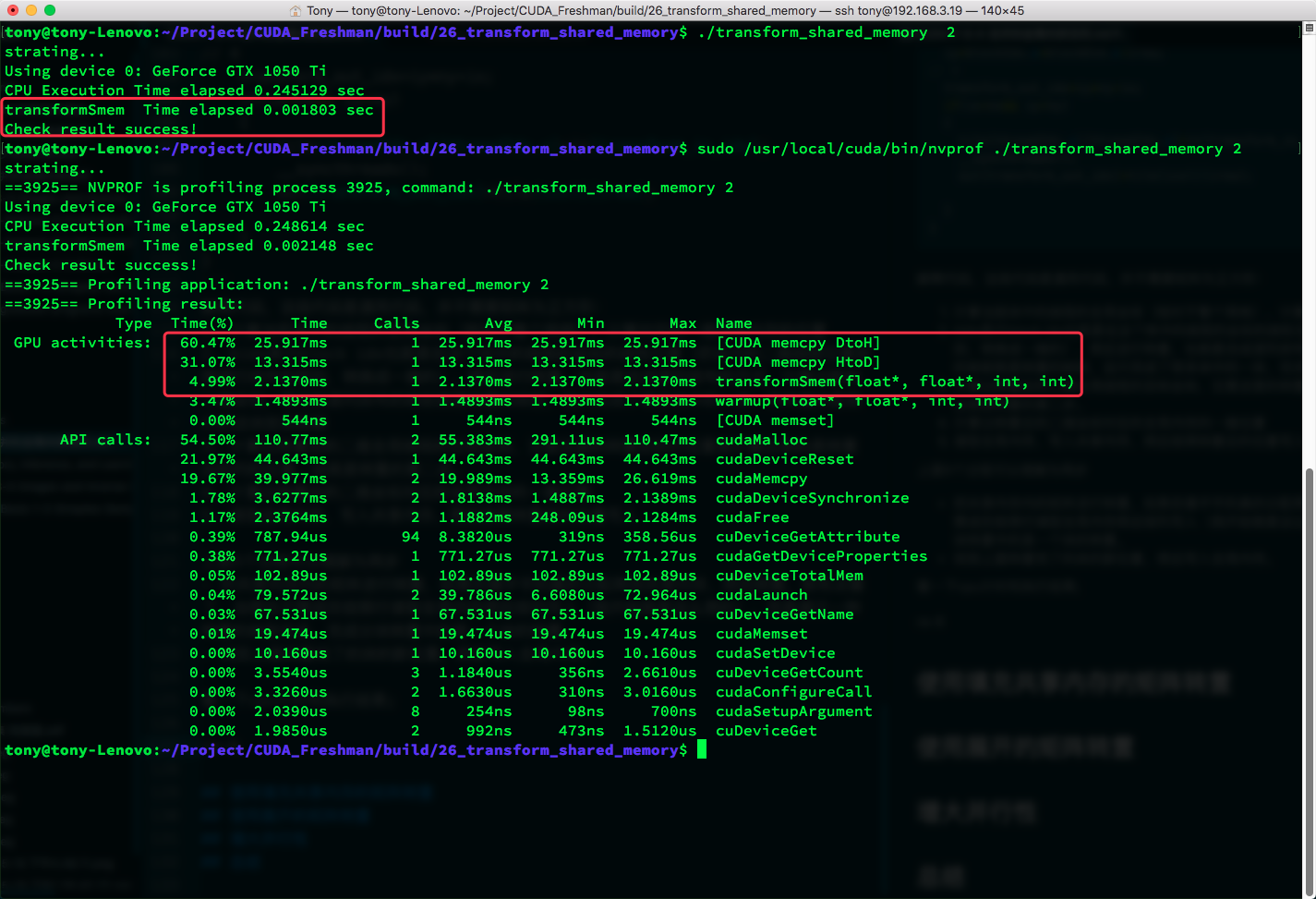
From 0.003964s to 0.001803s -- not bad. Speed doubled.
Average memory transactions:
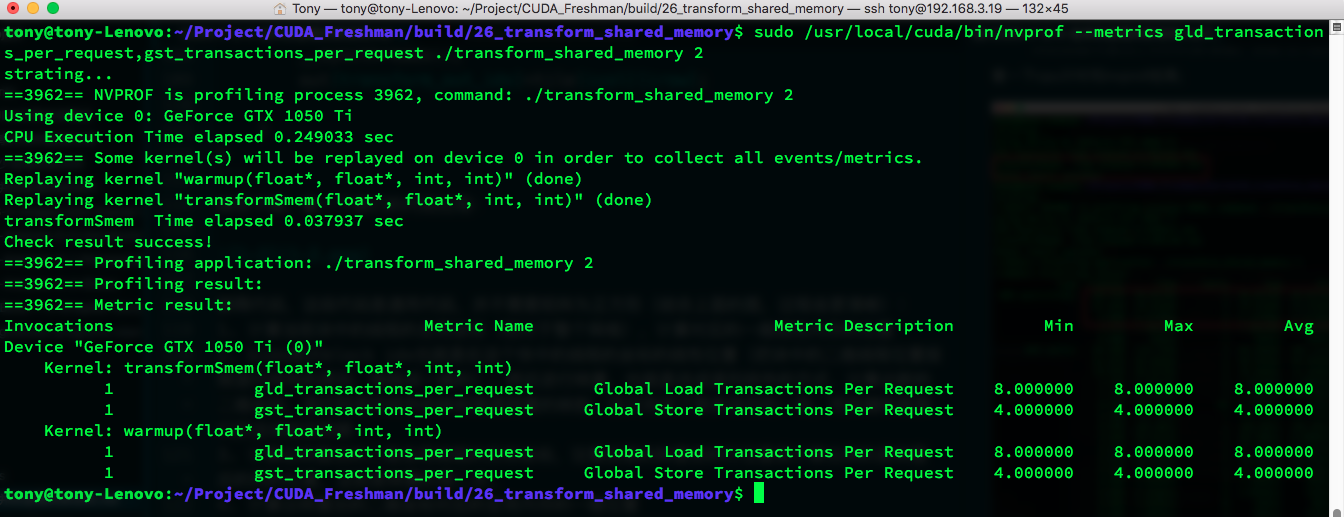
Store transactions decreased from 32 to 4 -- quite significant. Let's check shared memory transactions to see if there are conflicts:
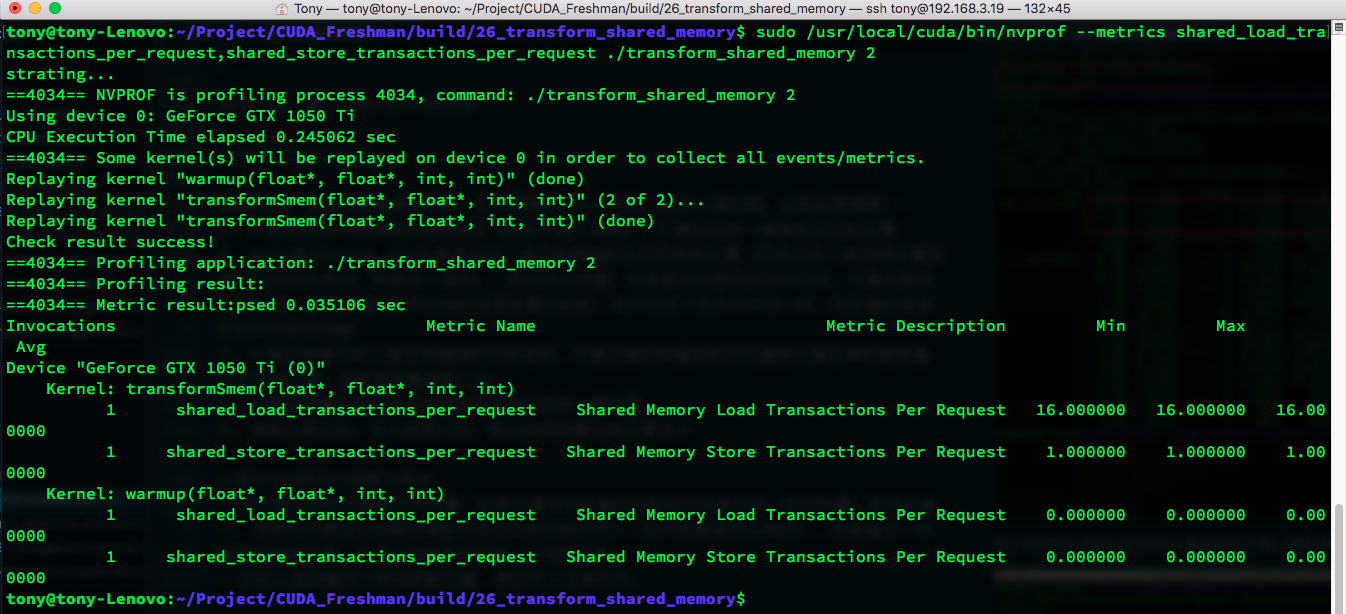
Unsurprisingly, 16-way conflict. No conflict for stores -- the conflict comes mainly from loads. The only way to solve this is padding.
Matrix Transposition with Padded Shared Memory
The best way to resolve shared memory conflicts is padding. Let's pad our shared memory:
__global__ void transformSmemPad(float * in,float* out,int nx,int ny)
{
__shared__ float tile[BDIMY][BDIMX+IPAD];
unsigned int ix,iy,transform_in_idx,transform_out_idx;
ix=threadIdx.x+blockDim.x*blockIdx.x;
iy=threadIdx.y+blockDim.y*blockIdx.y;
transform_in_idx=iy*nx+ix;
unsigned int bidx,irow,icol;
bidx=threadIdx.y*blockDim.x+threadIdx.x;
irow=bidx/blockDim.y;
icol=bidx%blockDim.y;
ix=blockIdx.y*blockDim.y+icol;
iy=blockIdx.x*blockDim.x+irow;
transform_out_idx=iy*ny+ix;
if(ix<nx&& iy<ny)
{
tile[threadIdx.y][threadIdx.x]=in[transform_in_idx];
__syncthreads();
out[transform_out_idx]=tile[icol][irow];
}
}
The only difference is IPAD. Let's focus on the metrics:
Result:
Execution time decreased from 0.0018 to 0.0015.
nvprof result:
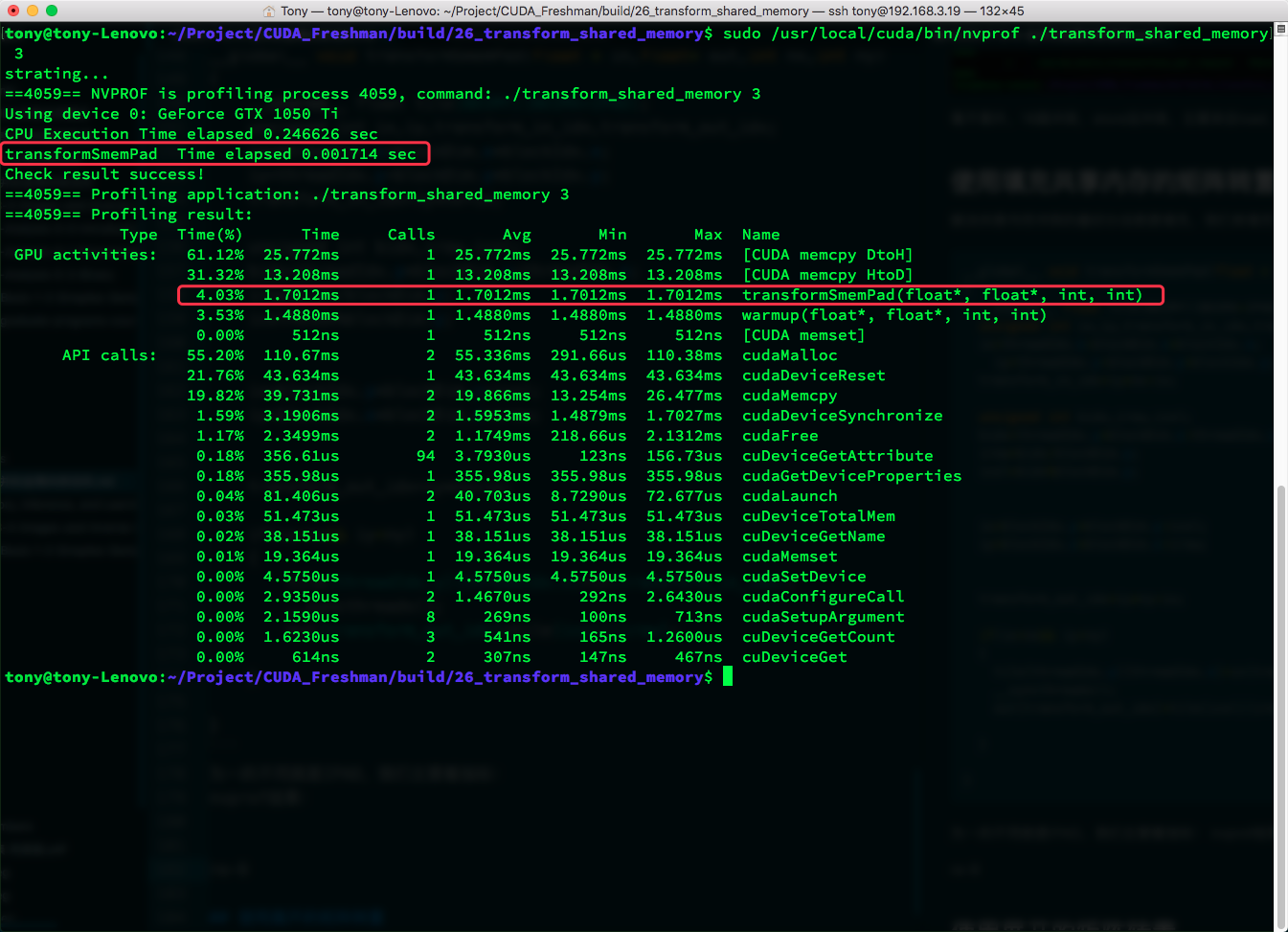
We focus on shared memory transactions. Global transactions did not change.
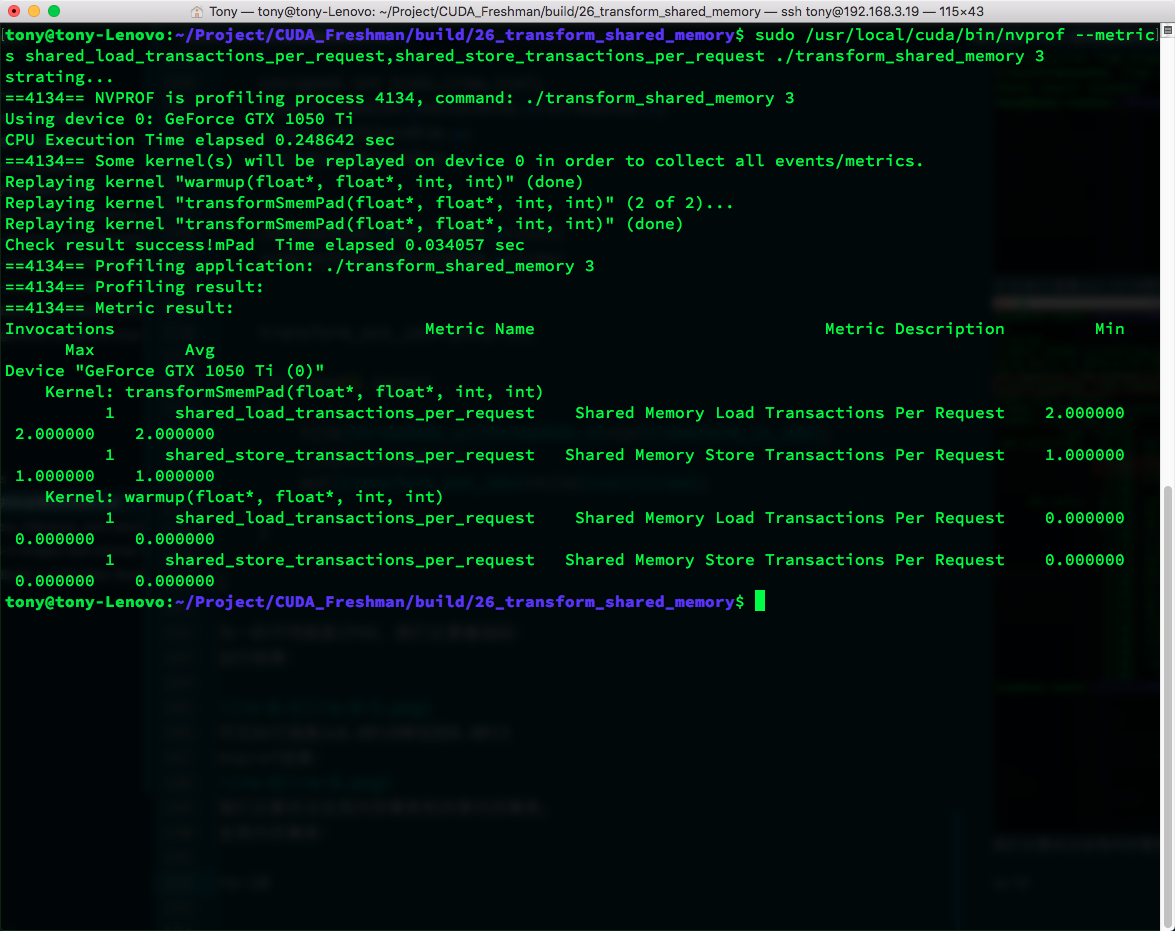
There are still conflicts. Let's try changing IPAD (from 1 to 2):
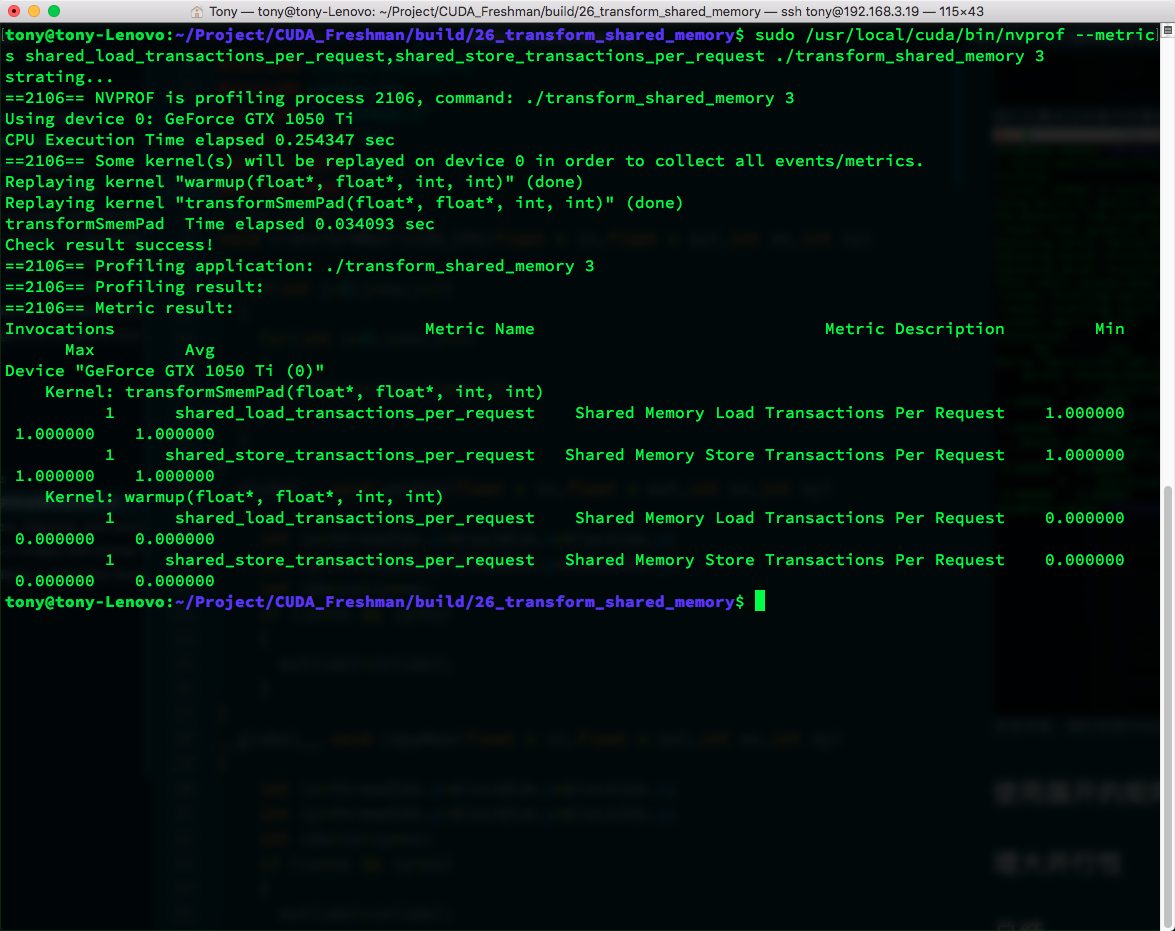
The conflict is gone! CPU timing:

Conflicts resolved, but speed did not significantly improve.
Matrix Transposition with Unrolling
After padding shared memory to eliminate conflicts, we want to further improve performance. Let's use another powerful tool mentioned earlier -- loop unrolling, which saves many thread blocks and improves bandwidth utilization:
Code first, then explanation:
__global__ void transformSmemUnrollPad(float * in,float* out,int nx,int ny)
{
__shared__ float tile[BDIMY*(BDIMX*2+IPAD)];
//1.
unsigned int ix,iy,transform_in_idx,transform_out_idx;
ix=threadIdx.x+blockDim.x*blockIdx.x*2;
iy=threadIdx.y+blockDim.y*blockIdx.y;
transform_in_idx=iy*nx+ix;
//2.
unsigned int bidx,irow,icol;
bidx=threadIdx.y*blockDim.x+threadIdx.x;
irow=bidx/blockDim.y;
icol=bidx%blockDim.y;
//3.
unsigned int ix2=blockIdx.y*blockDim.y+icol;
unsigned int iy2=blockIdx.x*blockDim.x*2+irow;
//4.
transform_out_idx=iy2*ny+ix2;
if(ix+blockDim.x<nx&& iy<ny)
{
unsigned int row_idx=threadIdx.y*(blockDim.x*2+IPAD)+threadIdx.x;
tile[row_idx]=in[transform_in_idx];
tile[row_idx+BDIMX]=in[transform_in_idx+BDIMX];
//5
__syncthreads();
unsigned int col_idx=icol*(blockDim.x*2+IPAD)+irow;
out[transform_out_idx]=tile[col_idx];
out[transform_out_idx+ny*BDIMX]=tile[col_idx+BDIMX];
}
}
Yes, one thread does the work of two, or one block does the work of two blocks. Combined with the detailed shared memory transposition explanation above, this is easy to understand. But let me write it out again to avoid omissions or unclear explanations.
Of course, a diagram makes it clearer. Note the comparison with the code above:
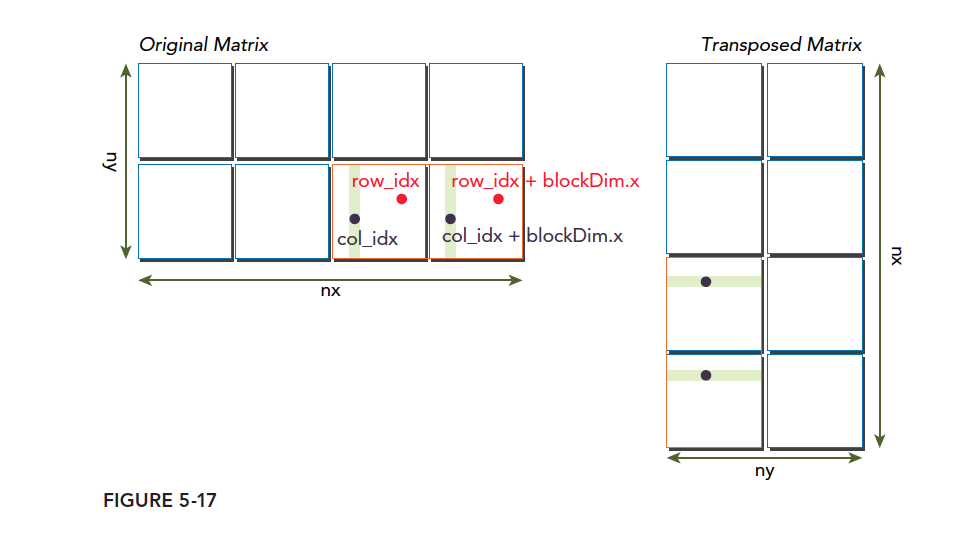
- Calculate the global coordinates of threads in the current block -- 1D linear memory position.
- Perform transposition within shared memory.
- Calculate the post-transposition 2D global thread target coordinates. Note that the pre-transposition row position becomes the post-transposition column position -- the second step of transposition.
- Calculate the 1D global memory position corresponding to the post-transposition 2D coordinates. Note this does not calculate one block at a time, but two blocks. Alternatively, think of it as doubling the original block in the x-direction, then splitting the large block into two small blocks (A, B), where corresponding positions differ by BDIMX. Data in A and B is written to shared memory row by row.
- Write data read into shared memory in step 4 to global memory at the transposed position.
This process looks simple but is a bit tricky to write. The key technique is drawing a diagram -- once you do, it becomes clear.
nvprof results and global memory transactions:
nvprof:
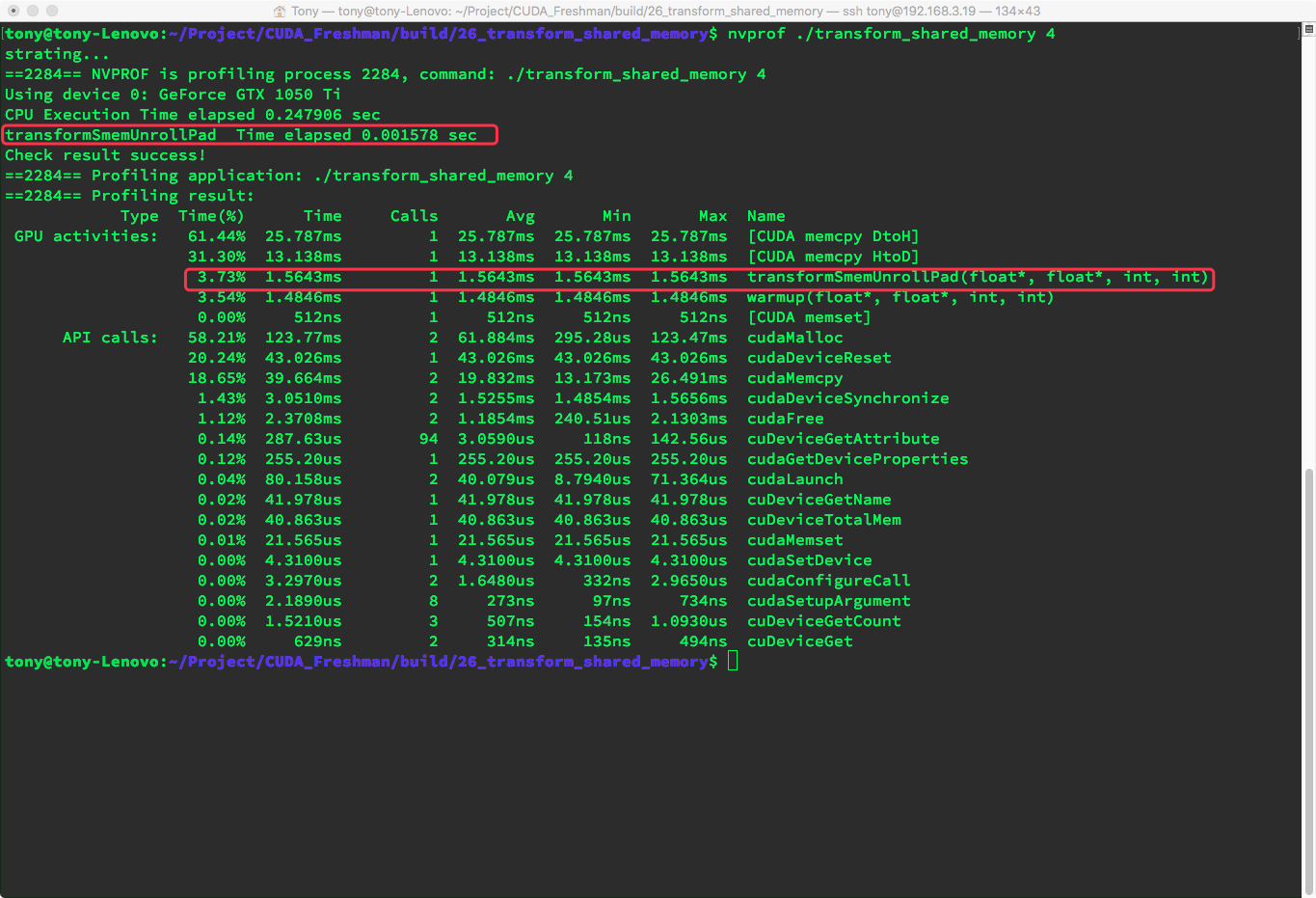
Global memory transactions:
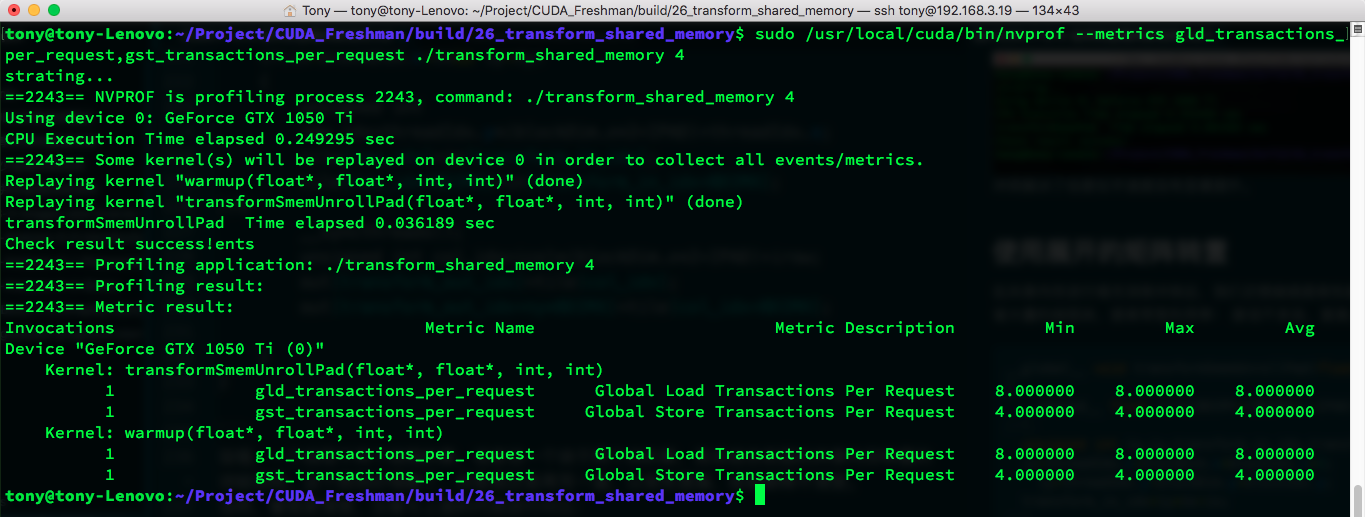
In our current environment, unrolling did not speed things up. We could try unrolling more, but we will not experiment further here.
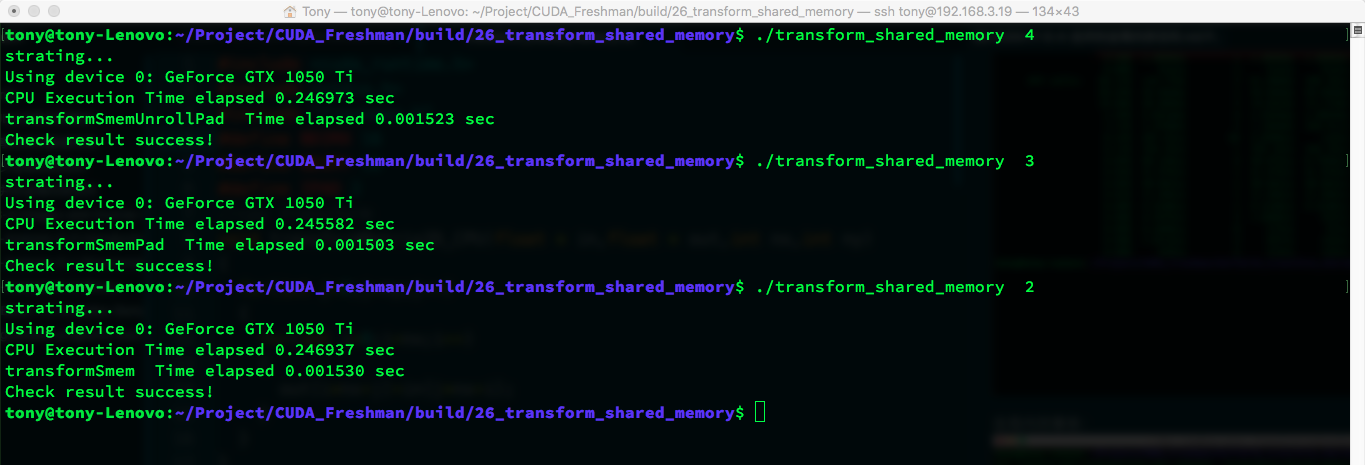
Increasing Parallelism
Increasing parallelism is achieved by adjusting kernel configuration. Adjusting to 16 x 16 blocks:
Adjusting to 8 x 8 blocks:
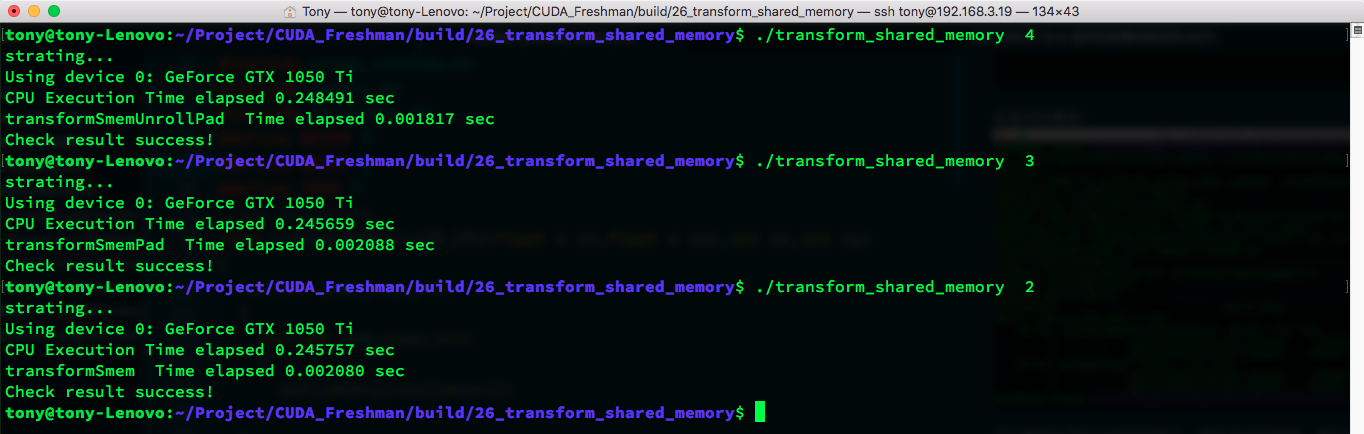
This requires continuous experimentation to find the optimal configuration for your device.
Summary
This article used shared memory to avoid interleaved global memory access, optimizing the speed of matrix transposition.