5.5 Constant Memory
Published on 2018-06-06 | Category: CUDA , Freshman | Comments: 0 | Views:
Abstract: This article introduces two other types of memory -- constant memory and read-only cache.
Keywords: CUDA Constant Memory, CUDA Read-Only Cache
Constant Memory
Constant Memory
This article introduces constant memory and read-only cache. Constant memory is specialized memory used for read-only data and warp-uniform access to a single data value. Constant memory is read-only for kernel code, but the host can modify (write) and also read constant memory.
Note that constant memory is not on-chip -- it resides in DRAM. However, it has a corresponding on-chip cache. Its on-chip cache, like the L1 cache and shared memory, has low latency but limited capacity. Proper use can improve kernel efficiency. Each SM's constant cache is limited to 64KB.
We can observe that for all on-chip memory, we cannot assign values from the host -- we can only assign values to DRAM-resident memory.
Every memory access type has optimal and worst-case access patterns, primarily due to hardware structure and underlying design. For example, global memory is optimal with contiguous aligned access and worst with interleaved access. Shared memory is optimal with no conflicts and worst with all conflicts. The fundamental reason lies in hardware design. For constant memory, the optimal access pattern is when all threads in a warp access the same location. If different locations need to be accessed, it becomes serial. Comparatively, this situation is equivalent to completely non-contiguous global memory access or all-conflict shared memory access.
Mathematically, the cost of a constant memory read is linearly related to the number of distinct constant memory addresses read by threads in a warp.
Constant memory is declared with:
__constant__
Constant memory variables have the same lifetime as the application. All grids can access declared constant memory, and it is visible to the host at runtime. When CUDA separate compilation is used, constant memory is visible across files (this will be covered later).
Constant memory is initialized using:
cudaError_t cudaMemcpyToSymbol(const void *symbol, const void * src, size_t count, size_t offset, cudaMemcpyKind kind)
Similar to the copy-to-global-memory function we used before, with similar parameters, including transfer to device and read from device. The default kind parameter is transfer to device.
Implementing a 1D Stencil with Constant Memory
Stencil operations are commonly used in numerical analysis. Well, we haven't taken that class yet, but another term you are surely familiar with is "convolution." A 1D convolution is exactly the example we will write today. A stencil operation takes several consecutive elements from the middle of a data set and produces one output:
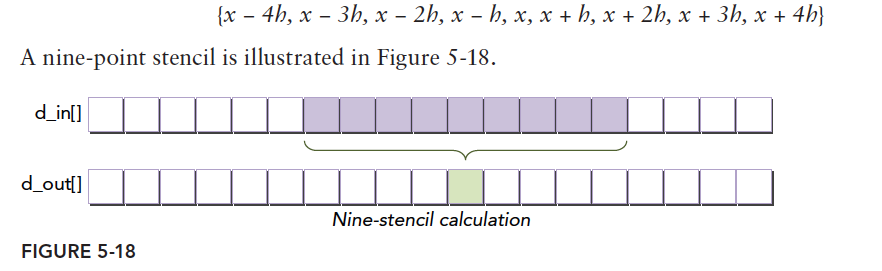
Purple input data goes through some computation to produce an output -- the green block. This is very useful in image processing. Of course, images use 2D data. Let's look at the formula:
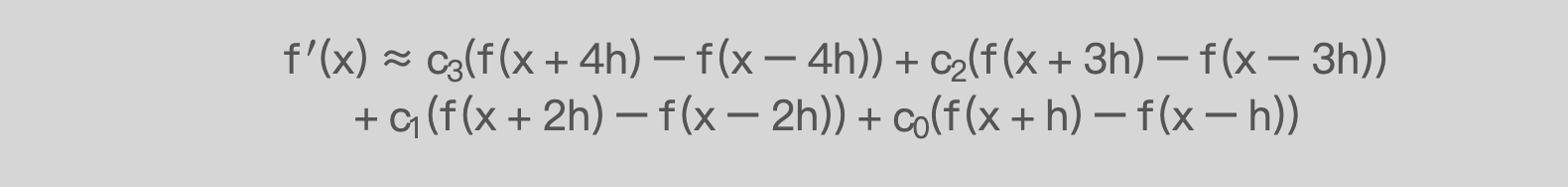
This formula computes the derivative of a function using an 8th-order difference approximation.
Note: the parameters here differ from those in the book -- coefficient c0 here corresponds to c3 in the original.
Analyzing the algorithm: the coefficients ci, 0 < i < 4 are used by all threads. For a fixed computation, we can declare them in registers. But if the count is large or not specific to a particular set of c values, they need to be passed dynamically. In this case, constant memory is the best choice because of its read-only property for kernel functions and broadcast access within a warp -- 32 threads can complete the read with just one memory transaction, which is very efficient.
Looking at the image above, each input data is used 8 times. If read from global memory each time, the latency is too high. Combining with the shared memory discussed in the previous article, we cache input data in shared memory to obtain the following code:
__global__ void stencil_1d(float * in,float * out)
{
//1.
__shared__ float smem[BDIM+2*TEMP_RADIO_SIZE];
//2.
int idx=threadIdx.x+blockDim.x*blockIdx.x;
//3.
int sidx=threadIdx.x+TEMP_RADIO_SIZE;
smem[sidx]=in[idx];
//4.
if (threadIdx.x<TEMP_RADIO_SIZE)
{
if(idx>TEMP_RADIO_SIZE)
smem[sidx-TEMP_RADIO_SIZE]=in[idx-TEMP_RADIO_SIZE];
if(idx<gridDim.x*blockDim.x-BDIM)
smem[sidx+BDIM]=in[idx+BDIM];
}
__syncthreads();
//5.
if (idx<TEMP_RADIO_SIZE||idx>=gridDim.x*blockDim.x-TEMP_RADIO_SIZE)
return;
float temp=.0f;
//6.
#pragma unroll
for(int i=1;i<=TEMP_RADIO_SIZE;i++)
{
temp+=coef[i-1]*(smem[sidx+i]-smem[sidx-i]);
}
out[idx]=temp;
//printf("%d:GPU :%lf,\n",idx,temp);
}
Complete code on GitHub: https://github.com/Tony-Tan/CUDA_Freshman (Stars are welcome!)
Here we face a padding problem. Whether examining the formula or the diagram, we find that if the stencil size is 9, the first 4 output values cannot be computed because they require data at positions -1, -2, -3, -4. The last 4 values also cannot be computed because they require data at positions n+1, n+2, n+3, n+4, which do not exist. To ensure no out-of-bounds access during computation, we extend both ends of the input data -- padding with data that does not exist but is needed. When processing a middle segment of data, the padding data comes from input data corresponding to previous or subsequent thread blocks. This is the most difficult part of the code -- once understood, everything else is smooth sailing.
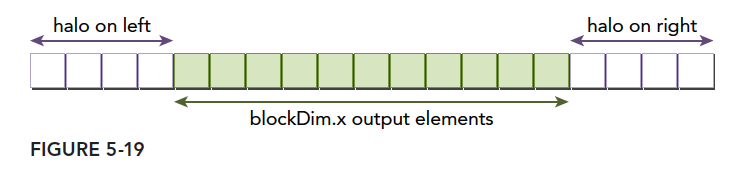
- Define shared memory, noting it is padded -- hence the addition of two stencil radii.
- Calculate global thread index.
- Calculate the current thread's corresponding position in padded shared memory. Since the first TEMP_RADIO_SIZE data are padding, we operate starting from position TEMP_RADIO_SIZE.
- Determine if the current block's corresponding input data is the first or last block (no preceding or following data available for padding). For middle blocks, read data from corresponding positions for padding.
- Determine if we are at the beginning or end positions where output cannot be computed.
- Perform the difference, using a pragma directive to let the compiler unroll the loop.
The difficulty is in step 4 -- mainly the padding. If we treat the input data as a whole and use a serial approach, we could skip padding and simply invalidate the first or last few output values. But when processing input data in blocks, it involves reading from neighboring global memory positions and checking for out-of-bounds access.
Comparison with Read-Only Cache
The above covers constant memory and constant cache operations. As a comparison, let's show the corresponding read-only cache operations. The read-only cache has dedicated bandwidth for reading data from global memory. If a kernel function is bandwidth-limited, this help is significant. Different devices have different read-only cache sizes. Kepler SM has 48KB of read-only cache. The read-only cache is better for scattered access. When all threads read the same address, the constant cache performs best, while the read-only cache does not perform as well. Read-only cache granularity is 32 bytes.
There are two methods to use the read-only cache:
- Using the __ldg function
- Using a restricted pointer on global memory
Using __ldg():
__global__ void kernel(float* output, float* input) {
...
output[idx] += __ldg(&input[idx]);
...
}
Using a restricted pointer:
void kernel(float* output, const float* __restrict__ input) {
...
output[idx] += input[idx];
}
Using the read-only cache requires more declarations and control. In code so complex that the compiler cannot guarantee the safety of read-only cache usage, it is recommended to use the __ldg() function, which is easier to control.
The read-only cache exists independently, distinct from the constant cache. The constant cache prefers small data, while the read-only cache loads larger data and can be accessed in non-uniform patterns. Modifying the above code to create a read-only cache version:
__global__ void stencil_1d_readonly(float * in,float * out,const float* __restrict__ dcoef)
{
__shared__ float smem[BDIM+2*TEMP_RADIO_SIZE];
int idx=threadIdx.x+blockDim.x*blockIdx.x;
int sidx=threadIdx.x+TEMP_RADIO_SIZE;
smem[sidx]=in[idx];
if (threadIdx.x<TEMP_RADIO_SIZE)
{
if(idx>TEMP_RADIO_SIZE)
smem[sidx-TEMP_RADIO_SIZE]=in[idx-TEMP_RADIO_SIZE];
if(idx<gridDim.x*blockDim.x-BDIM)
smem[sidx+BDIM]=in[idx+BDIM];
}
__syncthreads();
if (idx<TEMP_RADIO_SIZE||idx>=gridDim.x*blockDim.x-TEMP_RADIO_SIZE)
return;
float temp=.0f;
#pragma unroll
for(int i=1;i<=TEMP_RADIO_SIZE;i++)
{
temp+=dcoef[i-1]*(smem[sidx+i]-smem[sidx-i]);
}
out[idx]=temp;
//printf("%d:GPU :%lf,\n",idx,temp);
}
The only difference is an additional parameter, which is defined as global memory on the host:
float * dcoef_ro;
CHECK(cudaMalloc((void**)&dcoef_ro,TEMP_RADIO_SIZE * sizeof(float)));
CHECK(cudaMemcpy(dcoef_ro,templ_,TEMP_RADIO_SIZE * sizeof(float),cudaMemcpyHostToDevice));
stencil_1d_readonly<<<grid,block>>>(in_dev,out_dev,dcoef_ro);
CHECK(cudaDeviceSynchronize());
iElaps=cpuSecond()-iStart;
printf("stencil_1d_readonly Time elapsed %f sec\n",iElaps);
CHECK(cudaMemcpy(out_gpu,out_dev,nBytes,cudaMemcpyDeviceToHost));
checkResult(out_cpu,out_gpu,nxy);
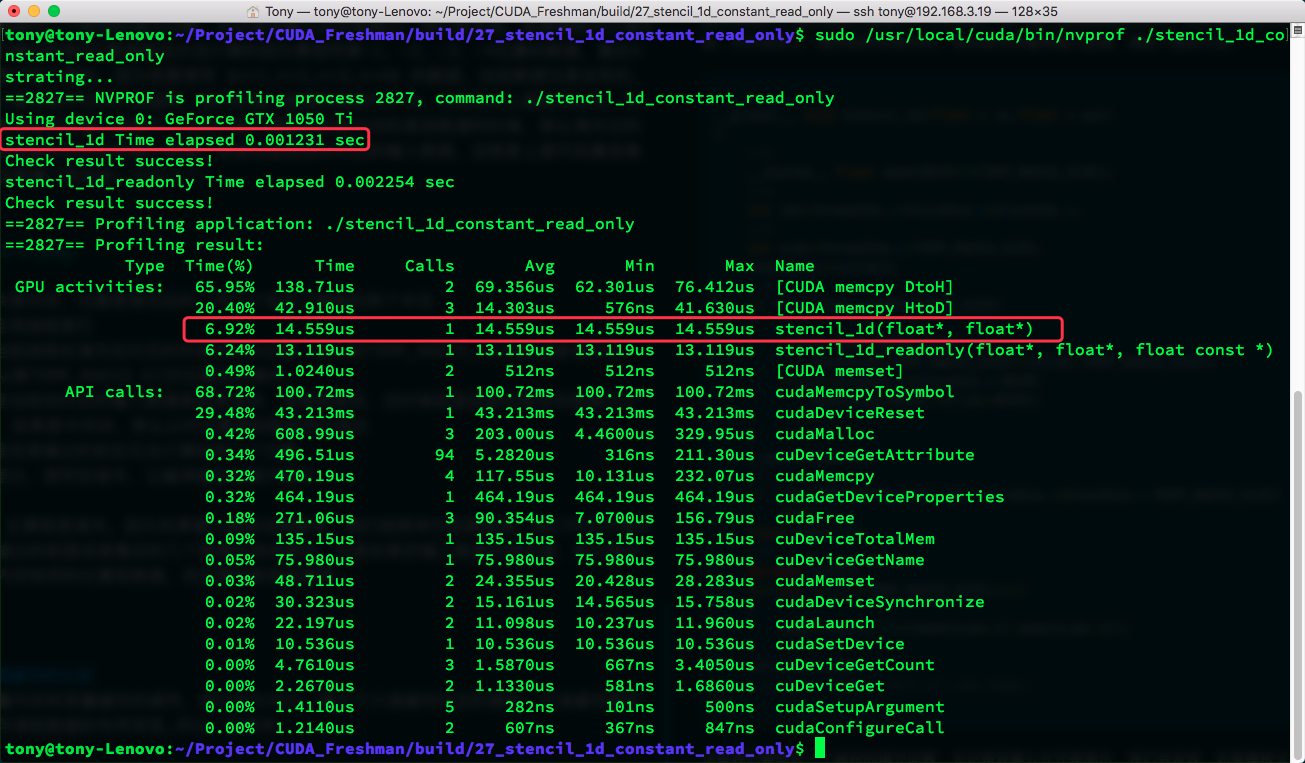
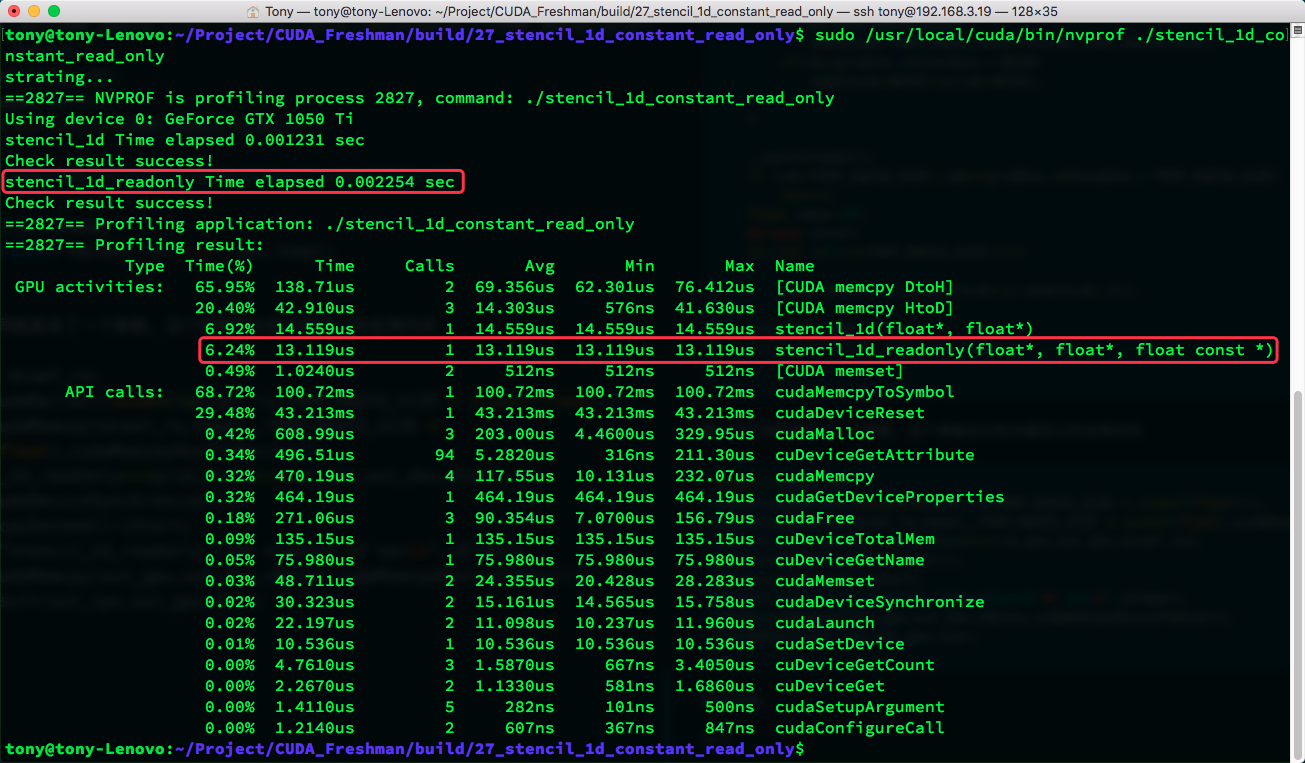
Result:
Summary
Constant memory and read-only cache:
- Both are read-only for kernel functions
- SM resources are limited: constant cache 64KB, read-only cache 48KB
- Constant cache performs better for uniform access (reading the same address)
- Read-only cache is suitable for scattered access