3.5 Loop Unrolling
Abstract: This article introduces loop unrolling techniques, continuing to accelerate on top of reduction.
Keywords: Unrolled Reduction, Reduction, Template Function
Loop Unrolling
Today we're doing loop unrolling. GPUs like deterministic things. As explained in the earlier execution model and warp sections, GPUs have no branch prediction capability, so every branch must be executed. So try not to write branches in kernels. What counts as a branch? if statements, of course, and also for loops and similar loop statements.
If you don't understand why for counts as a branch statement, here's a simple (if unrunnable) example:
for (int i = 0; i < tid; i++)
{
// to do something
}
If this code appears in a kernel, it creates branching. Because within a warp, the first and last threads' tid values differ by 32 (if warp size is 32). Each thread completes a different amount of computation when the for loop terminates, meaning some must wait -- and that creates branching.
Loop unrolling is a technique that attempts to optimize loops by reducing the frequency of branches and loop maintenance instructions.
The above is the book's official statement. Let's look at examples. Not only can parallel algorithms be unrolled -- traditional serial code can also see some efficiency improvement after unrolling, by eliminating the delays caused by condition evaluation and branch prediction failures.
Let's start with a C++ introductory loop:
for (int i = 0; i < 100; i++)
{
a[i] = b[i] + c[i];
}
This is the most traditional writing style, seen in every C++ textbook. No explanation needed. What if we unroll the loop?
for (int i = 0; i < 100; i += 4)
{
a[i+0] = b[i+0] + c[i+0];
a[i+1] = b[i+1] + c[i+1];
a[i+2] = b[i+2] + c[i+2];
a[i+3] = b[i+3] + c[i+3];
}
Yes, it's that simple. We modify the loop body by listing out what the loop was doing automatically. The benefit from a serial perspective is reducing the number of condition evaluations.
But if you run this code on a machine, you won't see much difference. Modern compilers compile both of these different styles into similar machine code. In other words, even if we don't unroll the loop, the compiler does it for us.
However, it's worth noting: the CUDA compiler cannot yet perform this optimization for us. Manually unrolling loops inside kernel functions can dramatically improve kernel performance.
The purposes of loop unrolling in CUDA remain the same two:
- Reduce instruction overhead
- Add more independently schedulable instructions
to improve performance.
Instructions like:
a[i+0] = b[i+0] + c[i+0];
a[i+1] = b[i+1] + c[i+1];
a[i+2] = b[i+2] + c[i+2];
a[i+3] = b[i+3] + c[i+3];
are very welcome on the CUDA pipeline because they maximize instruction and memory bandwidth utilization.
Now let's continue mining performance from the reduction examples above to see if we can achieve even higher efficiency.
Unrolled Reduction
In the previous branch avoidance blog, our reduceInterleaved kernel function had each thread block processing only its corresponding portion of data. Our current idea is: can we have one thread block process multiple blocks of data? This is achievable. If before summing this data (since it's always one thread per data item), we have each thread perform one addition from another block -- essentially doing a vector addition first, then the reduction -- we'd complete what previously took half the computation with a single instruction. That's a very tempting cost-benefit ratio.
Here's the code:
__global__ void reduceUnroll2(int * g_idata, int * g_odata, unsigned int n)
{
//set thread ID
unsigned int tid = threadIdx.x;
unsigned int idx = blockDim.x * blockIdx.x * 2 + threadIdx.x;
//boundary check
if (tid >= n) return;
//convert global data pointer to the
int *idata = g_idata + blockIdx.x * blockDim.x * 2;
if(idx + blockDim.x < n)
{
g_idata[idx] += g_idata[idx + blockDim.x];
}
__syncthreads();
//in-place reduction in global memory
for (int stride = blockDim.x/2; stride > 0; stride >>= 1)
{
if (tid < stride)
{
idata[tid] += idata[tid + stride];
}
//synchronize within block
__syncthreads();
}
//write result for this block to global mem
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
The second and fourth lines have a 2x offset when determining the data position for the thread block:
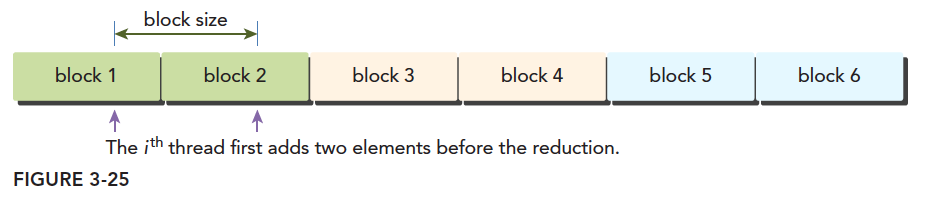
This is what the second and fourth instructions mean. We only process the red thread block. The adjacent white thread block is handled by:
if(idx + blockDim.x < n)
{
g_idata[idx] += g_idata[idx + blockDim.x];
}
Note we're using 1D threads here. We use half the original number of blocks, and with just one small additional instruction per thread, we complete the original full computation. This should yield impressive results. Let's look. First, the kernel call section:
//kernel 1:reduceUnrolling2
CHECK(cudaMemcpy(idata_dev, idata_host, bytes, cudaMemcpyHostToDevice));
CHECK(cudaDeviceSynchronize());
iStart = cpuSecond();
reduceUnroll2 <<<grid.x/2, block >>>(idata_dev, odata_dev, size);
cudaDeviceSynchronize();
iElaps = cpuSecond() - iStart;
cudaMemcpy(odata_host, odata_dev, grid.x * sizeof(int), cudaMemcpyDeviceToHost);
gpu_sum = 0;
for (int i = 0; i < grid.x/2; i++)
gpu_sum += odata_host[i];
printf("reduceUnrolling2 elapsed %lf ms gpu_sum: %d<<<grid %d block %d>>>\n",
iElaps, gpu_sum, grid.x/2, block.x);
Note that since we merged half the thread blocks, the grid count must be correspondingly halved. Let's see the efficiency:
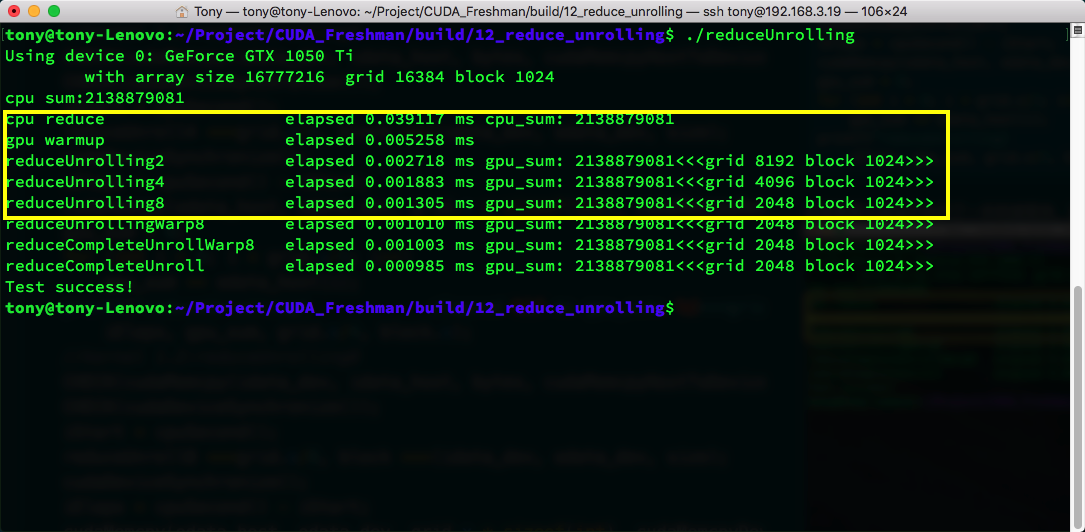
Compared to the efficiency in the previous article, it's "so much higher I don't even know where to start" (always good to quote famous sayings). It's three times faster than the simplest reduction algorithm. Ignore the warmup code.
The yellow boxes above show 2x, 4x, and 8x unrolling scales -- one block processing 2, 4, and 8 blocks of data respectively. The corresponding call code also needs modification. Check the github repository for details.
Github: https://github.com/Tony-Tan/CUDA_Freshman
Direct unrolling has a huge impact on efficiency. From the naive reduction algorithm's 0.01, down to 0.002, then to 0.0013 -- the power is enormous.
This not only saves running redundant thread blocks, but more independent memory load/store operations produce better performance and better latency hiding (if you've forgotten, see previous blog posts for related knowledge). Let's look at their throughput:
nvprof --metrics dram_read_throughput ./reduceUnrolling
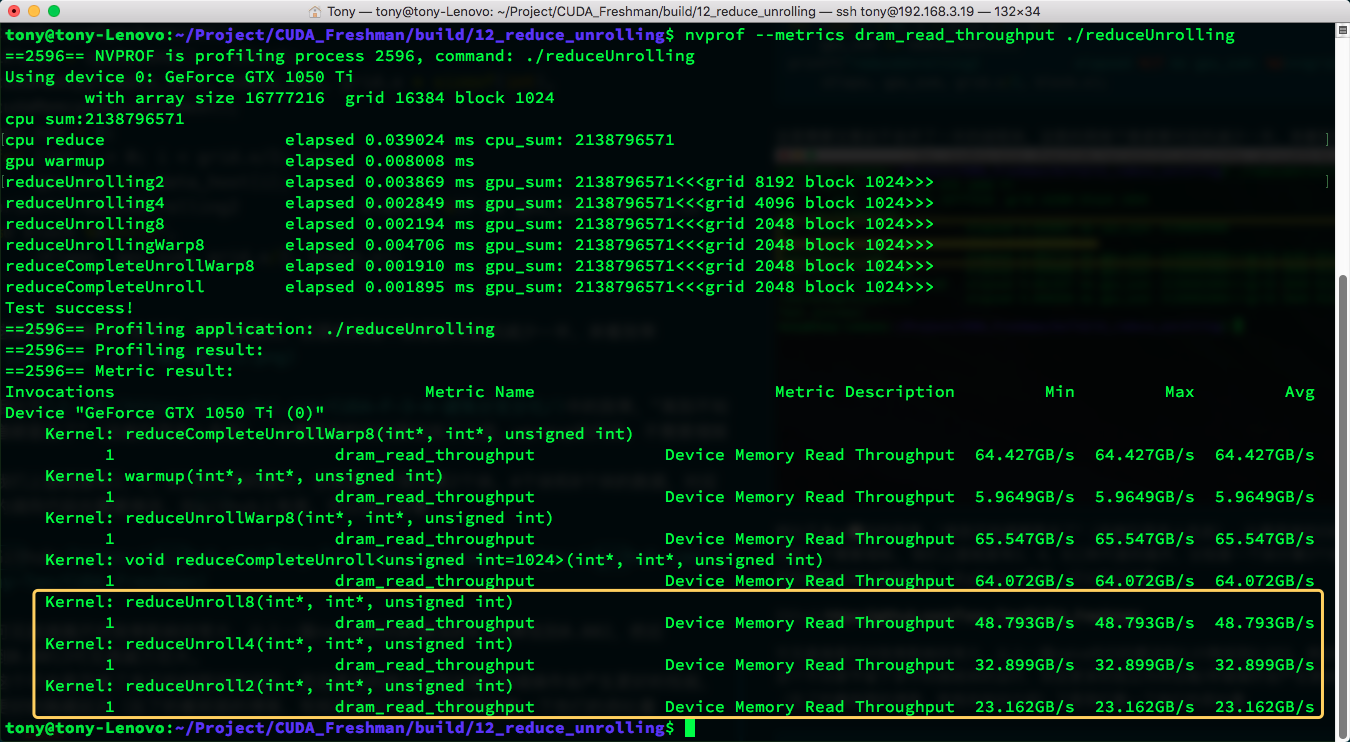
Execution efficiency is positively correlated with memory throughput.
Fully Unrolled Reduction
Next, our target is the final 32 threads. Since reduction is an inverted pyramid where the final result is a single number, each step from 64 to 32, then 16... down to 1 halves the thread utilization. We now devise a method to unroll the last 6 iterations (64, 32, 16, 8, 4, 2, 1) using the following kernel to unroll the final 6 steps of branching:
__global__ void reduceUnrollWarp8(int * g_idata, int * g_odata, unsigned int n)
{
//set thread ID
unsigned int tid = threadIdx.x;
unsigned int idx = blockDim.x * blockIdx.x * 8 + threadIdx.x;
//boundary check
if (tid >= n) return;
//convert global data pointer to the
int *idata = g_idata + blockIdx.x * blockDim.x * 8;
//unrolling 8;
if(idx + 7 * blockDim.x < n)
{
int a1 = g_idata[idx];
int a2 = g_idata[idx + blockDim.x];
int a3 = g_idata[idx + 2 * blockDim.x];
int a4 = g_idata[idx + 3 * blockDim.x];
int a5 = g_idata[idx + 4 * blockDim.x];
int a6 = g_idata[idx + 5 * blockDim.x];
int a7 = g_idata[idx + 6 * blockDim.x];
int a8 = g_idata[idx + 7 * blockDim.x];
g_idata[idx] = a1 + a2 + a3 + a4 + a5 + a6 + a7 + a8;
}
__syncthreads();
//in-place reduction in global memory
for (int stride = blockDim.x/2; stride > 32; stride >>= 1)
{
if (tid < stride)
{
idata[tid] += idata[tid + stride];
}
//synchronize within block
__syncthreads();
}
//write result for this block to global mem
if(tid < 32)
{
volatile int *vmem = idata;
vmem[tid] += vmem[tid + 32];
vmem[tid] += vmem[tid + 16];
vmem[tid] += vmem[tid + 8];
vmem[tid] += vmem[tid + 4];
vmem[tid] += vmem[tid + 2];
vmem[tid] += vmem[tid + 1];
}
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
Building on the unrolling8 approach, for threads with tid in [0,32], we use this code to unroll:
volatile int *vmem = idata;
vmem[tid] += vmem[tid + 32];
vmem[tid] += vmem[tid + 16];
vmem[tid] += vmem[tid + 8];
vmem[tid] += vmem[tid + 4];
vmem[tid] += vmem[tid + 2];
vmem[tid] += vmem[tid + 1];
Let's first not discuss the volatile int variable declaration, and instead trace through this final unrolling. When only the bottom triangle remains -- merging 64 numbers into one -- we first add the first 32 numbers in parallel with a stride of 32. The first 32 tids get pairwise sums of 64 numbers, stored in the first 32 positions.
Then comes our key technique.
These 32 numbers are then added with a stride of 16. Theoretically, this produces 16 numbers, and the sum of these 16 numbers is the reduction result for this block. But based on the tid<32 condition, threads tid 16 to 31 are still running, but their results are no longer meaningful. This step is important (another source of confusion might be: since execution is synchronous, could thread 17 modify position 17 after reading from position 33, and then thread 1 reads the modified value of position 17, making the result wrong? Since CUDA kernels read data from memory to registers and perform additions synchronously, threads 17 and 1 simultaneously read positions 33 and 17. Even if thread 17 modifies position 17 in the next step, it doesn't affect the value in thread 1's register). Although all threads with tid<32 are running, at each step, half the threads' results become meaningless.
Suppose we're executing the step
vmem[tid] += vmem[tid + 16]:
- Thread 1 needs to read
vmem[1]andvmem[17], then write the result tovmem[1]- Thread 17 needs to read
vmem[17]andvmem[33], then write the result tovmem[17]The concern:
- Thread 17 executes first, modifying
vmem[17]- Then thread 1 reads
vmem[17], getting the modified value- The result would be wrong
Why it's actually safe
The key lies in the CUDA warp execution mode:
- Synchronous read: All threads read memory values into their registers at the same moment
- Register isolation: Each thread's registers are independent. Thread 17 modifying
vmem[17]doesn't affect thread 1's already-read register value- Synchronous write: All threads write results back simultaneously
So even if thread 17 modifies
vmem[17]in the next step, thread 1 in the current step still uses the old value previously read into its register, guaranteeing algorithm correctness.This is why this warp-level reduction algorithm works safely without explicit synchronization.
Continuing this computation, we get the final valid result at tid[0].
The process above is a bit complex, but if we think carefully -- from hardware data fetching to computation, analyzing each step -- we can understand the actual results.
The volatile int variable controls whether the variable's result is written back to memory rather than staying in shared memory or cache, because the next computation step needs it immediately. If it's written to cache, the next read might get incorrect data.
Without volatile, the compiler might cache vmem[tid] in a register, causing subsequent steps to not read the updated value. Solution: volatile forces reads and writes from shared memory every time, ensuring:
Every read of vmem[tid] gets the latest value Every computation result is immediately written back to memory
You might wonder:
vmem[tid] += vmem[tid + 32];
vmem[tid] += vmem[tid + 16];
Doesn't tid+16 need tid+32's result? Could other threads cause memory contention? The answer is no. Within a warp, execution progress is completely identical. When executing tid+32, all 32 threads are executing this step -- no thread within this warp will advance to the next instruction. For details, recall the CUDA execution model (since the CUDA compiler is aggressive, we must add volatile to prevent the compiler from optimizing data transfers and disrupting execution order).
Then we get the result. Let's look at the time:
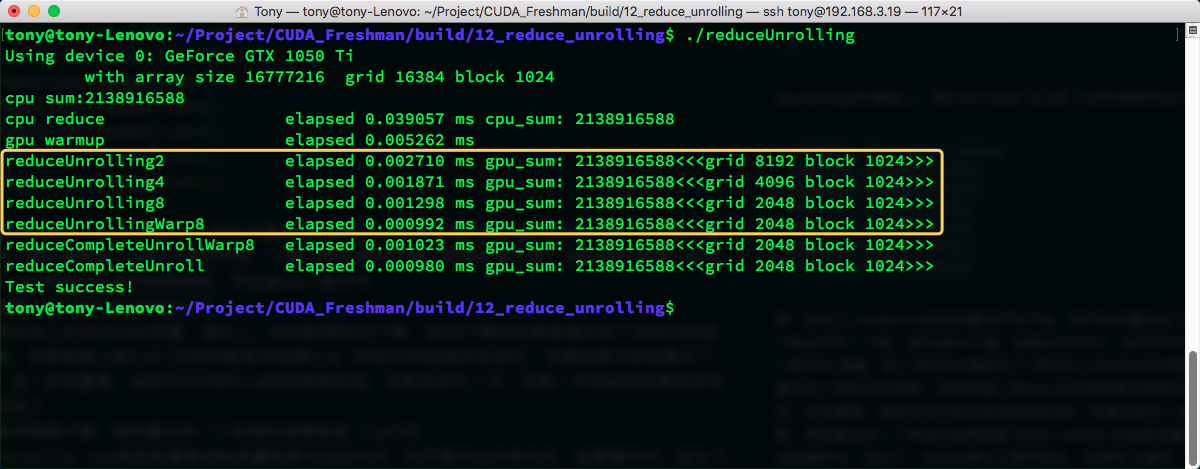
Another decimal place improvement -- looks very nice.
This unrolling also saves time by reducing 5 warp synchronization instructions (__syncthreads();). Reducing this instruction 5 times is very effective. Let's see how much blocking was reduced.
Using:
nvprof --metrics stall_sync ./reduceUnrolling
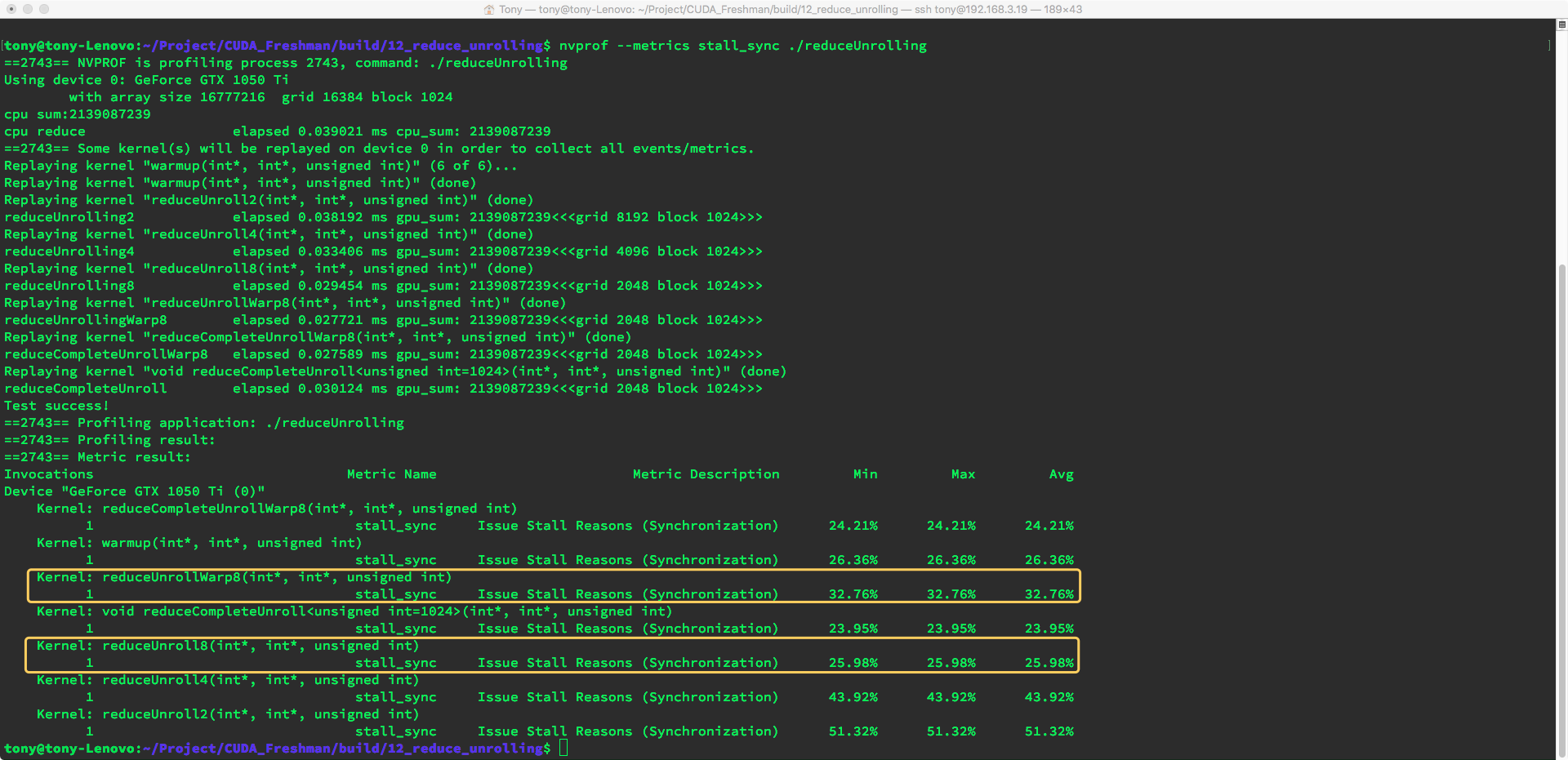
Interestingly, the book's results differ from our runtime results. The unrolled version's stall_sync metric is actually higher, meaning the version with synchronization instructions was more efficient. This may be related to CUDA compiler optimization.
Template Function Reduction
Based on the above unrolling of the last 64 data items, we can directly unroll the last 128, 256, 512, and 1024 data items.
No more talk -- straight to code. Our goal this time is to make loops disappear:
__global__ void reduceCompleteUnrollWarp8(int * g_idata, int * g_odata, unsigned int n)
{
//set thread ID
unsigned int tid = threadIdx.x;
unsigned int idx = blockDim.x * blockIdx.x * 8 + threadIdx.x;
//boundary check
if (tid >= n) return;
//convert global data pointer to the
int *idata = g_idata + blockIdx.x * blockDim.x * 8;
if(idx + 7 * blockDim.x < n)
{
int a1 = g_idata[idx];
int a2 = g_idata[idx + blockDim.x];
int a3 = g_idata[idx + 2 * blockDim.x];
int a4 = g_idata[idx + 3 * blockDim.x];
int a5 = g_idata[idx + 4 * blockDim.x];
int a6 = g_idata[idx + 5 * blockDim.x];
int a7 = g_idata[idx + 6 * blockDim.x];
int a8 = g_idata[idx + 7 * blockDim.x];
g_idata[idx] = a1 + a2 + a3 + a4 + a5 + a6 + a7 + a8;
}
__syncthreads();
//in-place reduction in global memory
if(blockDim.x >= 1024 && tid < 512)
idata[tid] += idata[tid + 512];
__syncthreads();
if(blockDim.x >= 512 && tid < 256)
idata[tid] += idata[tid + 256];
__syncthreads();
if(blockDim.x >= 256 && tid < 128)
idata[tid] += idata[tid + 128];
__syncthreads();
if(blockDim.x >= 128 && tid < 64)
idata[tid] += idata[tid + 64];
__syncthreads();
//write result for this block to global mem
if(tid < 32)
{
volatile int *vmem = idata;
vmem[tid] += vmem[tid + 32];
vmem[tid] += vmem[tid + 16];
vmem[tid] += vmem[tid + 8];
vmem[tid] += vmem[tid + 4];
vmem[tid] += vmem[tid + 2];
vmem[tid] += vmem[tid + 1];
}
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
The kernel code is above. Here we use the tid size. Unlike the final 32 which don't use tid checks, these would waste half their computation if fully evaluated. The final 32 are already the smallest warp size, so regardless of whether subsequent data is meaningful, those threads won't stop.
Each step uses explicit synchronization. Let's look at the result:
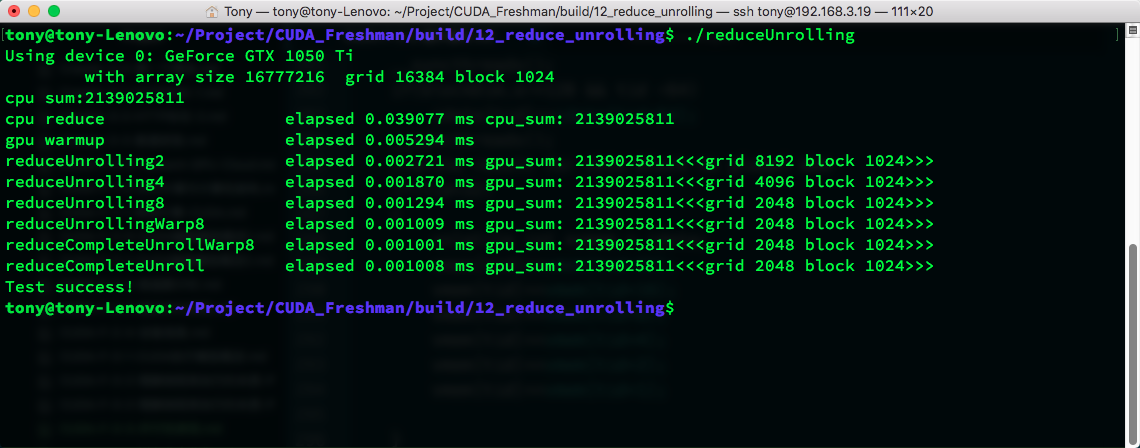
Speed doesn't seem to be affected at all, so I think this may be related to compiler optimization.
Template Function Reduction
Let's look at the fully unrolled function above:
if(blockDim.x >= 1024 && tid < 512)
idata[tid] += idata[tid + 512];
__syncthreads();
if(blockDim.x >= 512 && tid < 256)
idata[tid] += idata[tid + 256];
__syncthreads();
if(blockDim.x >= 256 && tid < 128)
idata[tid] += idata[tid + 128];
__syncthreads();
if(blockDim.x >= 128 && tid < 64)
idata[tid] += idata[tid + 64];
__syncthreads();
These comparisons are probably redundant because blockDim.x, once determined at kernel launch, cannot change. Template functions solve this problem. At compile time, the compiler checks whether blockDim.x is fixed. If it is, it directly removes the impossible parts from the kernel. For example, with blockDim.x=512, the final generated machine code is only:
__syncthreads();
if(blockDim.x >= 512 && tid < 256)
idata[tid] += idata[tid + 256];
__syncthreads();
if(blockDim.x >= 256 && tid < 128)
idata[tid] += idata[tid + 128];
__syncthreads();
if(blockDim.x >= 128 && tid < 64)
idata[tid] += idata[tid + 64];
__syncthreads();
The impossible parts are removed.
Let's look at the template function's efficiency:
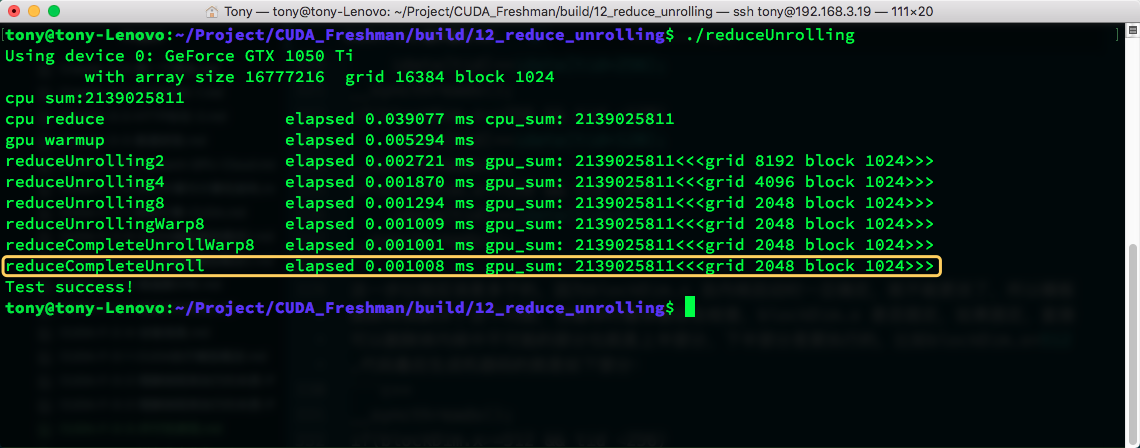
The result is that it's actually slightly slower... The book said otherwise... This may be related to compiler optimization strategies.
Summary
Let's summarize the metric comparison of the four optimization steps in this article.
Load efficiency and store efficiency:
nvprof --metrics gld_efficiency,gst_efficiency ./reduceUnrolling
| Algorithm | Time | Load Efficiency | Store Efficiency |
|---|---|---|---|
| Adjacent no divergence (prev) | 0.010491 | 25.01% | 25.00% |
| Adjacent divergence (prev) | 0.005968 | 25.01% | 25.00% |
| Interleaved (prev) | 0.004956 | 98.04% | 97.71% |
| Unroll 8 | 0.001294 | 99.60% | 99.71% |
| Unroll 8 + final unroll | 0.001009 | 99.71% | 99.68% |
| Unroll 8 + full + final | 0.001001 | 99.71% | 99.68% |
| Template of previous | 0.001008 | 99.71% | 99.68% |
Although results differ somewhat from the book, the relationship between metrics and efficiency is clear. Today's conclusion is: optimize step by step. If changing code doesn't help, it may be related to compiler optimization strategies.
Summary
Before development, it's best to understand compiler characteristics. And the most critical point -- a truth: nobody can write the best code on the first try. Optimize step by step. From 0.0104 to 0.001001 -- nearly 10x efficiency improvement. A one-minute program might not seem like much, but a program that runs for a year, optimized by a factor of ten -- that's a major achievement.
We'll continue next time. Compiler optimization is indeed a topic that requires deep understanding!