3.6 Dynamic Parallelism
Abstract: This article introduces CUDA dynamic parallelism -- launching new child grids from a grid running on the device.
Keywords: Dynamic Parallelism, Nested Execution
Dynamic Parallelism
As the final article in Chapter 3 on the CUDA execution model, this article introduces dynamic parallelism. The book includes an example of nested reduction with dynamic parallelism, but I believe it's not very useful for us. First, it doesn't reduce code complexity. Second, its runtime efficiency doesn't improve either. Dynamic parallelism is analogous to recursive calls in serial programming. If a recursive call can be converted to an iterative loop, it's generally converted for efficiency. Only when efficiency is less important and code simplicity is prioritized do we use recursion. So this article only introduces some basic fundamentals. If you need to use dynamic parallelism, please consult the documentation or more specialized blogs.
Up to now, all our kernels have been called from host threads. Naturally, we wonder: can we call a kernel from within a kernel? This kernel could be a different kernel, or it could be itself. This requires dynamic parallelism, which is not supported on devices with compute capability below 3.5.
One benefit of dynamic parallelism is making complex kernels more hierarchical. The downside is that programs become more complex because parallel programs are already difficult to control. Last year, before I had systematically learned CUDA, I wrote a kernel of about 400 lines for training a face detection program. It was indeed faster than CPU, but judging from the GPU temperature, utilization wasn't very high (I didn't know how to use performance monitoring tools at the time. When TensorFlow ran, GPU temperature was over 80 degrees, but my program only reached 60+ degrees, suggesting GPU performance wasn't fully utilized). That program still ran for a long time -- showing the importance of systematic learning.
Another benefit of dynamic parallelism is configuring how many grids and blocks to create at execution time, dynamically utilizing the GPU hardware scheduler and load balancer to adapt to workload. Additionally, launching kernels from within kernels can reduce some data transfer overhead.
Nested Execution
The content we've learned so far mainly includes grids, blocks, launch configurations, and some warp knowledge. What we're going to do now is launch kernels from within kernels.
Launching kernels from kernels has a similar concept in CPU parallel programming: parent threads and child threads. Child threads are launched by parent threads. On the GPU, these concepts are richer: parent grid, parent thread block, parent thread -- corresponding to child grid, child thread block, child thread. A child grid is launched by a parent thread and must finish before the corresponding parent thread, parent thread block, and parent grid end. Only after all child grids finish can the parent thread, parent thread block, and parent grid finish.
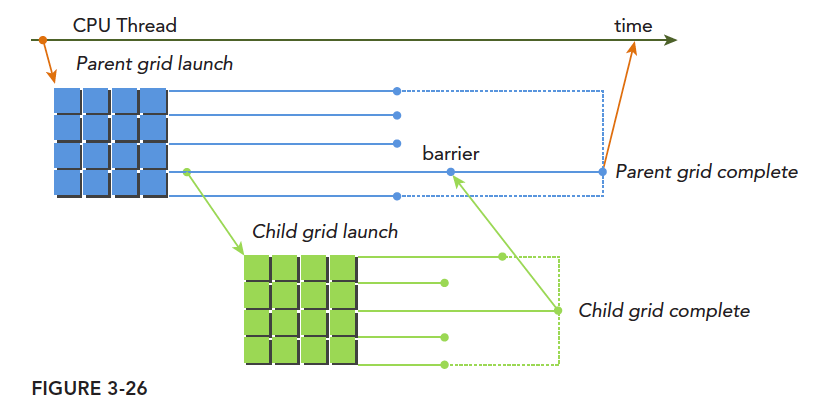
The diagram clearly shows the usage of parent and child grids. A typical execution pattern:
Host launches a grid (i.e., a kernel) -> This grid (parent grid) launches new grids (child grids) during execution -> All child grids finish -> Parent grid can finish, otherwise it waits
If the calling thread doesn't explicitly synchronize the child grid launch, the runtime ensures implicit synchronization between parent and child grids.
The diagram explicitly synchronizes parent and child grids through the fence-setting method.
Different child grids launched by different threads in the parent grid, sharing the same parent thread block, can synchronize with each other. Thread block execution completes only after all child grids created by all threads in the block finish. If all threads in the block exit before child grids complete, implicit synchronization of child grids is triggered. Implicit synchronization means that even without a synchronization instruction, although all threads in the parent thread block have completed, it still waits for all corresponding child grids to finish before it can exit.
We discussed implicit synchronization earlier. For example, cudaMemcpy provides implicit synchronization. However, for grids launched from the host, without explicit synchronization or implicit synchronization instructions, the CPU thread may actually exit while your GPU program is still running, causing synchronization issues. Parent thread blocks launching child grids require explicit synchronization -- that is, different warps must all reach the child grid launch instruction for all child grids within that thread block to execute sequentially based on their warp's execution.
Next is the more complex memory management. Memory races are already troublesome for regular parallelism, and for dynamic parallelism, they're even more complex. The main points are:
- Parent and child grids share the same global and constant memory.
- Parent and child grids have different local memory.
- With weak consistency between parent and child grids as a guarantee, parent and child grids can concurrently access global memory.
- There are two moments when parent and child grids see consistent memory: when a child grid launches and when a child grid finishes.
- Shared memory and local memory are private to thread blocks and threads, respectively.
- Local memory is private to threads and not visible externally.
Nested Hello World on the GPU
To explore basic dynamic parallelism, let's write a Hello World first. Code:
#include <cuda_runtime.h>
#include <stdio.h>
__global__ void nesthelloworld(int iSize, int iDepth)
{
unsigned int tid = threadIdx.x;
printf("depth : %d blockIdx: %d, threadIdx: %d\n", iDepth, blockIdx.x, threadIdx.x);
if (iSize == 1)
return;
int nthread = (iSize >> 1);
if (tid == 0 && nthread > 0)
{
nesthelloworld<<<1, nthread>>>(nthread, ++iDepth);
printf("-----------> nested execution depth: %d\n", iDepth);
}
}
int main(int argc, char* argv[])
{
int size = 64;
int block_x = 2;
dim3 block(block_x, 1);
dim3 grid((size-1)/block.x+1, 1);
nesthelloworld<<<grid, block>>>(size, 0);
cudaGetLastError();
cudaDeviceReset();
return 0;
}
This is the complete executable code. The compilation command is slightly different from before. The project uses cmake for management, but this program uses a standalone makefile:
nvcc -arch=sm_35 nested_Hello_World.cu -o nested_Hello_World -lcudadevrt --relocatable-device-code true
-lcudadevrt --relocatable-device-code true are compilation options not used before. These are required for dynamic parallelism. relocatable-device-code generates relocatable code. Chapter 10 will cover more about relocating device code.
This program works as follows:
Layer 1: Multiple thread blocks execute and output. Then, in the thread with tid==0, launch a child grid. The child grid's configuration is half of the current one, including thread count and the input parameter iSize.
Layer 2: Many different child grids (because multiple parent thread blocks each launched a child grid). We analyze just one child grid: it executes and outputs, then in the child thread with tid==0, launches a child grid. Configuration is half of the current one.
Layer 3: Continues recursing until iSize==1.
The execution result is below. It's a bit long, but you can see some patterns. Due to too much output, I've captured some interesting parts for you. If you want to run it yourself, clone from github:
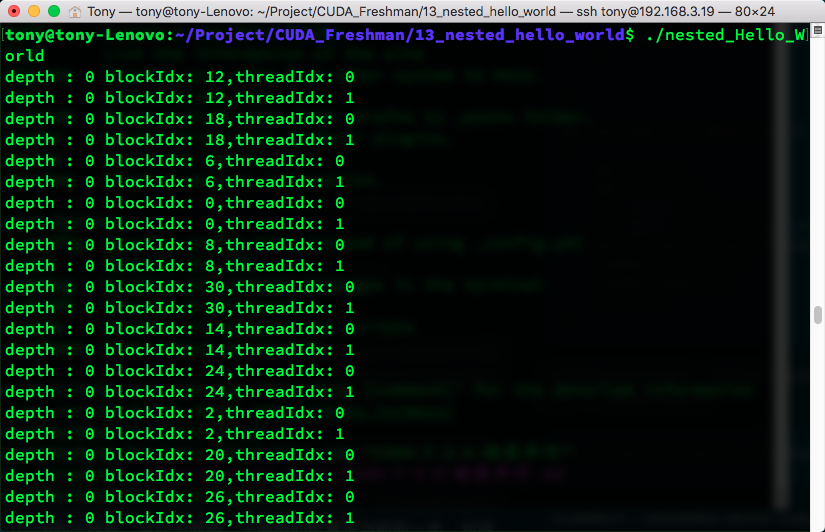
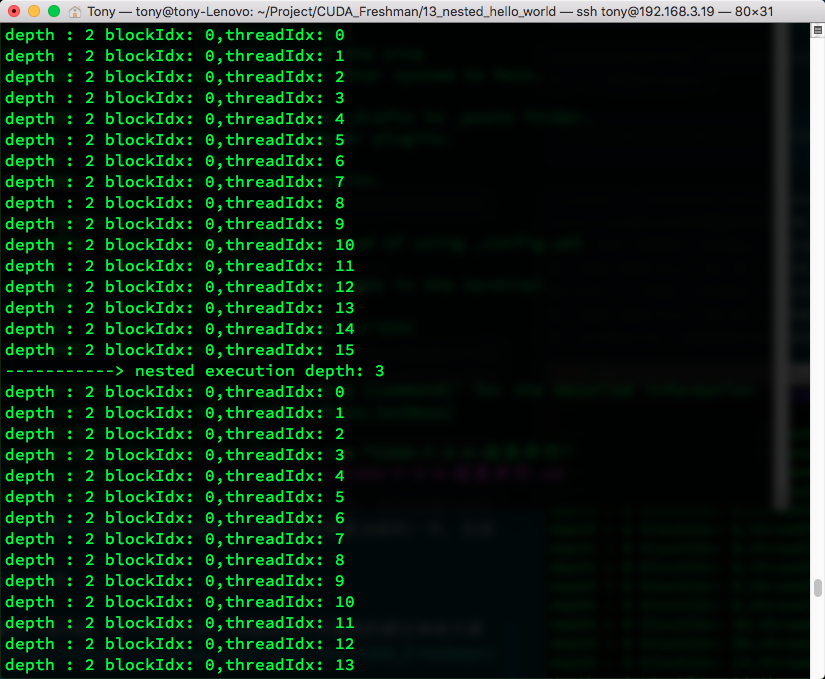
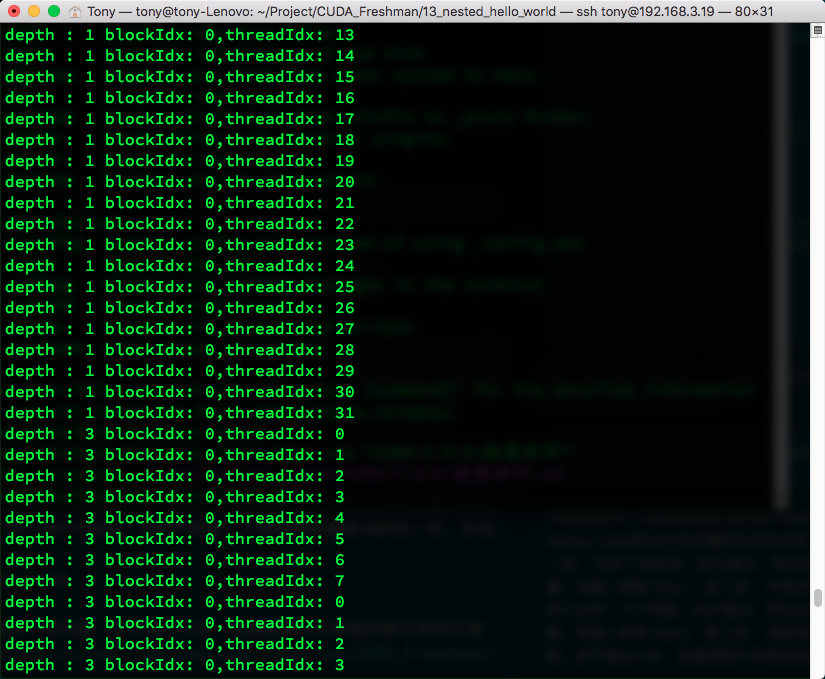
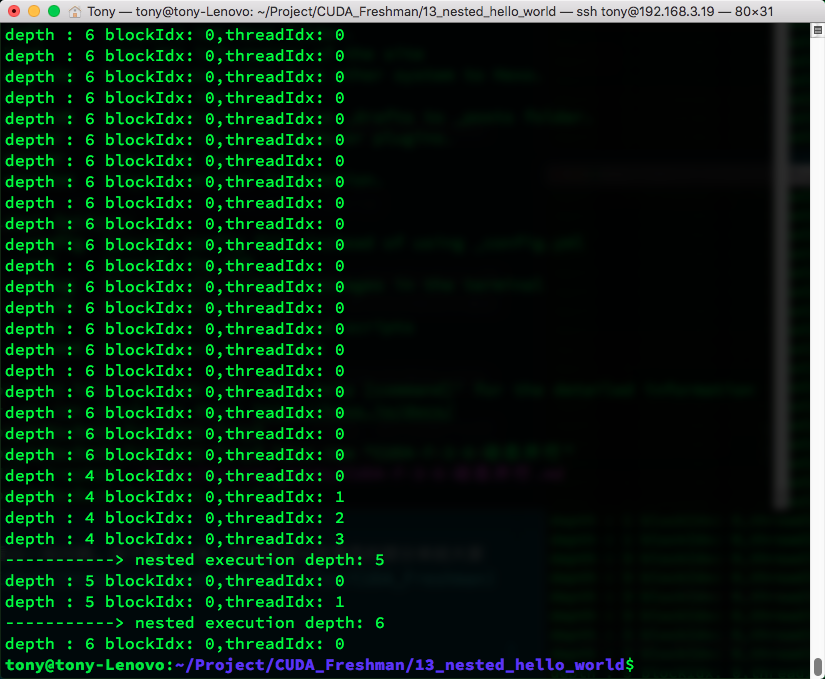
As you can see, when multi-level child grids are launched, child grids from the same parent thread block are implicitly synchronized, while child grids from different parent thread blocks execute independently.
Summary
This article briefly introduced the fundamentals of dynamic parallelism. The content is relatively basic. Reduction using dynamic parallelism won't be covered here -- those who need it can study on their own. The next article begins a new chapter where we start studying memory management.