5.2 Data Layout in Shared Memory
Published on 2018-06-02 | Category: CUDA , Freshman | Comments: 0 | Views:
Abstract: This article studies several examples of shared memory to understand its properties and accelerate our kernel functions.
Keywords: Row-Major Order, Column-Major Order, Padding and No Padding, Mapping Data Elements from Thread Indices
Data Layout in Shared Memory
In this article, we study the data layout of shared memory. Through code implementation, we observe runtime data. In other words, we mainly study the effects of various operations (storing, loading, and transforming data) on performance from the previous article, and how to maximize efficiency.
The examples cover the following topics:
- Square matrices vs rectangular matrices
- Row-major vs column-major order
- Static vs dynamic shared memory declarations
- File-scope vs kernel-scope shared memory
- Memory padding vs no padding
When designing kernel functions that use shared memory, the following two concepts are very important:
- Mapping data elements across memory banks
- Mapping thread indices to shared memory offsets
When these topics and concepts are well understood, designing efficient kernel functions using shared memory becomes straightforward -- avoiding bank conflicts and fully leveraging the advantages of shared memory.
Note: geometrically, a square is a type of rectangle. Here, when we say "rectangle," we mean a non-square rectangle.
Square Shared Memory
We mentioned earlier that our thread blocks can be 1D, 2D, or 3D, corresponding to thread indices threadIdx.x, threadIdx.y, and threadIdx.z. To map to 2D shared memory, we assume we use a 2D thread block. For a 2D shared memory:
#define N 32
...
__shared__ int x[N][N];
...
When using a 2D block, we are likely to index x's data like this:
#define N 32
...
__shared__ int x[N][N];
...
int a=x[threadIdx.y][threadIdx.x];
This indexing is (y,x). We can also use (x,y) for indexing.
On a CPU, when looping through a 2D array, especially with nested loops, we tend to make the inner loop correspond to x because this access pattern is contiguous in memory -- CPU memory is linear. However, GPU shared memory is not linear but two-dimensional, divided into different banks. Moreover, parallelism is not loops -- the problem is completely different and not comparable.
Recalling the watermelon example and the nature of bank conflicts, it is easy to realize that what we should most avoid is bank conflicts. The corresponding question is: when we execute a warp, for a 2D thread block, how is a warp divided? Is it divided along threadIdx.x or threadIdx.y?
This statement may be confusing, so let me elaborate. This is critical. We execute one warp at a time. A warp contains many threads. For a 2D block, there are two ways to cut the warp: cutting along y means threadIdx.x is fixed (changes slowly) while threadIdx.y changes continuously; cutting along x is the opposite. CUDA explicitly tells us that we cut along x -- that is, threadIdx.x changes continuously within a warp.
Our data is stored row by row in the banks -- this is fixed. So we want the warp to fetch data row by row. Therefore:
x[threadIdx.y][threadIdx.x];
This access pattern is optimal. threadIdx.x changes continuously within a warp, and in shared memory it traverses different columns of the same row.
The above is indeed somewhat convoluted. Draw a diagram, imagine more about CUDA's execution principle, and it becomes easier to understand. In plain terms: don't have a warp access a column of shared memory; instead, access a row.
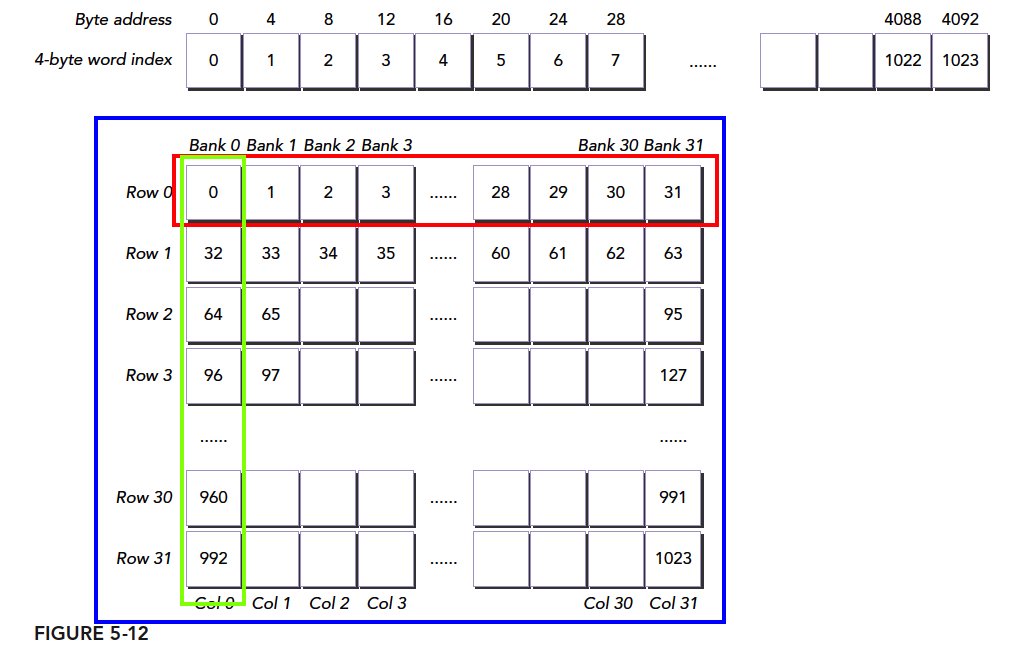
Referring to the figure above, we place an array of 1024 int (4-byte) elements in shared memory A. Each int's index corresponds to the blue boxes. Assuming our block size is (32,32), our first warp is threadIdx.y=0, threadIdx.x=0...31. If we use:
A[threadIdx.x][threadIdx.y];
indexing, we get the data in the green boxes. As you can imagine, this causes maximum conflict and minimum efficiency.
If we use:
A[threadIdx.y][threadIdx.x];
we get the data in the red boxes -- no conflict, one transaction completes.
All code for this article is available for download on GitHub: https://github.com/Tony-Tan/CUDA_Freshman
Row-Major and Column-Major Access
We have already explained the principles of row-major and column-major access above. Let's look at the implementation experiments. The access patterns we study include both read and write -- that is, load and store.
We define the block size as:
#define BDIMX 32
#define BDIMY 32
The kernel function performs only two simple operations:
- Store the global thread index value into 2D shared memory
- Read these values from shared memory in row-major order and store them to global memory
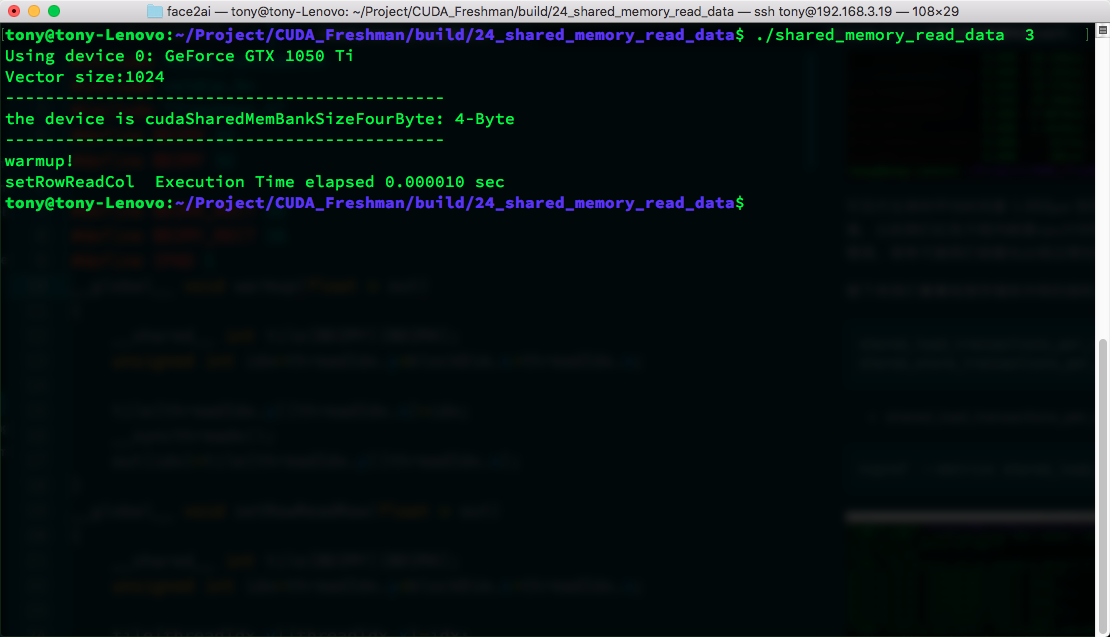
The complete project code is in the 24_shared_memory_read_data folder. Below we only paste portions of the code.
The kernel function:
__global__ void setRowReadRow(int * out)
{
__shared__ int tile[BDIMY][BDIMX];
unsigned int idx=threadIdx.y*blockDim.x+threadIdx.x;
tile[threadIdx.y][threadIdx.x]=idx;
__syncthreads();
out[idx]=tile[threadIdx.y][threadIdx.x];
}
- Declare a shared memory of size 32 x 32
- Calculate the global position value idx for the current thread
- Write the unsigned integer value idx into 2D shared memory tile[threadIdx.y][threadIdx.x]
- Synchronize
- Write the value from shared memory tile[threadIdx.y][threadIdx.x] to the corresponding idx position in global memory
Kernel memory operations:
- Shared memory write
- Shared memory read
- Global memory write
This kernel reads and writes in row-major order, so there are no read/write conflicts for shared memory.
Another approach is column-major access. The kernel code:
__global__ void setColReadCol(int * out)
{
__shared__ int tile[BDIMY][BDIMX];
unsigned int idx=threadIdx.y*blockDim.x+threadIdx.x;
tile[threadIdx.x][threadIdx.y]=idx;
__syncthreads();
out[idx]=tile[threadIdx.x][threadIdx.y];
}
The principle will not be repeated. Let's look directly at the results:
If nvprof shows the error "======== Error: unified memory profiling failed.", it is because of system protection mechanisms. Use sudo to execute. If sudo cannot find your nvprof, use the full path or add it to your environment variables:
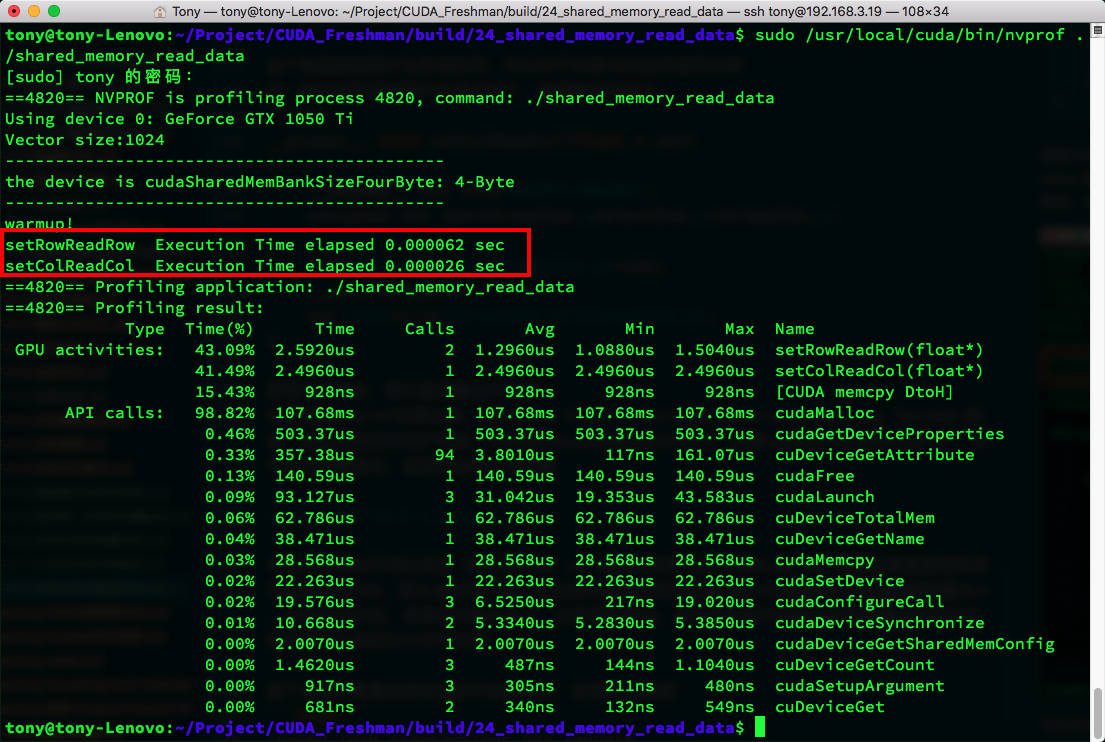
We can see that the average time for row-major is 1.552us, while column-major is 2.4640us. Note that if you use CPU timing methods directly, the results will be very inaccurate. The red box shows CPU timing results -- the reason is that the data volume is too small and the execution time is too short, making the error relatively large. This is clearly wrong, and it is very likely that some previous discrepancies between theory and practice were also due to timing issues.
Next, let's look at the bank conflict detection metrics:
shared_load_transactions_per_request
shared_store_transactions_per_request
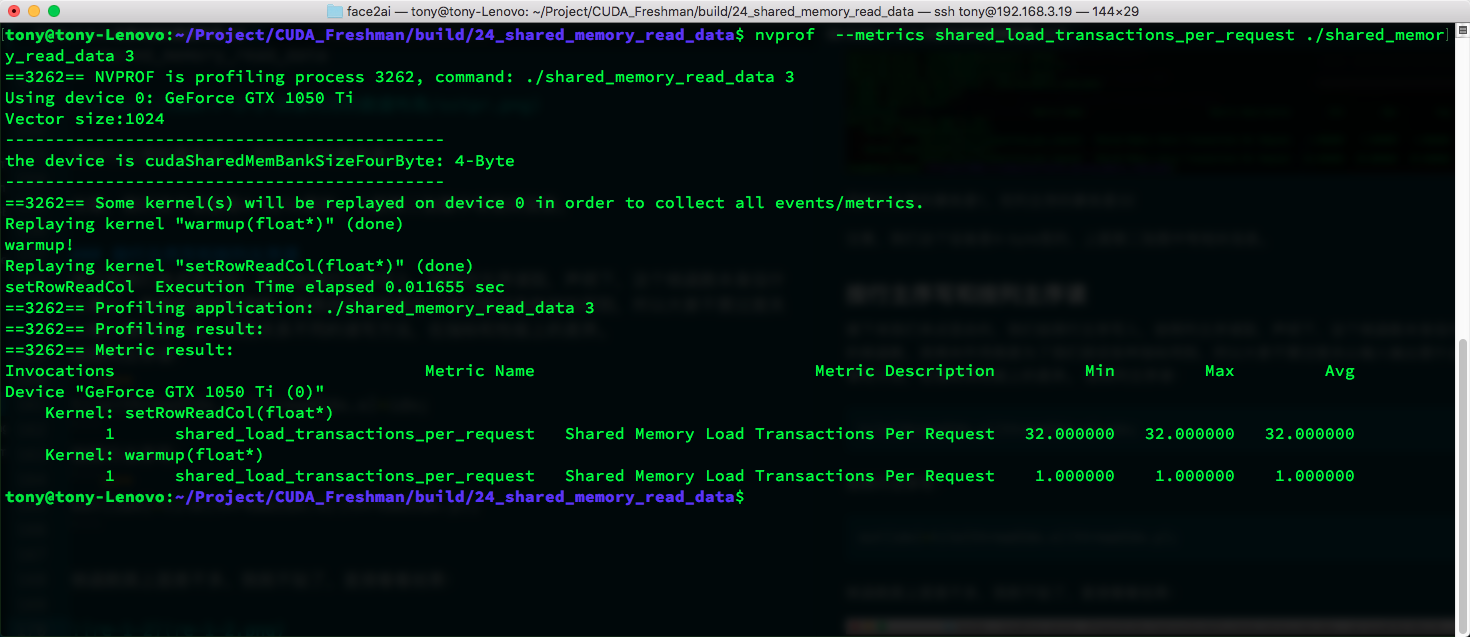
- shared_load_transactions_per_request results:
nvprof --metrics shared_load_transactions_per_request ./shared_memory_read_data
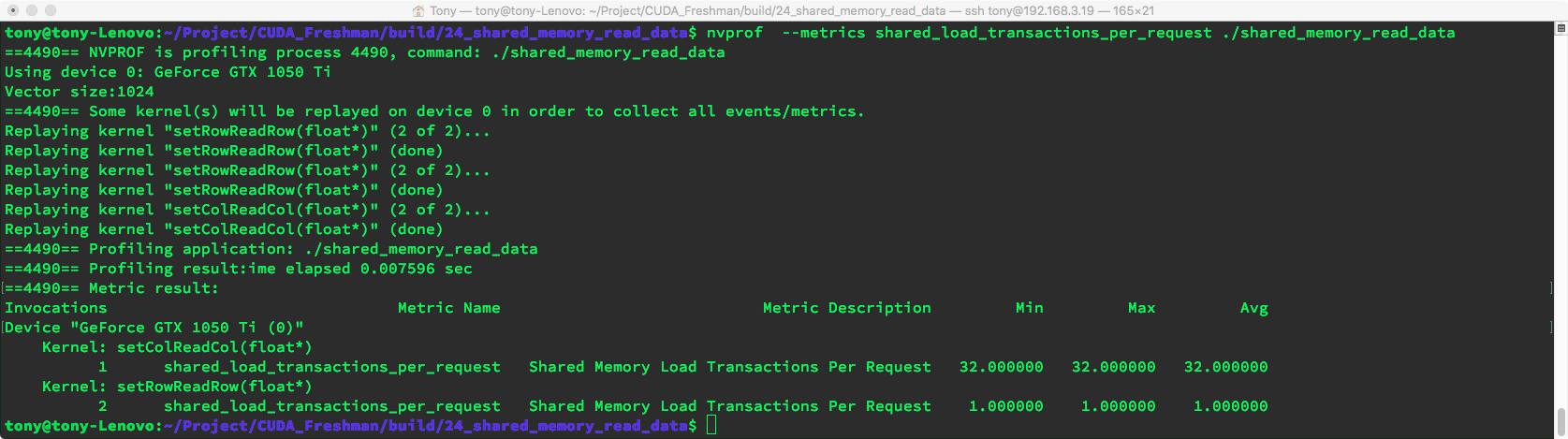
We can see that the load process has 1 transaction for row-major and 32 for column-major.
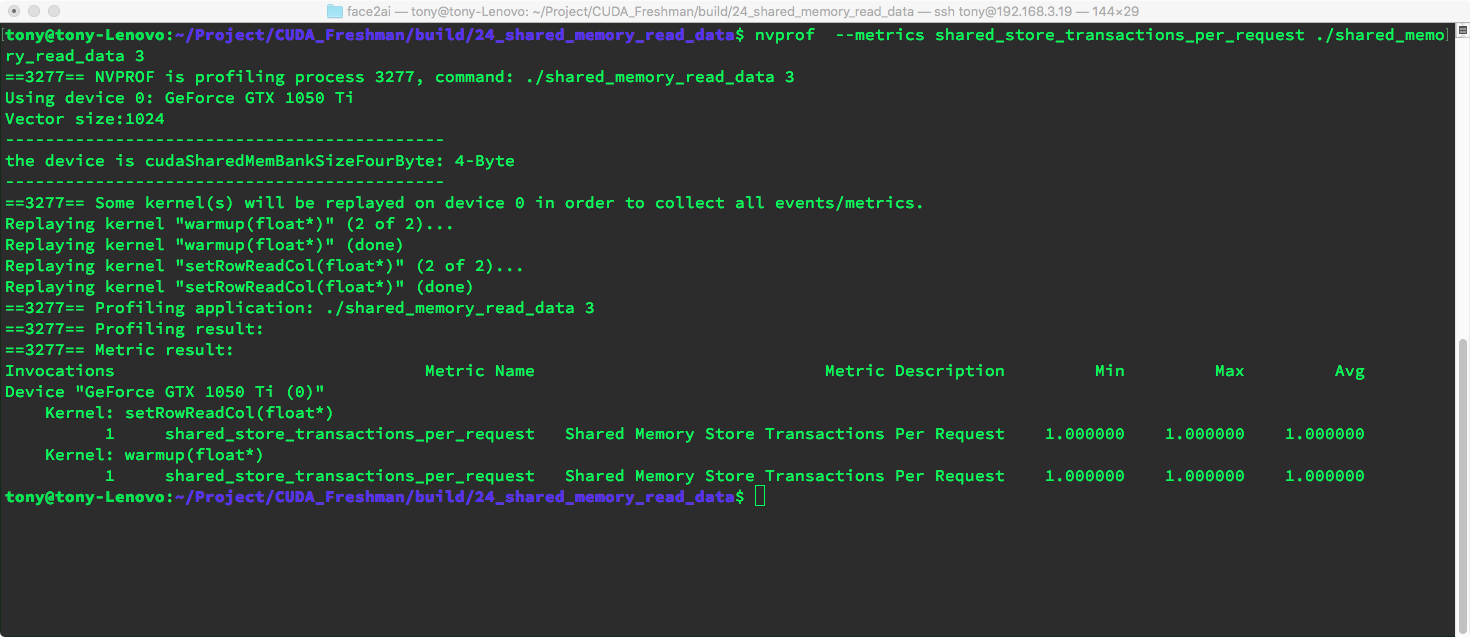
- shared_store_transactions_per_request results:
nvprof --metrics shared_store_transactions_per_request ./shared_memory_read_data
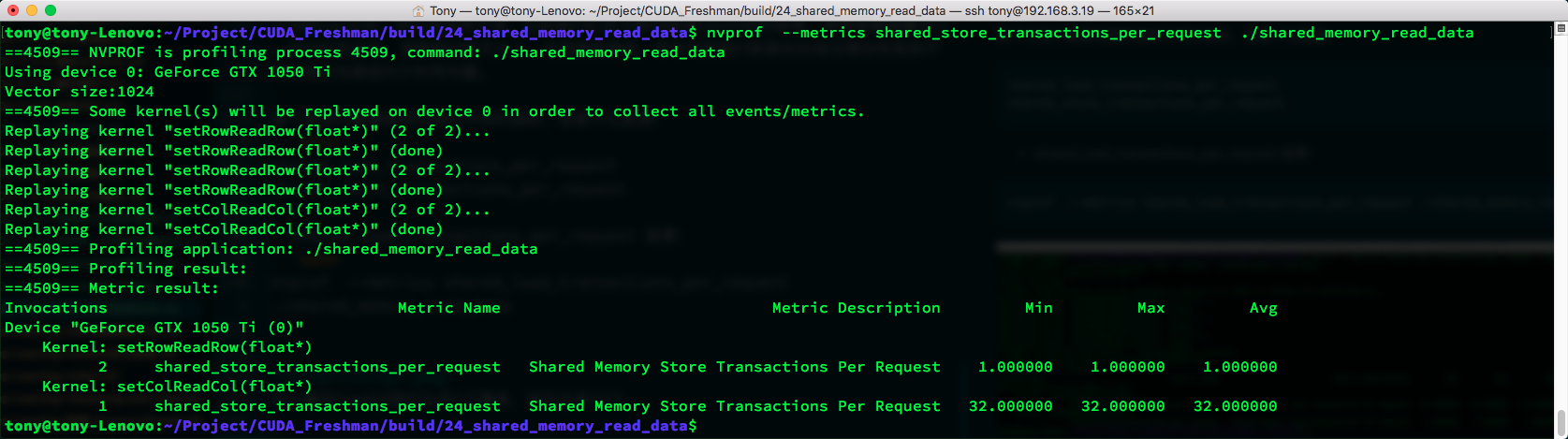
Similarly, row-major transactions are 1, while column-major transactions are 32.
Note that our device has 4-byte width. The second image above contains this information.
Writing in Row-Major and Reading in Column-Major
Next, let's mix things up. We write in row-major order and read in column-major order. To be clear, this kernel function itself has no practical meaning, just like the previous kernels -- their fundamental purpose is for testing various metrics. So don't over-focus on the input/output, but rather on the differences in metrics and performance across different read/write methods.
Reading in column-major:
out[idx]=tile[threadIdx.x][threadIdx.y];
Writing in row-major:
tile[threadIdx.y][threadIdx.x]=idx;
The kernel is similar to above, so I won't paste it. Let's look directly at the results:
shared_load_transactions_per_request:
shared_store_transactions_per_request:
We can see that during load (reading from shared memory then writing to global memory), there are conflicts -- an obvious 32-way conflict.
The same experiment can test row-major read and column-major write, which we will not repeat here as it is identical.
Dynamic Shared Memory
Shared memory does not have malloc but can be allocated at runtime. I have not investigated the specific mechanism -- whether shared memory also has heap and stack distinction. But we need to understand this method, because anyone who has written C++ programs knows that most variables are dynamically allocated and manually managed. A nice thing about CUDA is that dynamic shared memory does not require manual reclamation.
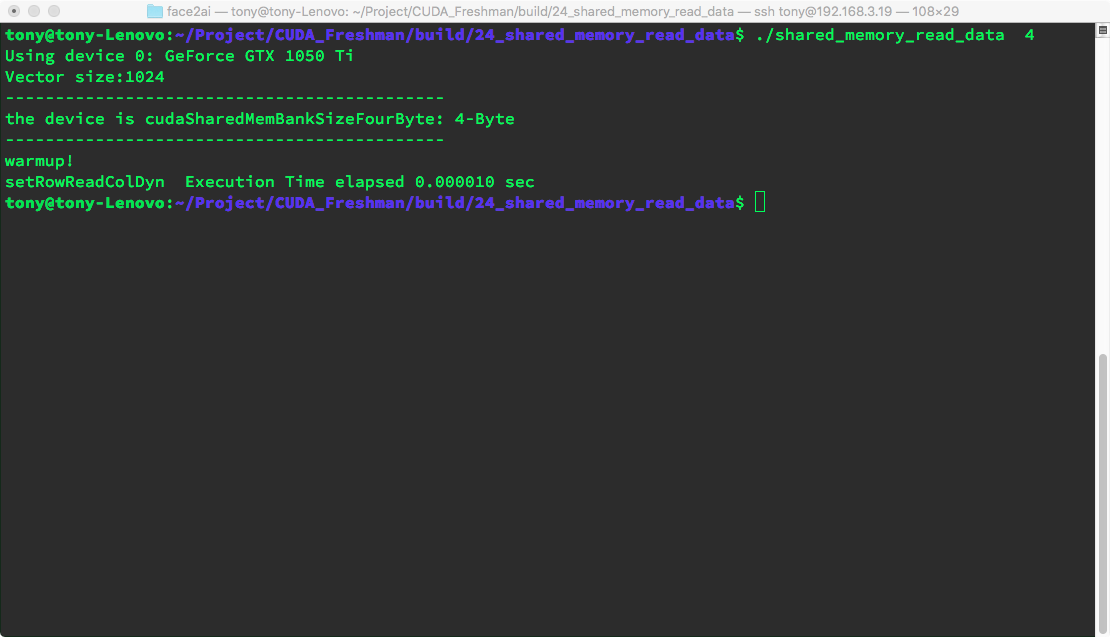
The kernel function:
__global__ void setRowReadColDyn(int * out)
{
extern __shared__ int tile[];
unsigned int row_idx=threadIdx.y*blockDim.x+threadIdx.x;
unsigned int col_idx=threadIdx.x*blockDim.y+threadIdx.y;
tile[row_idx]=row_idx;
__syncthreads();
out[row_idx]=tile[col_idx];
}
Where extern indicates this shared memory is determined at runtime:
extern __shared__ int tile[];
An int shared memory array of unknown length -- when is it determined? At runtime, of course:
setRowReadColDyn<<<grid,block,(BDIMX)*BDIMY*sizeof(int)>>>(out);
Kernel configuration parameters: grid size, block size, and the third parameter is the shared memory size. The question arises: can we declare multiple dynamic shared memories? Can we add more parameters? I haven't tested this -- it's left as a thought exercise.
The results are unsurprising:
shared_load_transactions_per_request:
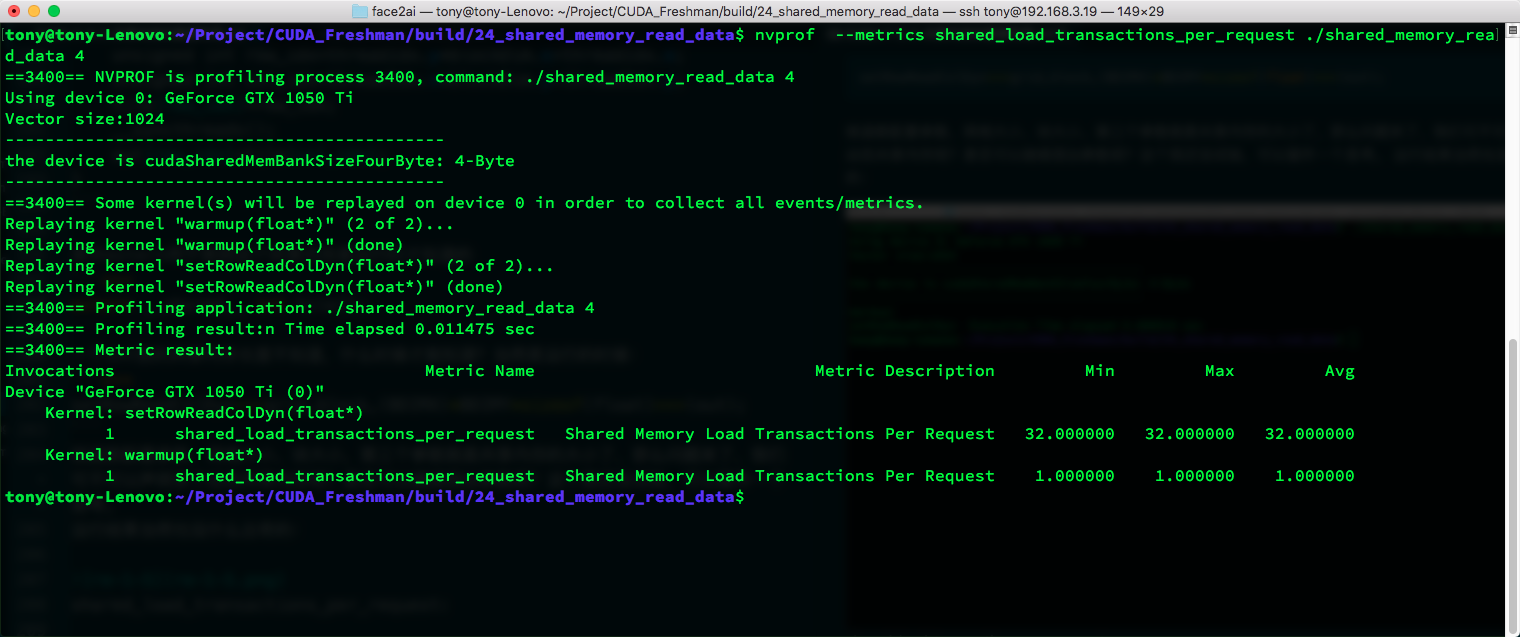
shared_store_transactions_per_request:
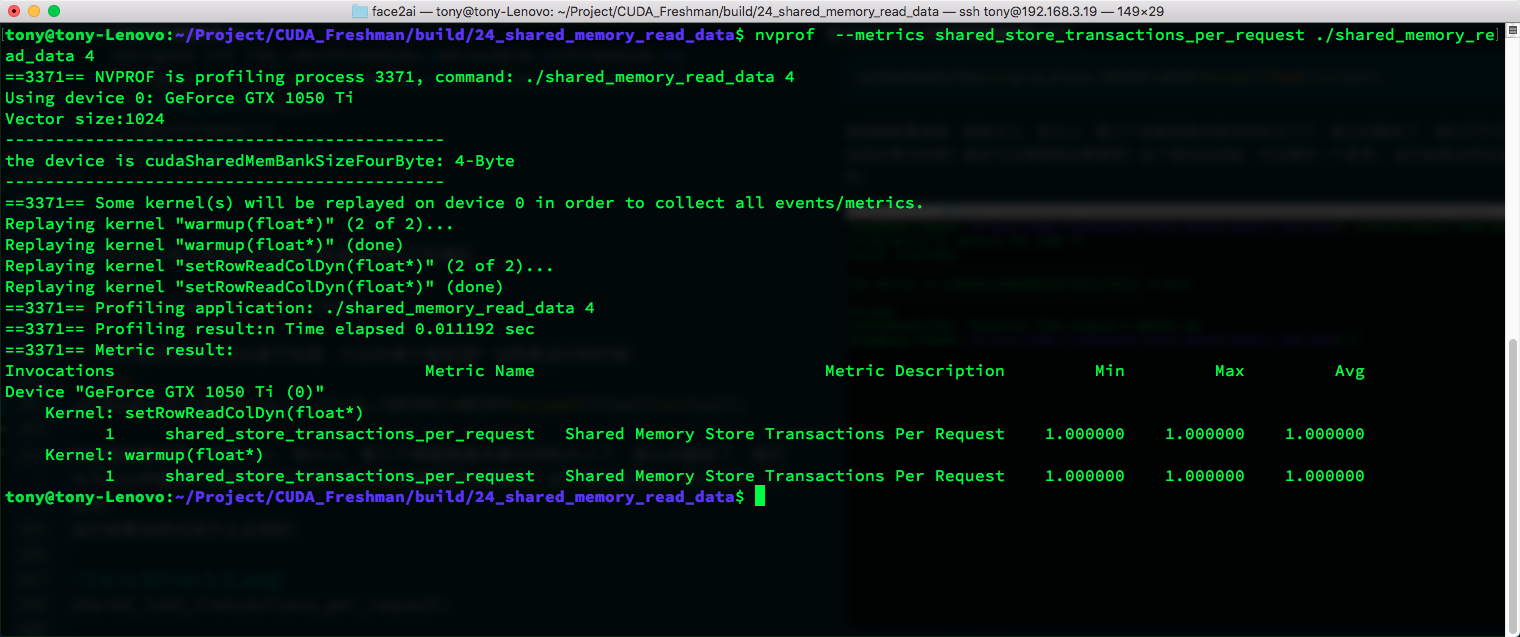
Dynamic and static results are essentially the same -- conflicts remain unchanged.
Padding Statically Declared Shared Memory
We briefly mentioned padding in a previous blog post. We add some padding positions by changing the declared shared memory size -- for example, the last column. When we declare a shared memory of a certain size, it automatically maps to the CUDA model's 2D shared memory banks. In other words, padding occurs at declaration time. Declaring a 2D or 1D shared memory, the compiler automatically rearranges it into a 2D space with 32 banks, each bank having a fixed width. In other words, when you declare a 2D array, the compiler converts the declared 2D into a 1D linear layout, then rearranges it into 2D following the 32-bank, 4-byte/8-byte-wide memory distribution before performing computation.
This is the fundamental principle of padding banks.
With the principle understood, the kernel function below is straightforward -- just adding a constant:
__global__ void setRowReadColIpad(int * out)
{
__shared__ int tile[BDIMY][BDIMX+IPAD];
unsigned int idx=threadIdx.y*blockDim.x+threadIdx.x;
tile[threadIdx.y][threadIdx.x]=idx;
__syncthreads();
out[idx]=tile[threadIdx.x][threadIdx.y];
}
Result:
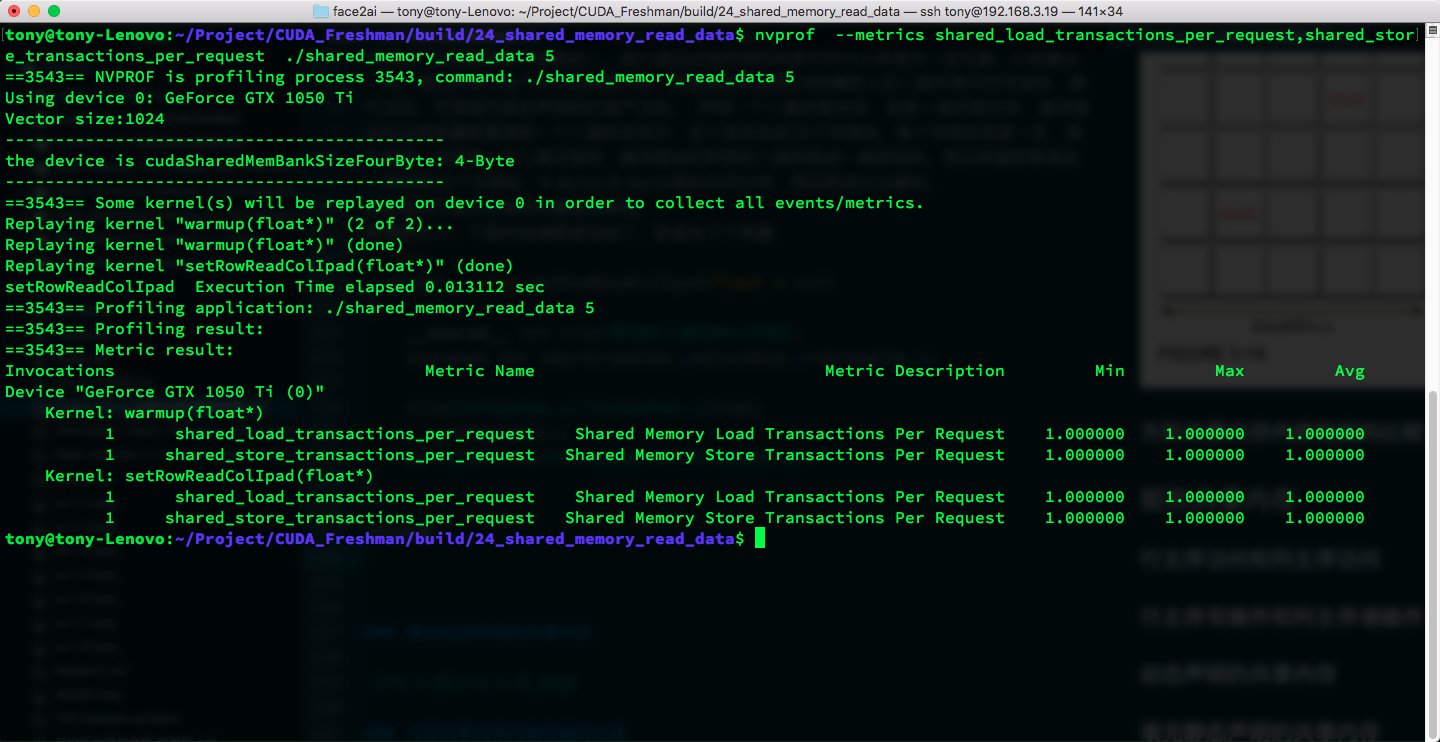
The conflict is gone! Padding works!
Padding Dynamically Declared Shared Memory
Dynamic padding and static padding seem to have no difference -- one is declared inside the kernel, the other is expressed in parameters:
__global__ void setRowReadColDynIpad(int * out)
{
extern __shared__ int tile[];
unsigned int row_idx=threadIdx.y*(blockDim.x+1)+threadIdx.x;
unsigned int col_idx=threadIdx.x*(blockDim.x+1)+threadIdx.y;
tile[row_idx]=row_idx;
__syncthreads();
out[row_idx]=tile[col_idx];
}
Launch code:
setRowReadColDynIpad<<<grid,block,(BDIMX+IPAD)*BDIMY*sizeof(int)>>>(out);
Padding diagram:
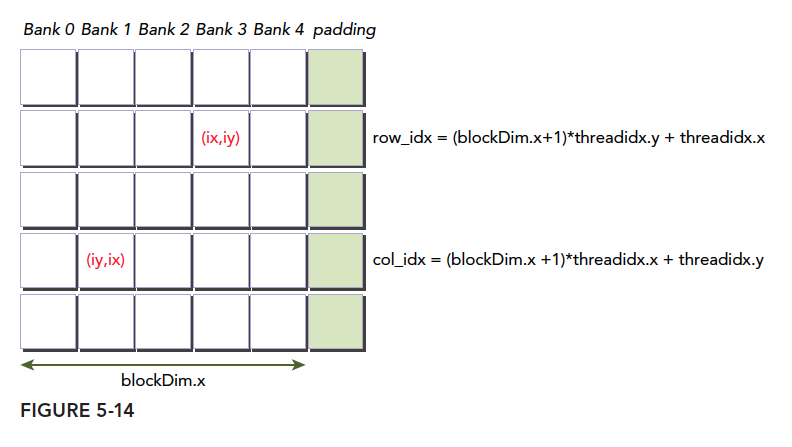
The only thing to note is the index. After padding, our rows stay the same but columns are widened, so indexing must account for this:
unsigned int row_idx=threadIdx.y*(blockDim.x+1)+threadIdx.x;
unsigned int col_idx=threadIdx.x*(blockDim.x+1)+threadIdx.y;
Some readers may be confused about this indexing. Don't think about what happens at the hardware level (the converted bank layout). We only need to care about our logical layout -- the diagram above. Because the bank conversion happens automatically back and forth, corresponding one-to-one with the diagram. If you consider both together, you will inevitably get confused and not understand why it is threadIdx.x*(blockDim.x+1)+threadIdx.y.
And that's it. Results:
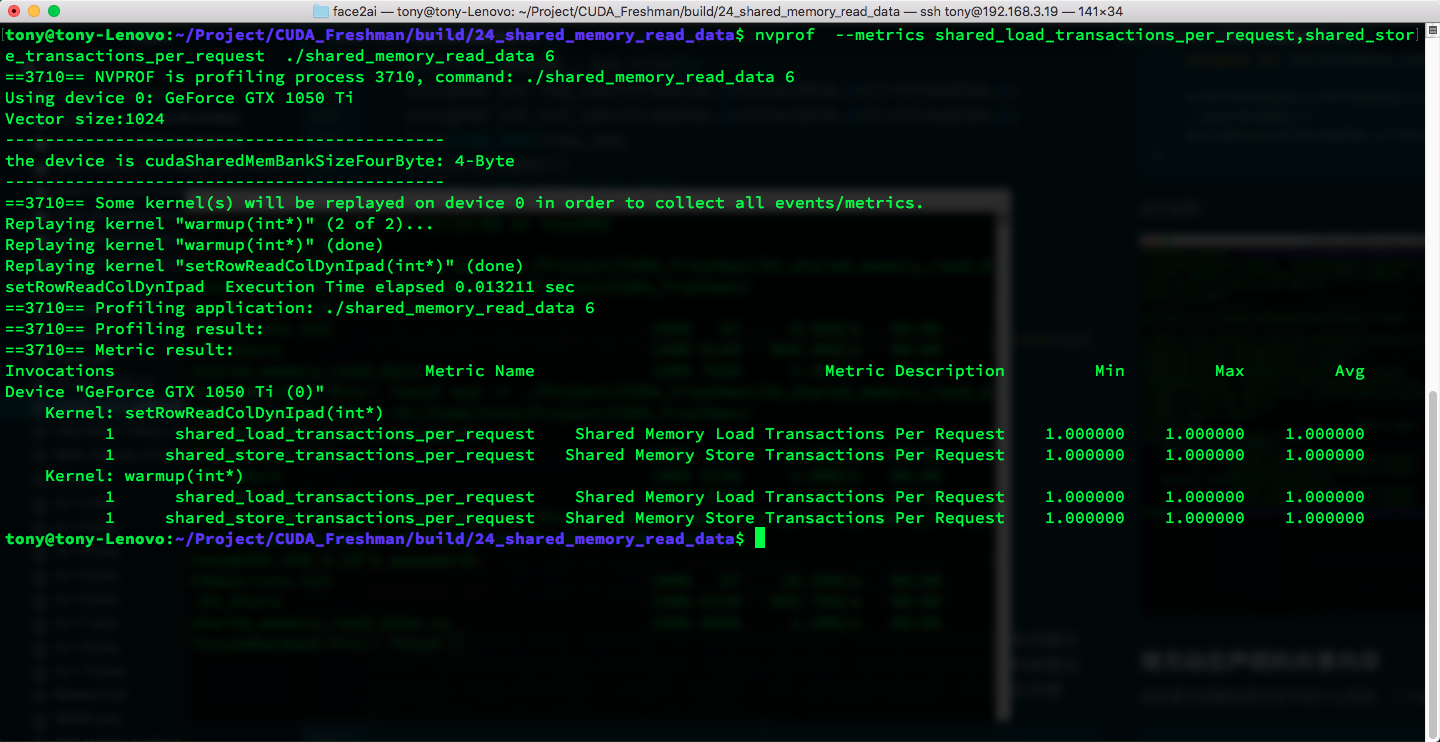
The conflict is gone! Padding works!
Square Shared Memory Kernel Performance Comparison
Next is comparing all kernels. We run directly:
sudo /usr/local/cuda/bin/nvprof ./shared_memory_read_data 11
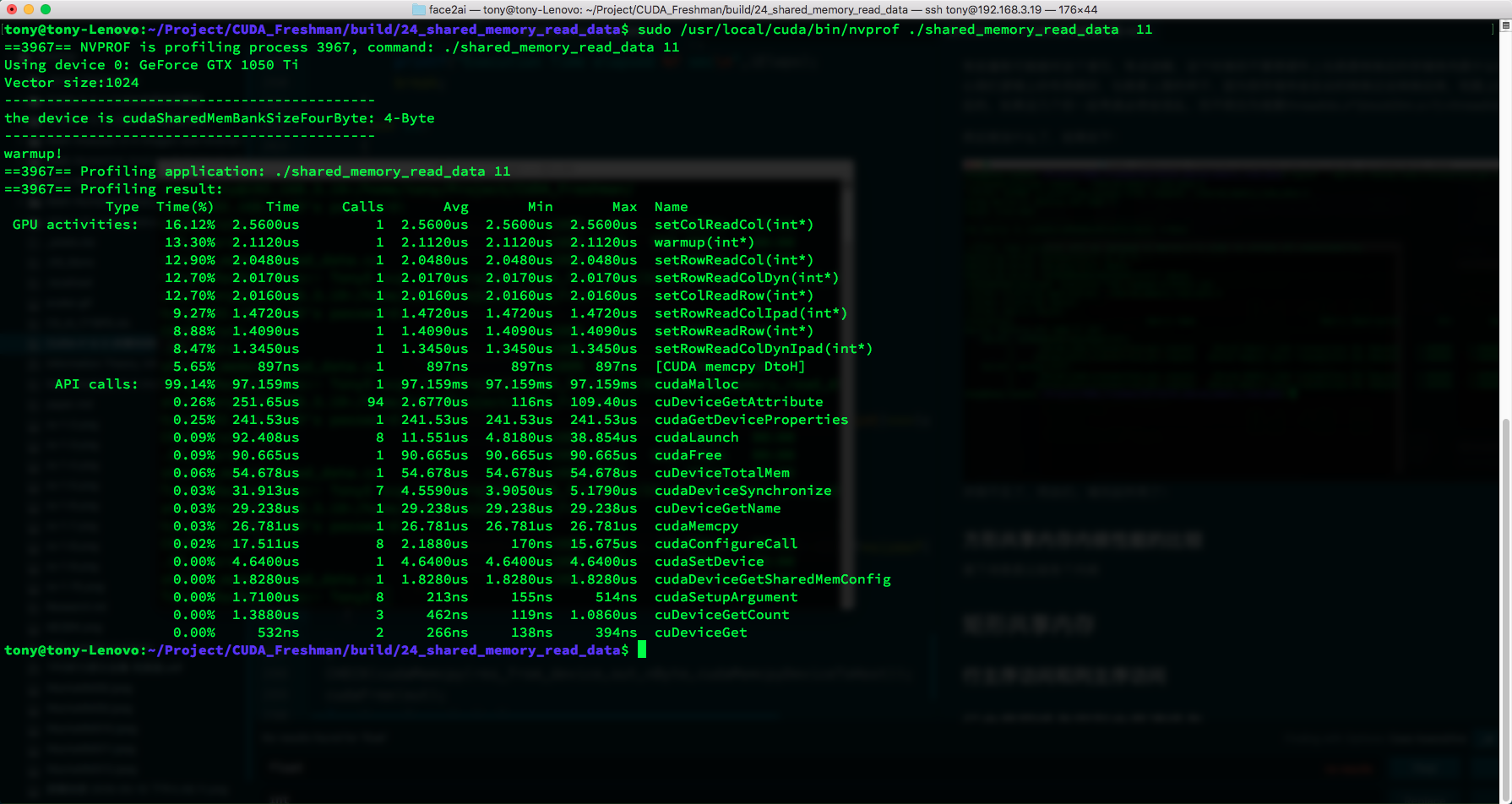
We can observe the execution time of all kernel functions:
| Type | Time(%) | Time | Calls | Avg | Min | Max | Name |
|---|---|---|---|---|---|---|---|
| GPU activities: | 16.12% | 2.5600us | 1 | 2.5600us | 2.5600us | 2.5600us | setColReadCol(int*) |
| 13.30% | 2.1120us | 1 | 2.1120us | 2.1120us | 2.1120us | warmup(int*) | |
| 12.90% | 2.0480us | 1 | 2.0480us | 2.0480us | 2.0480us | setRowReadCol(int*) | |
| 12.70% | 2.0170us | 1 | 2.0170us | 2.0170us | 2.0170us | setRowReadColDyn(int*) | |
| 12.70% | 2.0160us | 1 | 2.0160us | 2.0160us | 2.0160us | setColReadRow(int*) | |
| 9.27% | 1.4720us | 1 | 1.4720us | 1.4720us | 1.4720us | setRowReadColIpad(int*) | |
| 8.88% | 1.4090us | 1 | 1.4090us | 1.4090us | 1.4090us | setRowReadRow(int*) | |
| 8.47% | 1.3450us | 1 | 1.3450us | 1.3450us | 1.3450us | setRowReadColDynIpad(int*) |
I won't demonstrate the memory contents with code here. Shrink the declared memory size and print it out to see the results.
All of the above requires one thing to be clear and ingrained: what we declare is our programming model, but the actual storage is a different-shaped 2D bank layout. These two data distributions correspond one-to-one. When writing kernel functions for functionality, you only need to consider your programming model to get the correct answer. But optimization requires considering the relationship between the programming model and bank distribution. Proper padding yields good results.
Rectangular Shared Memory
The above covers squares. Rectangles are similar. If you master the correspondence between the programming model and banks, even triangular memory would not matter. But for completeness, let's write it out briefly.
Rectangular shared memory:
#define BDIMX_RECT 32
#define BDIMY_RECT 16
Different lengths make it rectangular. At this point, we need to consider non-square indexing. We cannot simply swap coordinates; instead, we need to use the approach mentioned above: convert to linear first, then recalculate row and column coordinates.
Row-Major and Column-Major Access
This is exactly the same as the square case, so we won't elaborate. Only the shared memory size was adjusted; nothing else changed. We focus on cases that require coordinate conversion -- reading by row and writing by column, or vice versa.
Row-Major Write and Column-Major Read
This is the complex case. Let's look at the code first, then study it:
__global__ void setRowReadColRect(int * out)
{
__shared__ int tile[BDIMY_RECT][BDIMX_RECT];
unsigned int idx=threadIdx.y*blockDim.x+threadIdx.x;
unsigned int icol=idx%blockDim.y;
unsigned int irow=idx/blockDim.y;
tile[threadIdx.y][threadIdx.x]=idx;
__syncthreads();
out[idx]=tile[icol][irow];
}
Explanation:
First, the diagram:
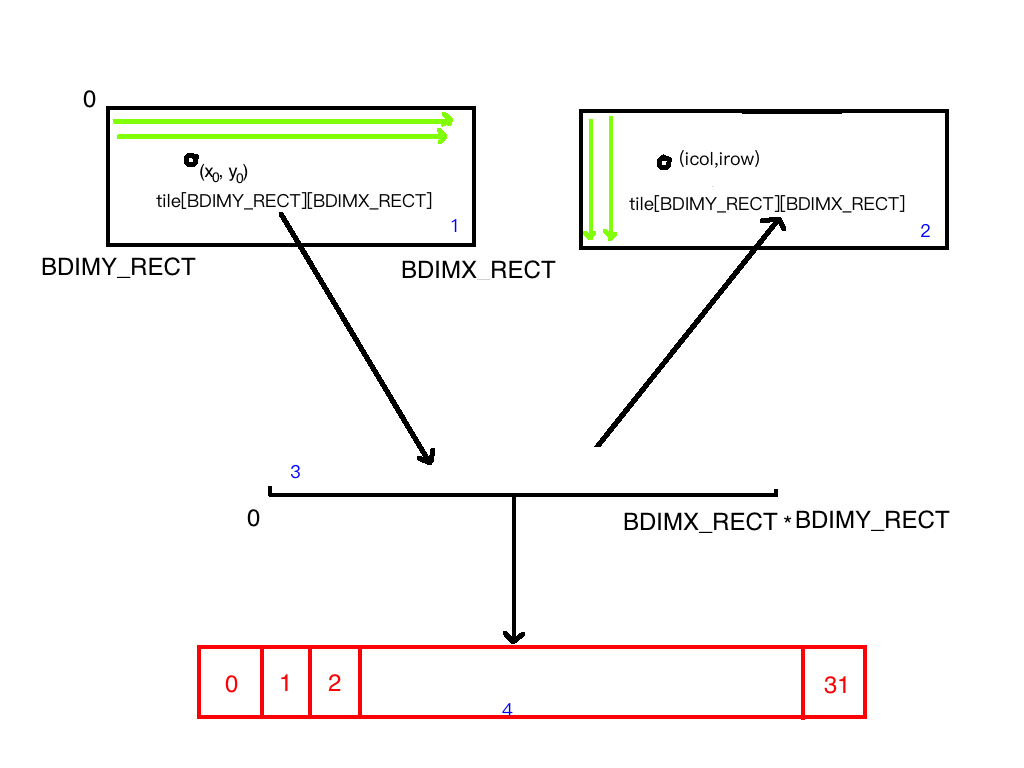
Note: red is the bank space; blue labels 1, 2, 3, 4 represent four different models.
unsigned int idx=threadIdx.y*blockDim.x+threadIdx.x;
This calculates the linear position because we map different-sized shared memory into the linear space (1->3 process). Then:
unsigned int icol=idx%blockDim.y;
unsigned int irow=idx/blockDim.y;
This is the 3->2 process. Many may not understand -- honestly, I didn't either at first. But after careful study: we did not change the original tile's shape. We only changed the array's index order. Originally we followed the green line in 1 from left to right, row by row. Through division and modulo, the new coordinates follow the green arrow in 3 from top to bottom, column by column. So when the x-direction coordinate in 1 increases by one, it corresponds to the y-direction coordinate in 3 increasing by one. The array's shape does not change -- this results in one being row-write and one being column-read.
However, instead of the 32 conflicts in the square case, there are only 16 conflicts. Because each row of 32 elements corresponds to two columns, resulting in 16 conflicts.
Result:
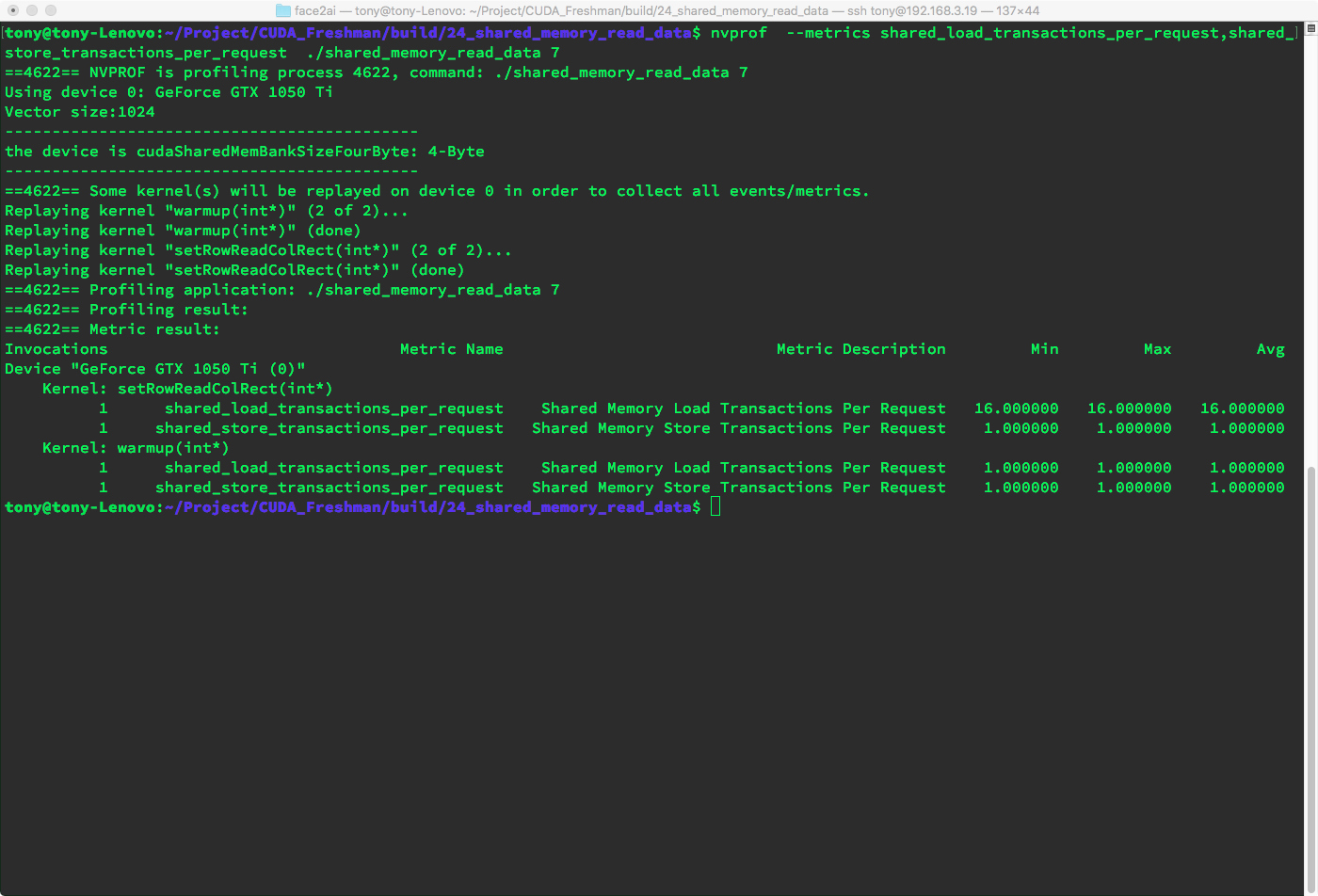
As we predicted, 16-way conflicts appear during load.
Dynamically Declared Shared Memory
Next is the dynamic version. Basically no difference.
Code:
__global__ void setRowReadColRectDyn(int * out)
{
extern __shared__ int tile[];
unsigned int idx=threadIdx.y*blockDim.x+threadIdx.x;
unsigned int icol=idx%blockDim.y;
unsigned int irow=idx/blockDim.y;
unsigned int col_idx=icol*blockDim.x+irow;
tile[idx]=idx;
__syncthreads();
out[idx]=tile[col_idx];
}
Kernel launch:
setRowReadColRectDynPad<<<grid_rect,block_rect,(BDIMX+1)*BDIMY*sizeof(int)>>>(out);
Similar to the square case. Results:
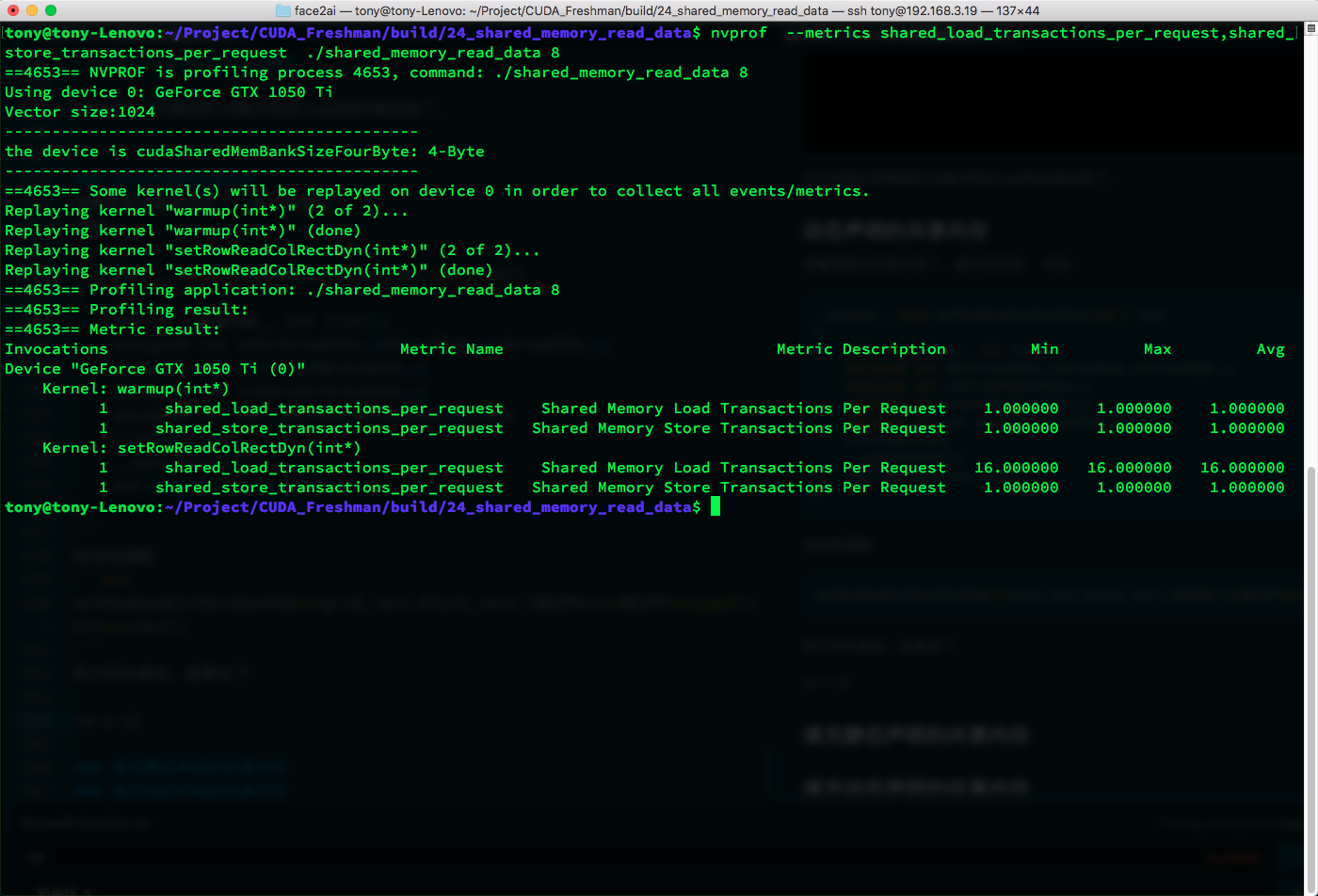
Results are consistent with static memory.
Padding Statically Declared Shared Memory
Then we pad the memory. When padding, we need to pay attention to index calculations, but no adjustments are needed.
Code:
__global__ void setRowReadColRectPad(int * out)
{
__shared__ int tile[BDIMY_RECT][BDIMX_RECT+IPAD];
unsigned int idx=threadIdx.y*blockDim.x+threadIdx.x;
unsigned int icol=idx%blockDim.y;
unsigned int irow=idx/blockDim.y;
tile[threadIdx.y][threadIdx.x]=idx;
__syncthreads();
out[idx]=tile[icol][irow];
}
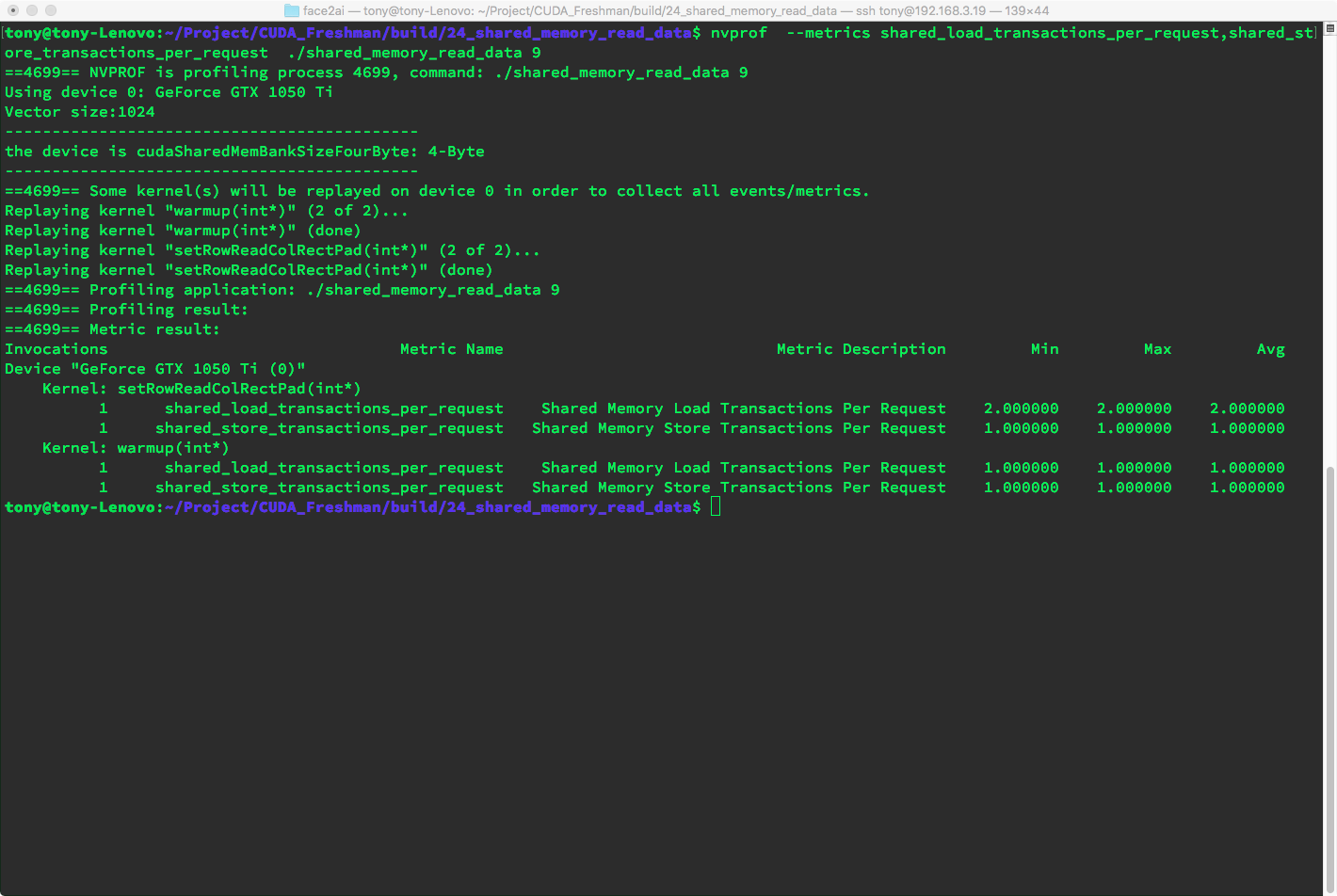
Result: with one column of padding, we only produce two-way conflicts.
With two columns of padding, the code is:
__global__ void setRowReadColRectPad(int * out)
{
__shared__ int tile[BDIMY_RECT][BDIMX_RECT+IPAD*2];
unsigned int idx=threadIdx.y*blockDim.x+threadIdx.x;
unsigned int icol=idx%blockDim.y;
unsigned int irow=idx/blockDim.y;
tile[threadIdx.y][threadIdx.x]=idx;
__syncthreads();
out[idx]=tile[icol][irow];
}
Result -- no conflicts:
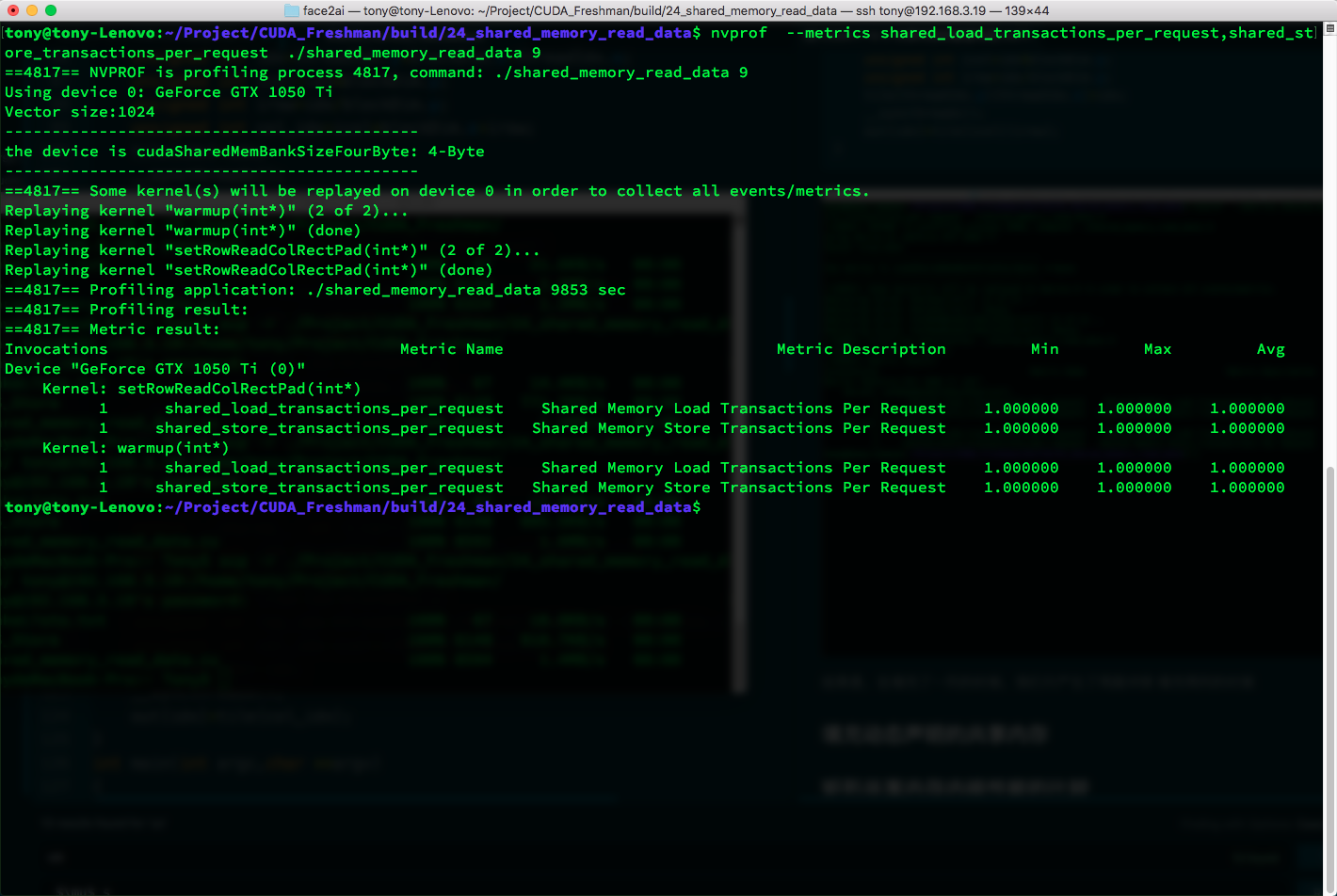
If you don't understand why, draw a diagram yourself: convert from the rectangle to the bank space and trace through the execution process.
Padding Dynamically Declared Shared Memory
Dynamic padding is similar to the square dynamic padding. The tile no longer has 2D indexing, so you need to calculate the 1D position corresponding to 2D indices. Otherwise similar:
__global__ void setRowReadColRectDynPad(int * out)
{
extern __shared__ int tile[];
unsigned int idx=threadIdx.y*blockDim.x+threadIdx.x;
unsigned int icol=idx%blockDim.y;
unsigned int irow=idx/blockDim.y;
unsigned int row_idx=threadIdx.y*(IPAD+blockDim.x)+threadIdx.x;
unsigned int col_idx=icol*(IPAD+blockDim.x)+irow;
tile[row_idx]=idx;
__syncthreads();
out[idx]=tile[col_idx];
}
Index conversion and 2D-to-1D coordinate mapping are techniques used previously. For adding 1 column, we get two-way conflicts, consistent with the static padding above.
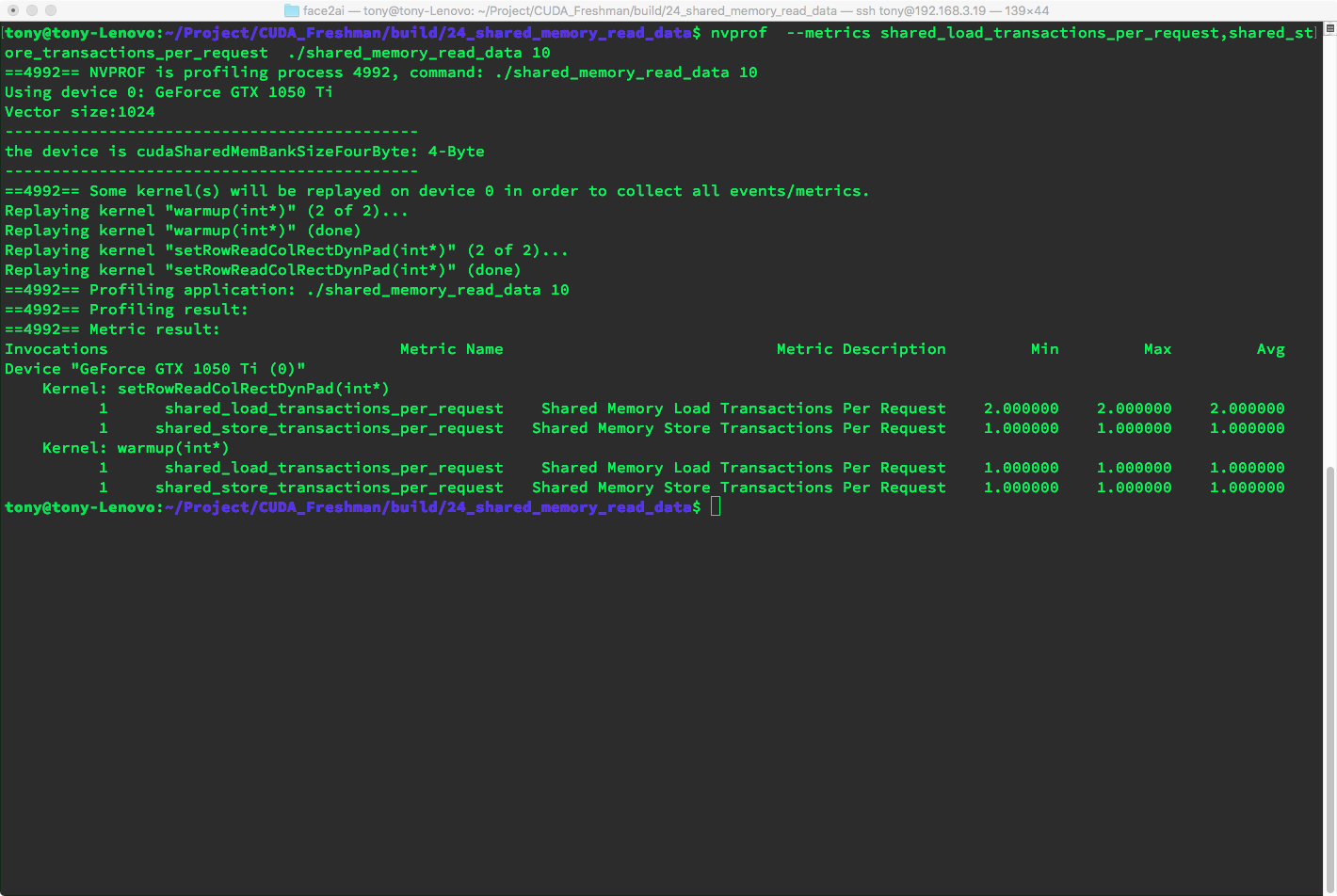
Rectangular Shared Memory Kernel Performance Comparison
Comparison of all rectangular kernel function results:
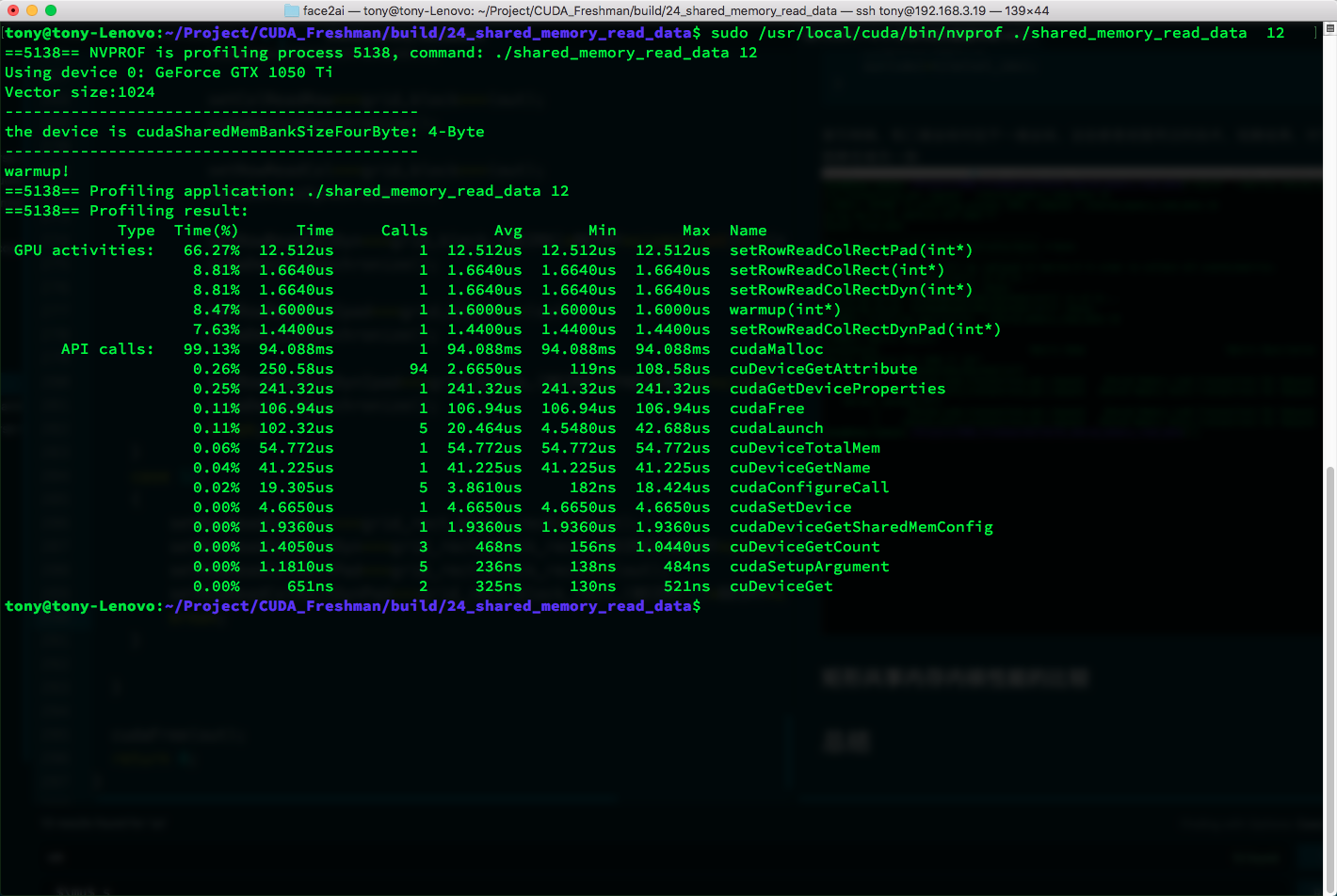
| Type | Time(%) | Time | Calls | Avg | Min | Max | Name |
|---|---|---|---|---|---|---|---|
| GPU activities: | 66.27% | 12.512us | 1 | 12.512us | 12.512us | 12.512us | setRowReadColRectPad(int*) |
| 8.81% | 1.6640us | 1 | 1.6640us | 1.6640us | 1.6640us | setRowReadColRect(int*) | |
| 8.81% | 1.6640us | 1 | 1.6640us | 1.6640us | 1.6640us | setRowReadColRectDyn(int*) | |
| 8.47% | 1.6000us | 1 | 1.6000us | 1.6000us | 1.6000us | warmup(int*) | |
| 7.63% | 1.4400us | 1 | 1.4400us | 1.4400us | 1.4400us | setRowReadColRectDynPad(int*) |
Summary
Through a series of experiments, this article demonstrates the intra-bank distribution of shared memory data, how to use dynamic shared memory, and how to use padding to avoid conflicts.