5.3 Reducing Global Memory Accesses
Published on 2018-06-04 | Category: CUDA , Freshman | Comments: 0 | Views:
Abstract: This article introduces using shared memory for reduction and compares the performance difference between global memory reduction and shared memory reduction.
Keywords: Shared Memory, Reduction
Reducing Global Memory Accesses
Logic is very important. Once you learn logic, you can easily identify many false things, making you stronger and not susceptible to brainwashing by anyone or any organization.
Let's get started with today's blog post.
The primary reason for using shared memory is to reduce global memory accesses and minimize unnecessary latency. In Chapter 3, we learned about reduction. You can refer to:
These two blog posts contain various techniques we previously used for reduction with global memory. Today we will also use some of that code for comparison to demonstrate the advantages of shared memory.
We will focus on solving the following two problems:
- How to rearrange data access patterns to avoid warp divergence
- How to unroll loops to ensure sufficient operations to saturate instruction and memory bandwidth
In this article, we analyze why shared memory should be used and how to use it by comparing with some of the previous code.
Parallel Reduction with Shared Memory
Let's first recall the fully unrolled reduction computation using global memory:
__global__ void reduceGmem(int * g_idata,int * g_odata,unsigned int n)
{
//set thread ID
unsigned int tid = threadIdx.x;
unsigned int idx = blockDim.x*blockIdx.x+threadIdx.x;
//boundary check
if (tid >= n) return;
//convert global data pointer to the
int *idata = g_idata + blockIdx.x*blockDim.x;
//in-place reduction in global memory
if(blockDim.x>=1024 && tid <512)
idata[tid]+=idata[tid+512];
__syncthreads();
if(blockDim.x>=512 && tid <256)
idata[tid]+=idata[tid+256];
__syncthreads();
if(blockDim.x>=256 && tid <128)
idata[tid]+=idata[tid+128];
__syncthreads();
if(blockDim.x>=128 && tid <64)
idata[tid]+=idata[tid+64];
__syncthreads();
//write result for this block to global mem
if(tid<32)
{
volatile int *vmem = idata;
vmem[tid]+=vmem[tid+32];
vmem[tid]+=vmem[tid+16];
vmem[tid]+=vmem[tid+8];
vmem[tid]+=vmem[tid+4];
vmem[tid]+=vmem[tid+2];
vmem[tid]+=vmem[tid+1];
}
if (tid == 0)
g_odata[blockIdx.x] = idata[0];
}
The next step calculates the current thread's index position:
unsigned int idx = blockDim.x*blockIdx.x+threadIdx.x;
The starting address of the data block corresponding to the current thread block:
int *idata = g_idata + blockIdx.x*blockDim.x;
Then the unrolled loop section. tid is the thread index within the current thread block, mainly distinguished from the global index idx:
if(blockDim.x>=1024 && tid <512)
idata[tid]+=idata[tid+512];
__syncthreads();
if(blockDim.x>=512 && tid <256)
idata[tid]+=idata[tid+256];
__syncthreads();
if(blockDim.x>=256 && tid <128)
idata[tid]+=idata[tid+128];
__syncthreads();
if(blockDim.x>=128 && tid <64)
idata[tid]+=idata[tid+64];
__syncthreads();
This step reduces all data in the current thread block to the first 64 elements. Then the following code reduces the last 64 elements into one:
if(tid<32)
{
volatile int *vmem = idata;
vmem[tid]+=vmem[tid+32];
vmem[tid]+=vmem[tid+16];
vmem[tid]+=vmem[tid+8];
vmem[tid]+=vmem[tid+4];
vmem[tid]+=vmem[tid+2];
vmem[tid]+=vmem[tid+1];
}
Note that a volatile variable is declared here. If we do not do this, the compiler cannot guarantee that these data read/write operations execute in the order specified in the code (refer to Section 5.1 regarding compiler data transfer). Therefore, this is necessary.
Then we execute the following code. Although it was executed before, we run it again to observe the results:
The complete executable code can still be found on GitHub.
GitHub: https://github.com/Tony-Tan/CUDA_Freshman -- a star would not be too much trouble, please!
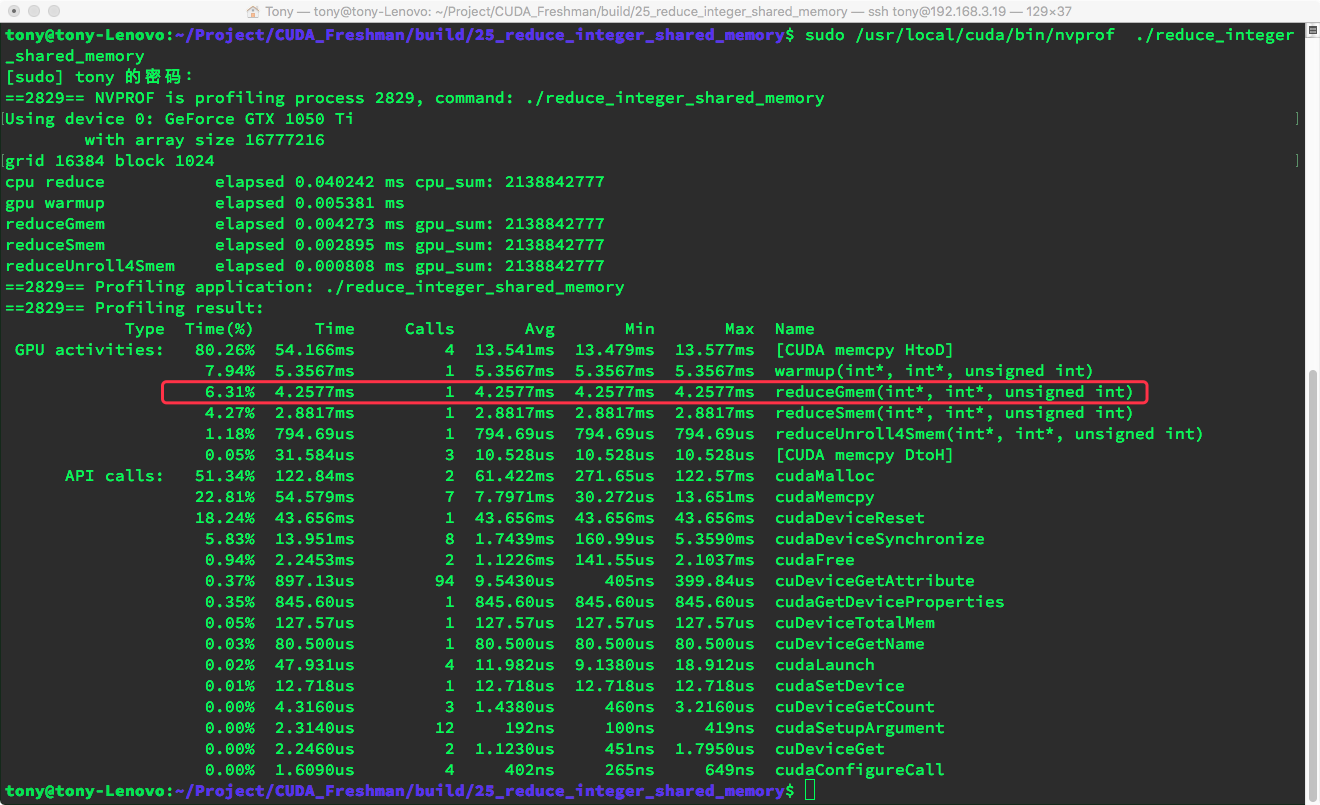
Let's pretend we only look at our kernel function. The execution time is about 4.25ms.
Then we rewrite the above code into a shared memory version:
__global__ void reduceSmem(int * g_idata,int * g_odata,unsigned int n)
{
//set thread ID
__shared__ int smem[DIM];
unsigned int tid = threadIdx.x;
//unsigned int idx = blockDim.x*blockIdx.x+threadIdx.x;
//boundary check
if (tid >= n) return;
//convert global data pointer to the
int *idata = g_idata + blockIdx.x*blockDim.x;
smem[tid]=idata[tid];
__syncthreads();
//in-place reduction in global memory
if(blockDim.x>=1024 && tid <512)
smem[tid]+=smem[tid+512];
__syncthreads();
if(blockDim.x>=512 && tid <256)
smem[tid]+=smem[tid+256];
__syncthreads();
if(blockDim.x>=256 && tid <128)
smem[tid]+=smem[tid+128];
__syncthreads();
if(blockDim.x>=128 && tid <64)
smem[tid]+=smem[tid+64];
__syncthreads();
//write result for this block to global mem
if(tid<32)
{
volatile int *vsmem = smem;
vsmem[tid]+=vsmem[tid+32];
vsmem[tid]+=vsmem[tid+16];
vsmem[tid]+=vsmem[tid+8];
vsmem[tid]+=vsmem[tid+4];
vsmem[tid]+=vsmem[tid+2];
vsmem[tid]+=vsmem[tid+1];
}
if (tid == 0)
g_odata[blockIdx.x] = smem[0];
}
The only difference is the addition of a shared memory declaration, threads writing global memory data to shared memory, and the subsequent synchronization instruction:
smem[tid]=idata[tid];
__syncthreads();
After this step, synchronization ensures all threads within the thread block reach this point before continuing. This is understandable because our reduction is only within the block. If you want to execute across multiple blocks, synchronization here would be problematic -- that was discussed in the previous lesson. We then see a volatile pointer to shared memory reducing the final 64 results. The entire process is identical to global memory reduction, just operating on shared memory instead of global memory, yielding the same results. Let's look at the execution results:
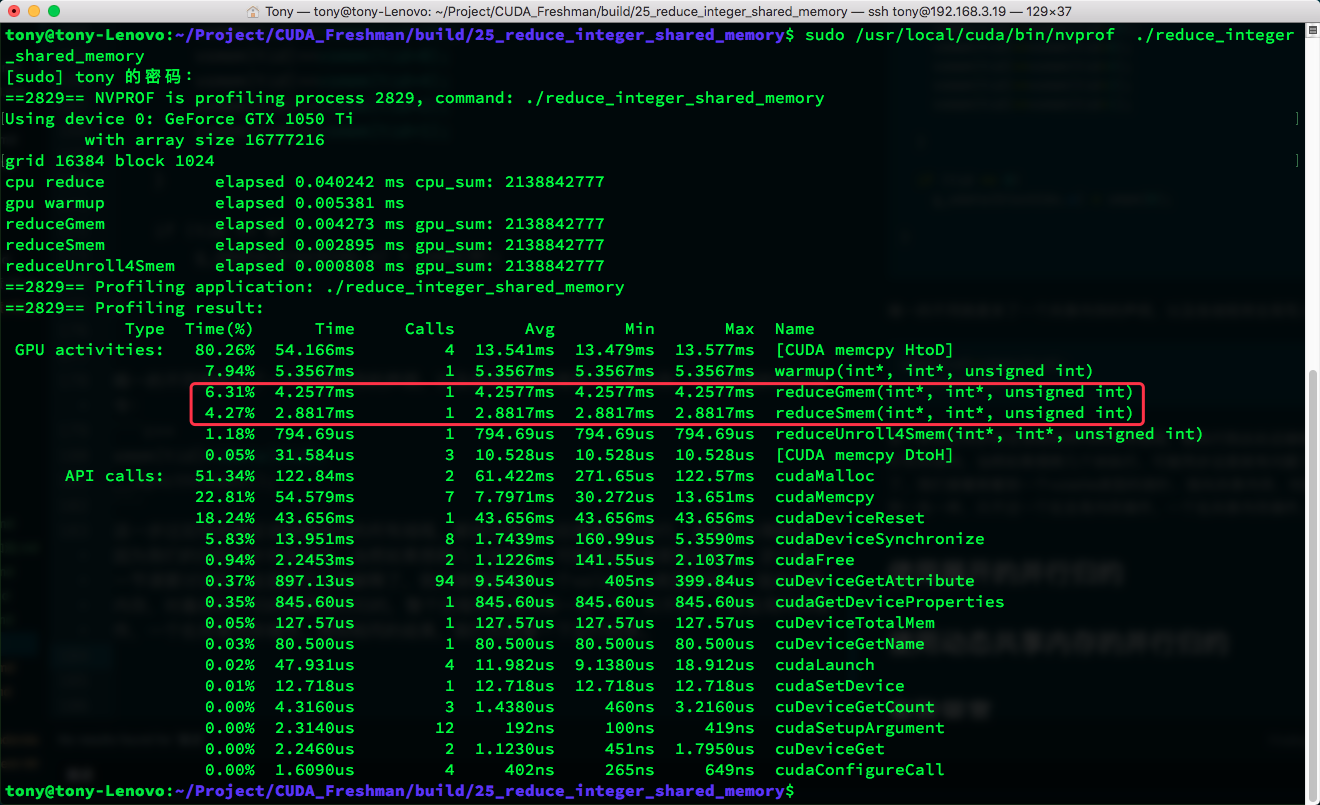
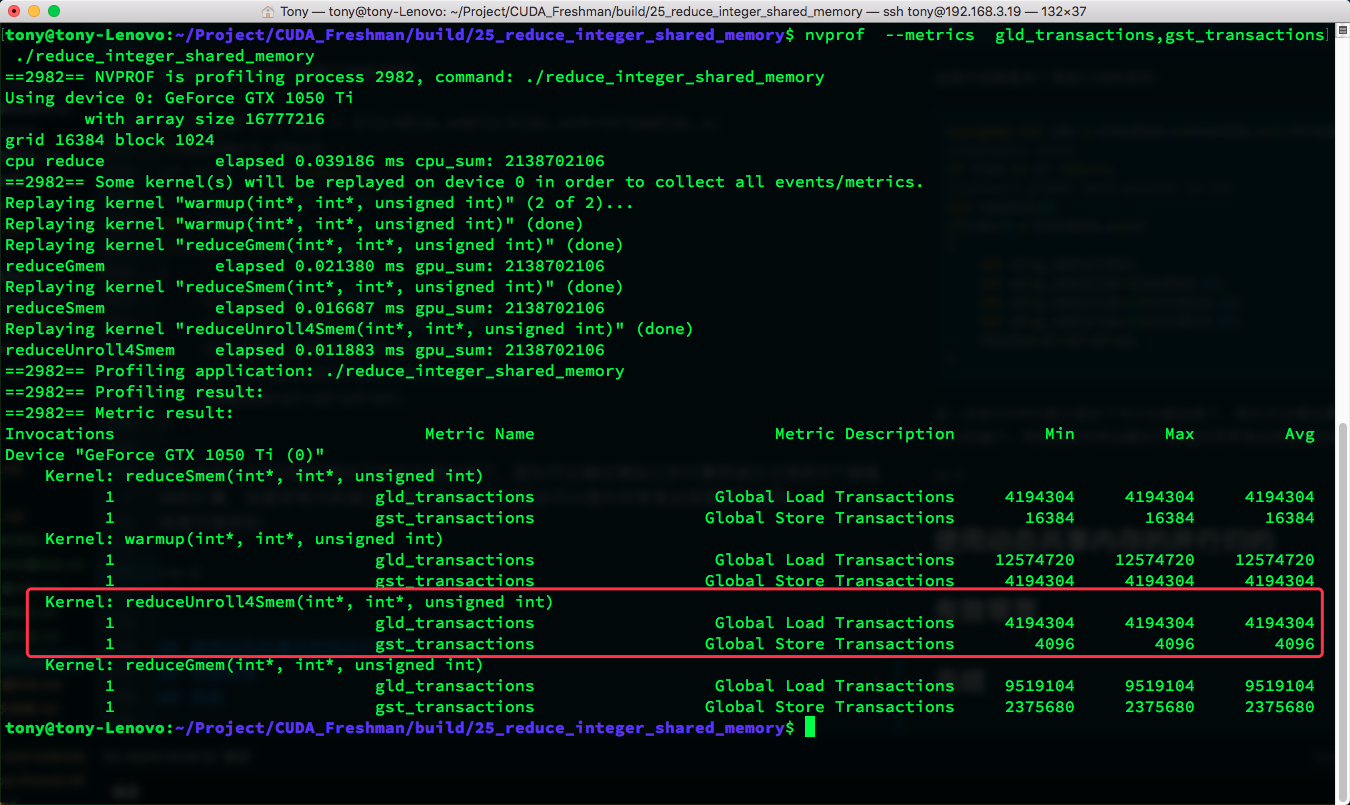
The same diagram shows a significant speed improvement when comparing. Let's look at:
gld_transactions
gst_transactions
Results for these two metrics:
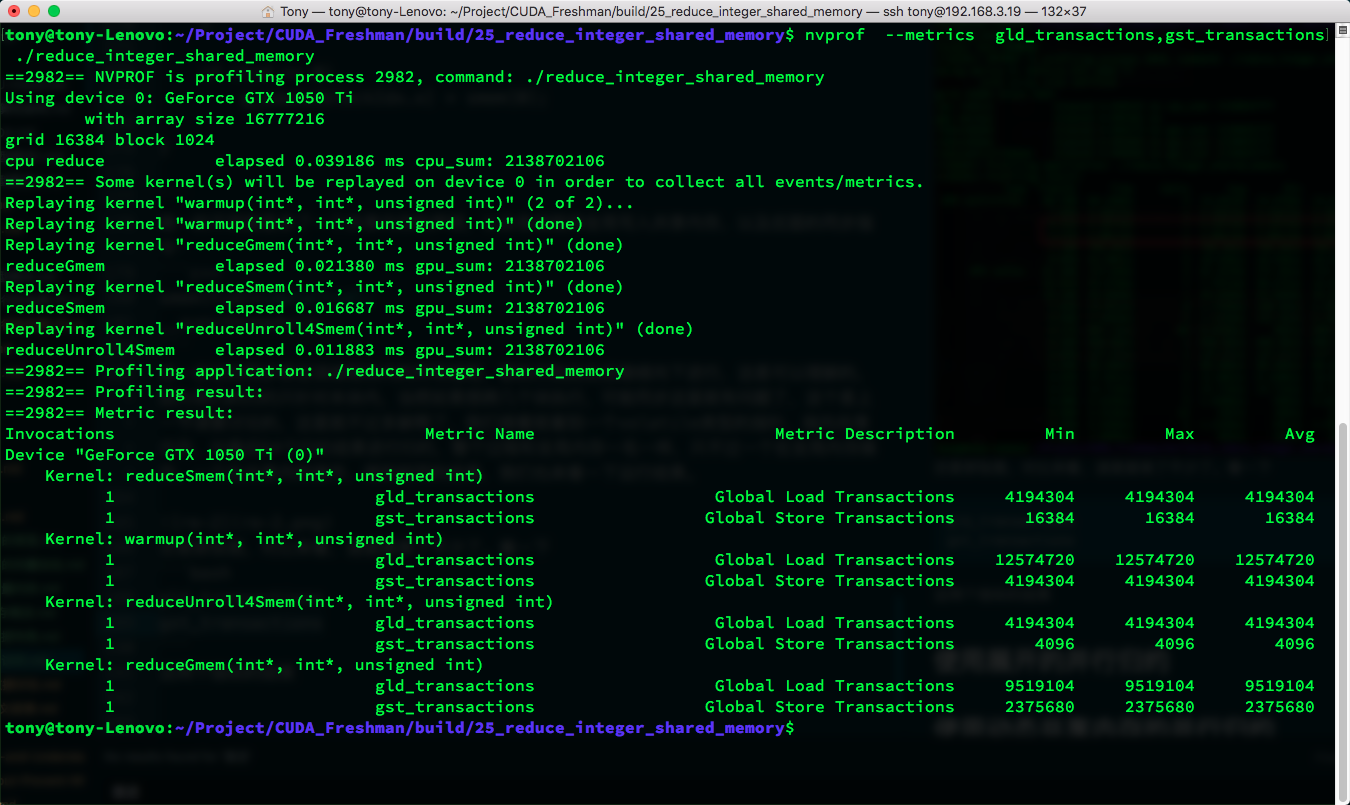
We can see that the number of global memory access transactions using shared memory is much lower than using global memory.
Parallel Reduction with Unrolling
Looking at the screenshot above, you may already know I will now parallelize 4 blocks. As mentioned earlier, shared memory cannot parallelize across 4 blocks because there is no way to synchronize across them. Here we still use the old method to parallelize 4 blocks: before writing to shared memory, reduce 4 blocks into 1, then store this one into shared memory for regular shared memory reduction:
__global__ void reduceUnroll4Smem(int * g_idata,int * g_odata,unsigned int n)
{
//set thread ID
__shared__ int smem[DIM];
unsigned int tid = threadIdx.x;
unsigned int idx = blockDim.x*blockIdx.x*4+threadIdx.x;
//boundary check
if (tid >= n) return;
//convert global data pointer to the
int tempSum=0;
if(idx+3 * blockDim.x<=n)
{
int a1=g_idata[idx];
int a2=g_idata[idx+blockDim.x];
int a3=g_idata[idx+2*blockDim.x];
int a4=g_idata[idx+3*blockDim.x];
tempSum=a1+a2+a3+a4;
}
smem[tid]=tempSum;
__syncthreads();
//in-place reduction in global memory
if(blockDim.x>=1024 && tid <512)
smem[tid]+=smem[tid+512];
__syncthreads();
if(blockDim.x>=512 && tid <256)
smem[tid]+=smem[tid+256];
__syncthreads();
if(blockDim.x>=256 && tid <128)
smem[tid]+=smem[tid+128];
__syncthreads();
if(blockDim.x>=128 && tid <64)
smem[tid]+=smem[tid+64];
__syncthreads();
//write result for this block to global mem
if(tid<32)
{
volatile int *vsmem = smem;
vsmem[tid]+=vsmem[tid+32];
vsmem[tid]+=vsmem[tid+16];
vsmem[tid]+=vsmem[tid+8];
vsmem[tid]+=vsmem[tid+4];
vsmem[tid]+=vsmem[tid+2];
vsmem[tid]+=vsmem[tid+1];
}
if (tid == 0)
g_odata[blockIdx.x] = smem[0];
}
This code adds the sum from the other three blocks:
unsigned int idx = blockDim.x*blockIdx.x*4+threadIdx.x;
//boundary check
if (tid >= n) return;
//convert global data pointer to the
int tempSum=0;
if(idx+3 * blockDim.x<=n)
{
int a1=g_idata[idx];
int a2=g_idata[idx+blockDim.x];
int a3=g_idata[idx+2*blockDim.x];
int a4=g_idata[idx+3*blockDim.x];
tempSum=a1+a2+a3+a4;
}
This step was already explained in Section 3.5 -- it can accelerate by adding three computation steps to eliminate the previous 3 thread blocks of computation, which is a huge reduction. Meanwhile, multi-step memory loading also achieves better memory bandwidth utilization.
Results:
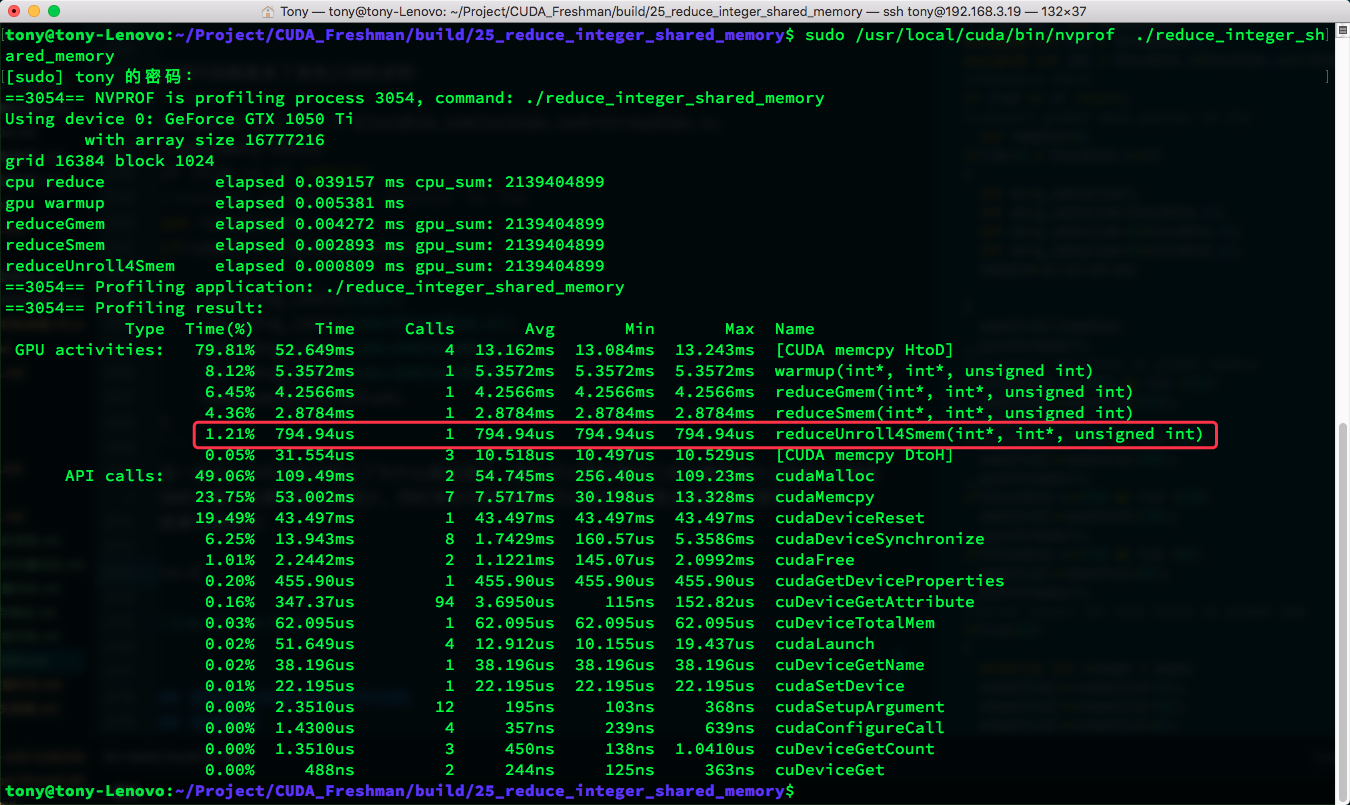
Throughput metrics:
nvprof --metrics dram_read_throughput ./reduce_integer_shared_memory
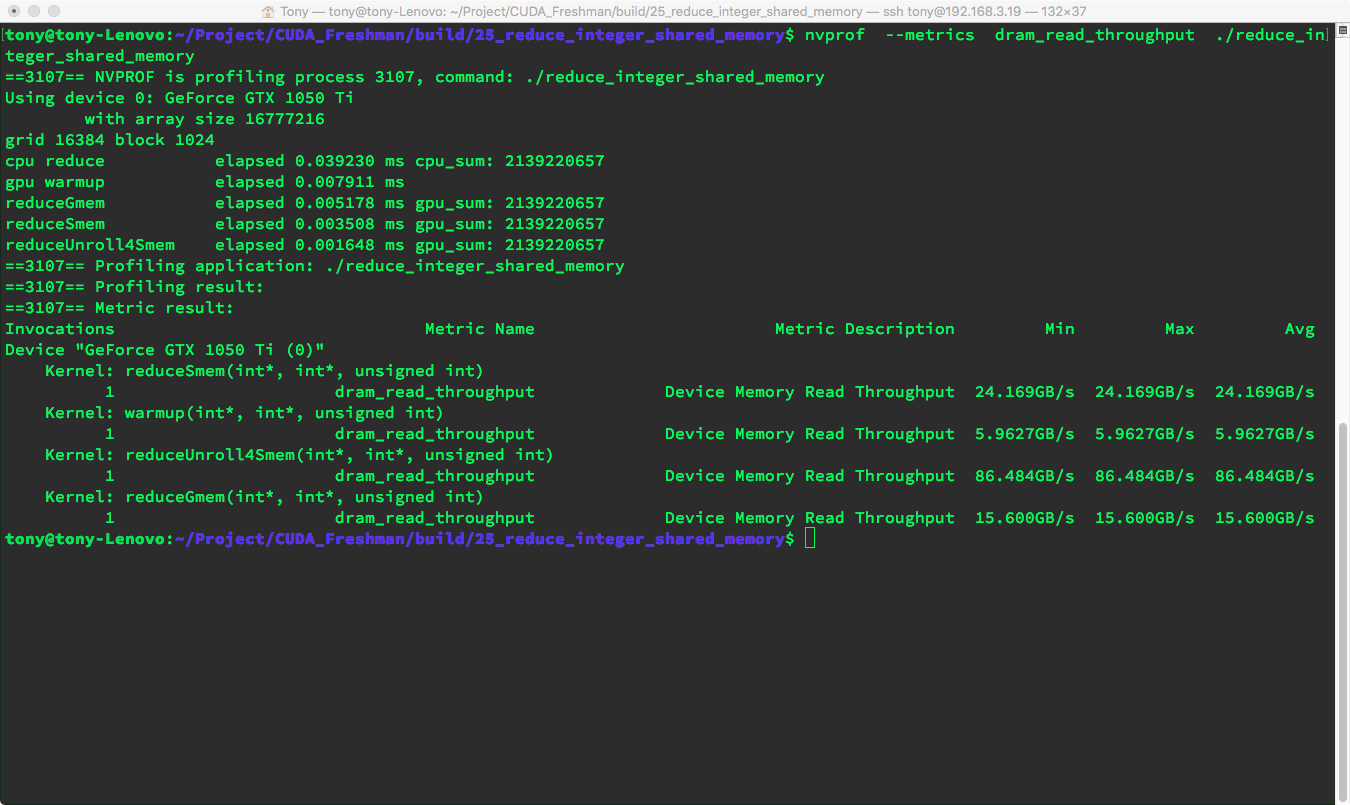
Both metrics and execution speed show very significant improvement.
Let's summarize the advantages of unrolling:
- I/O achieves more parallelism -- better bandwidth utilization and increased throughput
- Global memory store transactions reduced to 14, mainly for the final step of storing results to global memory
- Massive overall performance improvement
Parallel Reduction with Dynamic Shared Memory
Next, let's look at the dynamic version. There is not much to see -- it is just written differently, replacing the macro with kernel configuration parameters. Just remember the unit is bytes -- do not forget sizeof().
We will not elaborate further here.
Effective Bandwidth
Let's compare the data and review our effective bandwidth calculation formula (detailed in Section 4.4):

Effective Bandwidth = (Bytes Read + Bytes Written) x 10^(-9) / Execution Time ... (1)
You can study the effective bandwidth of the three kernel functions. We will not calculate each one here, as this was already taught in Section 4.4. Calculate it yourself and draw your own conclusions.
Summary
This article mainly shows how to use shared memory to accelerate reduction and how combining shared memory with unrolling can further improve efficiency. Pay attention to synchronization within thread blocks -- this is important.