Ding Zhiyu Week 1 Study Report
Table of Contents
[TOC]
OpenMP
Commonly Used Library Functions
// 设置并行区运行的线程数
void omp set num threads(int)
// 获得并行区运行的线程数i
nt omp_get num threads(void)
// 得线程编号
int omp_get_thread num(void)
// 获得openmp walL cLock时间(单位秒)
double omp_get_wtime(void)
// 获得omp_get_wtime时间精度
double omp_get_wtick(void)
Parallel Construct, For Construct
Common Directives
#pragma omp parallel: Starts a new parallel region, creating a team that contains multiple threads.#pragma omp for: Indicates a loop that can be executed in parallel (e.g., a for loop in C/C++). It decomposes the loop body into multiple tasks and executes them across multiple threads. This directive must be placed inside an already-created parallel region.#pragma omp parallel for: This directive combines the functionality of both "parallel" and "for". First,#pragma omp parallelstarts a new parallel region, creating a team of multiple threads. Then, the "for" part parallelizes the specified loop across the newly created thread team. Therefore,#pragma omp parallel fornot only executes the loop in parallel but also ensures a proper parallel environment for executing the loop.
Clauses Supported by parallel for
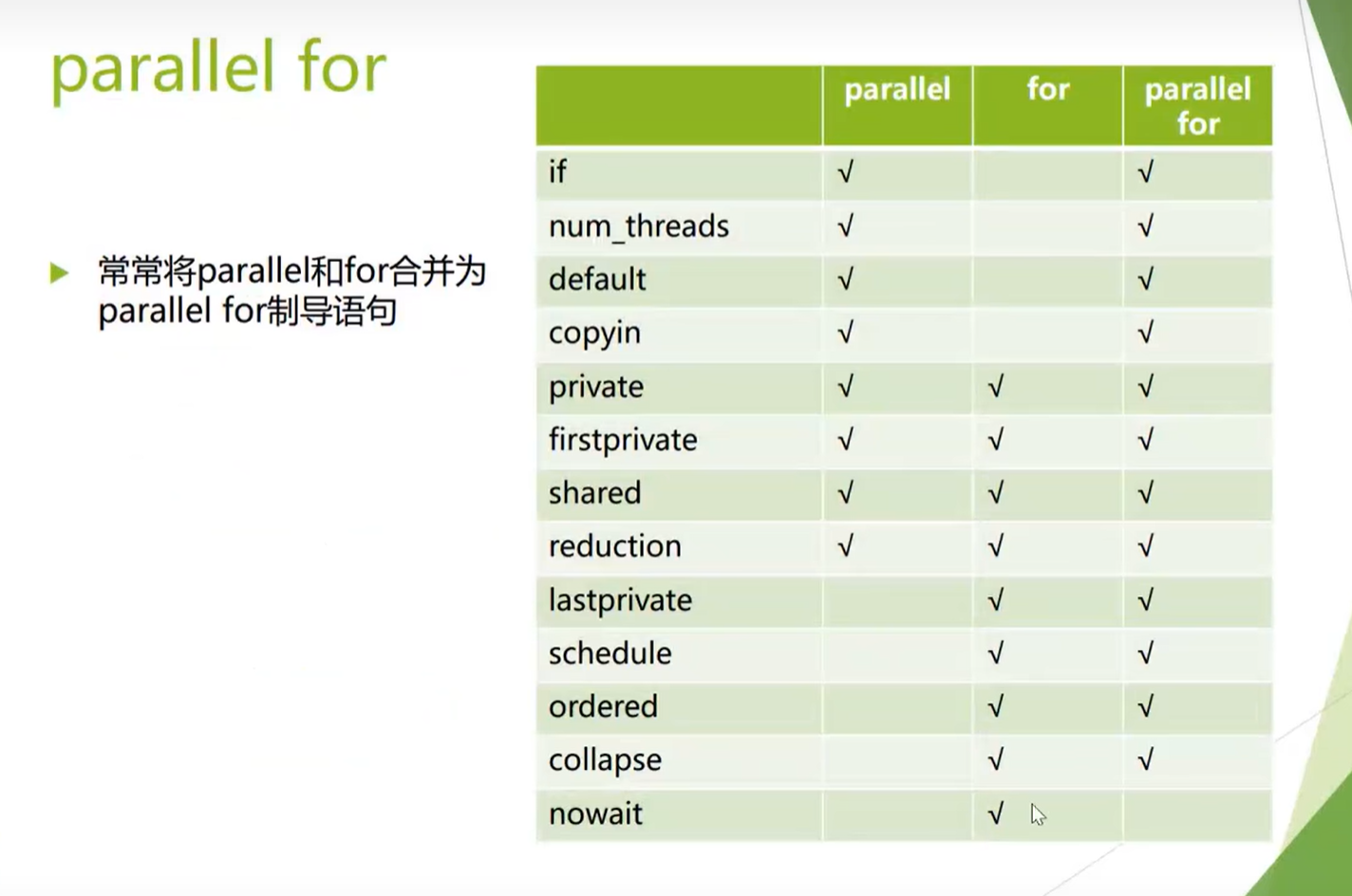
#pragma omp parallel (+ Clauses)
if(scalar expression): Determines whether to execute the parallel region in parallel mode
- If the expression is true (non-zero): Execute the parallel region in parallel mode
- Otherwise: The main thread executes the parallel region serially
num threads(integer expression): Specifies the number of threads for the parallel region
private(list): Specifies a list of private variables
- Each thread creates a data object of the same type as the private variable
- Variables need to be re-initialized
firstprivate(list):
- Same as private
- Variables are initialized based on data from the main thread
#pragma omp for (+ Clauses)
- The nowait clause cancels implicit synchronization
- The collapse(n) clause handles nested loops
- The order clause enforces a certain order on loops within the parallel region
- The reduction clause simplifies operations on shared variables
The schedule() Clause Defines How Loop Iterations Are Distributed to Threads
In OpenMP, the schedule clause is used to specify how the iterations of a parallel loop are distributed among multiple threads. This is very important for load balancing, especially when the work per loop iteration is uneven. The schedule clause can be applied to #pragma omp for or #pragma omp parallel for directives. Below are several different types of schedule clauses:
- Static schedule
This type of scheduling divides iterations into chunks of size#pragma omp for schedule(static[, chunk])
chunkand statically assigns them to threads. If nochunksize is specified, by default the number of loop iterations is divided by the number of threads, and each thread gets approximately equal iterations. If achunksize is specified, each thread receives iterations in units ofchunk. - Dynamic schedule
#pragma omp for schedule(dynamic[, chunk])
dynamicscheduling allows threads to dynamically claim new work chunks from the iteration pool after completing their assigned iterations. Thechunksize is optional; if not specified, the default is to claim new iteration blocks one at a time. - Guided schedule
In#pragma omp for schedule(guided[, chunk])
guidedscheduling, the initialchunksize is large but decreases as the algorithm progresses. In short, initially, when there is a large amount of available work, threads claim larger chunks of iterations, but as the work nears completion, the chunk size gradually decreases to avoid some threads being overworked while others are idle. Thechunksize sets a lower bound to prevent chunks from becoming too small. - Auto schedule
#pragma omp for schedule(auto)
autoscheduling delegates the decision to the compiler and runtime system, which choose the best scheduling method based on the code and system conditions. Here is a simple example ofscheduleusage:
#pragma omp parallel for schedule(dynamic, 10)
for(int i = 0; i < N; i++) {
// 处理迭代中的代码
}
In this example, the loop iterations are dynamically distributed to threads, with each chunk being of size 10. This means threads will execute a task of 10 iterations, then return to the loop's iteration pool to get the next chunk of 10 iterations, until all iterations are completed.
The use of the schedule clause depends on the algorithm characteristics and workload situation. Proper use of schedule can significantly improve the performance and efficiency of parallel programs.
Reduction
OpenMP is an API that supports multi-platform shared memory parallel programming. It can be used with C, C++, and Fortran. In OpenMP, reduction is a directive used for accumulating variables in a parallel region, such as summing, finding products, or finding maximum/minimum values.
When you use the reduction directive in a parallel region, each thread gets its own private copy. These threads operate on their private copies, and at the end of the parallel region, all private copies are combined ("reduced") and updated into the original variable.
The syntax for OpenMP's reduction directive is as follows:
#pragma omp parallel for reduction(operator:variable)
Where the operator can be one of the following:
+: Sum*: Product-: Difference (Note: subtraction within a parallel region is generally not associative, so the result may depend on thread execution order)&: Bitwise AND|: Bitwise OR^: Bitwise XOR&&: Logical AND||: Logical ORmax: Maximummin: Minimum
Below is an example using the OpenMP reduction directive that calculates the sum of all elements in an array:
#include <stdio.h>
#include <omp.h>
int main() {
int arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int sum = 0;
int i;
#pragma omp parallel for reduction(+:sum)
for (i = 0; i < 10; i++) {
sum += arr[i];
}
printf("Sum = %d\n", sum);
return 0;
}
In this example, the sum variable is the reduced variable, and the + operator indicates we want to sum the elements of the array. The #pragma omp parallel for reduction(+:sum) directive tells OpenMP to create a parallel region where loop iterations are distributed across different threads. Each thread has its own copy of sum and adds the array elements it is responsible for to this copy. When the parallel region ends, all copies are summed and updated into the original sum variable.
Note that OpenMP support must be enabled at compile time, typically using the -fopenmp flag (for GCC and Clang), for example:
gcc -fopenmp -o sum_reduction sum_reduction.c
Running the above program will give you the total sum of all elements in the array.
Other Constructs
critical Construct
#pragma omp critical
Creates a thread-mutually exclusive code region (must be created inside a parallel region)
The critical directive in OpenMP is used to specify a code region where only one thread can execute at a time. In parallel programming, certain operations (such as updating shared data) may require mutually exclusive access.
Sections Construct
- Divides code blocks within a parallel region into multiple sections for distributed execution
- Can be combined with
parallelto form theparallel sectionsconstruct - Each section is executed by one thread Example code
#pragma omp parallel sections
{
#pragma omp section{Code}
#pragma omp section{Code}
#pragma omp section{Code}
}
barrier Construct single Construct master Construct atomic Construct
Investigation of Private Variables in Different Clauses
Four threads accumulate a number in a loop, recording the final output of each thread (The code is in the shared_variable.cpp file)

- If
privateis not specified, variable initialization can be done within the parallel region; otherwise, thread access to the shared variable is random and results are chaotic. - When using
private, be careful about initialization. Variables need to be re-initialized; if not initialized, the situation shown in the image above will occur. - When using
firstprivate, there is no need to initialize the variable manually. It is automatically initialized based on the main thread's data -- whatever value the main thread's variable has when execution reaches this point, that is the value it is initialized to in the parallel region.
Special Admission Problem Practice
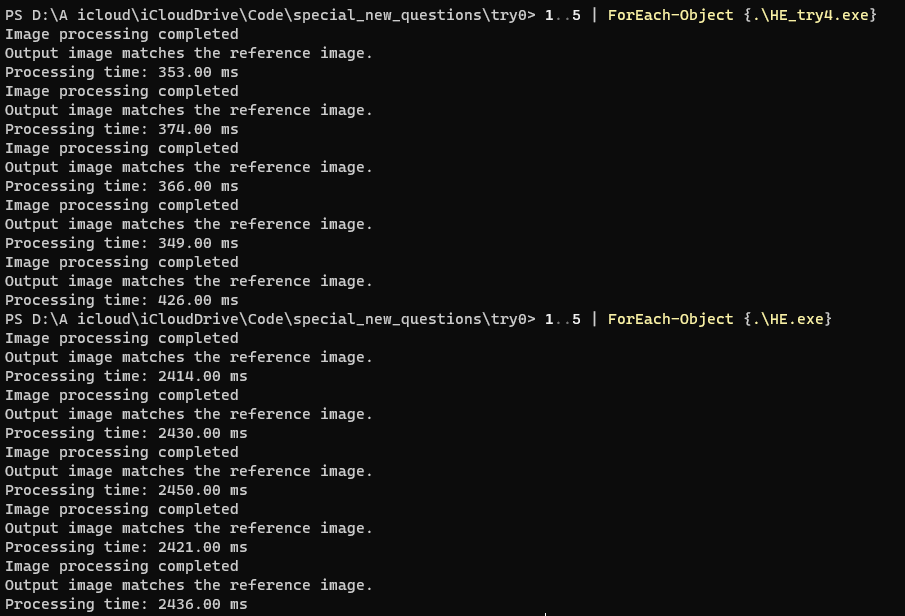
Optimization Results
Original code: 2430ms && try4: 380ms && Speedup: 639.47%
Basic Approach
Use OpenMP to parallelize different parts
Detailed Approach
Part 1: Parallelizing Histogram Computation for Image Reading
// 使用OpenMP并行化直方图计算
#pragma omp parallel
{
int localHistogramRed[256] = {0};
int localHistogramGreen[256] = {0};
int localHistogramBlue[256] = {0};
#pragma omp for nowait
for (int i = 0; i < infoHeader.width * infoHeader.height; i++)
{
localHistogramRed[imageData[i].red]++;
localHistogramGreen[imageData[i].green]++;
localHistogramBlue[imageData[i].blue]++;
}
// 合并局部直方图到全局直方图
#pragma omp critical
{
for (int i = 0; i < 256; i++)
{
histogramRed[i] += localHistogramRed[i];
histogramGreen[i] += localHistogramGreen[i];
histogramBlue[i] += localHistogramBlue[i];
}
}
}
-
Initialize local histogram arrays: In the OpenMP parallel region, each thread creates local histogram arrays for three color channels, used to store the red, green, and blue channel counts for the pixels processed by that thread.
-
Parallel computation of local histograms: Using OpenMP's
#pragma omp for nowaitdirective, each pixel in the image is traversed in parallel. Each thread independently accumulates its assigned portion of pixels across the RGB channels' histograms, thereby decomposing the computation across multiple threads to improve processing speed. -
Merging local histograms into the global histogram: After all threads complete their local histogram computations, they are aggregated into the global histogram arrays. OpenMP's
#pragma omp criticalregion is used to ensure thread-safe synchronization -- only one thread enters the critical section at a time, while others wait, preventing data races from simultaneous modification of the global histogram data. Within the critical section, each thread adds its local histogram to the global histogram.
Part 2: Per-Thread Cumulative Histogram Computation for Three Channels
// 使用OpenMP并行化累积直方图的计算
#pragma omp parallel sections
{
#pragma omp section
{
cumulativeHistogramRed[0] = histogramRed[0];
for (int i = 1; i < 256; i++)
{
cumulativeHistogramRed[i] = cumulativeHistogramRed[i - 1] + histogramRed[i];
}
}
#pragma omp section
{
cumulativeHistogramGreen[0] = histogramGreen[0];
for (int i = 1; i < 256; i++)
{
cumulativeHistogramGreen[i] = cumulativeHistogramGreen[i - 1] + histogramGreen[i];
}
}
#pragma omp section
{
cumulativeHistogramBlue[0] = histogramBlue[0];
for (int i = 1; i < 256; i++)
{
cumulativeHistogramBlue[i] = cumulativeHistogramBlue[i - 1] + histogramBlue[i];
}
}
}
Using the #pragma omp parallel sections directive, three sections divide the red, green, and blue channel histogram computations into independent tasks, each executed by a different thread. This allows simultaneous computation of the cumulative histograms for the red, green, and blue channels.
Part 3: Parallelizing Normalized Histogram and Mapping Computation
// 并行化计算归一化直方图和映射
float totalPixelsInverse = 1.0f / (infoHeader.width * infoHeader.height);
#pragma omp parallel for
for (int i = 0; i < 256; i++)
{
float normRed = cumulativeHistogramRed[i] * totalPixelsInverse;
float normGreen = cumulativeHistogramGreen[i] * totalPixelsInverse;
float normBlue = cumulativeHistogramBlue[i] * totalPixelsInverse;
normalizedHistogramRed[i] = normRed;
normalizedHistogramGreen[i] = normGreen;
normalizedHistogramBlue[i] = normBlue;
mappingRed[i] = (int)(255 * normRed + 0.5f);
mappingGreen[i] = (int)(255 * normGreen + 0.5f);
mappingBlue[i] = (int)(255 * normBlue + 0.5f);
}
Part 4: Parallelizing Pixel Value Updates
// 使用OpenMP并行化像素值更新
#pragma omp parallel for
for (int i = 0; i < infoHeader.width * infoHeader.height; i++)
{
imageData[i].red = mappingRed[imageData[i].red];
imageData[i].green = mappingGreen[imageData[i].green];
imageData[i].blue = mappingBlue[imageData[i].blue];
}
Uses OpenMP's #pragma omp parallel for directive to achieve parallelization.
+++