(2023-11-12) DASP: Specific Dense Matrix Multiply-Accumulate Units Accelerated General Sparse Matrix-Vector Multiplication
| Author: Yuechen Lu; Weifeng Liu; |
|---|
| Journal: , 1-14, 2023. |
| Journal Tags: |
| Local Link: Lu和Liu - 2023 - DASP Specific Dense Matrix Multiply-Accumulate Units Accelerated General Sparse Matrix-Vector Multi.pdf |
| DOI: 10.1145/3581784.3607051 |
| Abstract: Sparse matrix-vector multiplication (SpMV) plays a key role in computational science and engineering, graph processing, and machine learning applications. Much work on SpMV was devoted to resolving problems such as random access to the vector 𝑥 and unbalanced load. However, we have experimentally found that the computation of inner products still occupies much overhead in the SpMV operation, which has been largely ignored in existing work. In this paper, we propose DASP, a new algorithm using specific dense MMA units for accelerating the compute part of general SpMV. We analyze the row-wise distribution of nonzeros and group the rows into three categories containing long, medium, and short rows, respectively. We then organize them into small blocks of proper sizes to meet the requirement of MMA computation. For the three categories, DASP offers different strategies to complete SpMV by efficiently utilizing the MMA units. |
| Tags: |
| Note Date: 2025/7/22 21:45:09 |
📜 Research Core
⚙️ Content
研究背景(ABSTRACT)
稀疏矩阵向量乘法(SpMV)是计算科学与工程、图处理和机器学习应用中的核心运算之一。
现有的SpMV研究主要集中在以下两个方面:
- 解决向量x的随机访问问题
- 通过重构近似均匀大小的基本工作单元来平衡工作负载
即使这些现有工作已经展示了有希望的改进,所达到的性能仍然不令人满意,无法使带宽利用率接近峰值性能,表明SpMV算法仍有优化空间。
关键发现: 作者将标准CSR SpMV的执行时间分解为三个部分进行分析:
- RANDOM ACCESS(随机访问):平均占25.1%
- COMPUTE(计算):平均占21.1%
- MISCELLANEOUS(其他):平均占53.8%
实验发现计算部分仍然占用很大开销,而这部分的开销在已有工作中被严重忽略。
研究方法
核心思想: 提出DASP算法,使用特定密集MMA单元加速通用SpMV的计算部分。核心挑战是如何将稀疏矩阵不规则的数据分布转换为MMA单元所需的规则布局。
分类策略: 根据每行非零元素数量将所有行分为三个类别:
- 长行(Long Rows):非零元素数量 > MAX_LEN (256)
- 中等行(Medium Rows):4 < 非零元素数量 ≤ MAX_LEN
- 短行(Short Rows):非零元素数量 ≤ 4
针对性处理: DASP算法对于三种不同的行类别使用不同的策略:
- 长行:分割成固定大小的组,用零填充以满足MMA计算要求
- 中等行:区分规则和不规则部分,分别使用不同的计算单元
- 短行:采用拼接策略,将短行组合成规则布局以提高MMA单元利用率
研究结果
- FP64双精度:平均比现有算法快1.5-2倍,最高可达90倍以上的加速
- FP16半精度:在A100上平均比cuSPARSE快1.7倍,在H800上快1.75倍
广泛的矩阵适用性: 在SuiteSparse矩阵集合的2893个矩阵上测试,DASP在绝大多数矩阵上都表现出色,证明了算法的通用性和鲁棒性。
💡 Innovations
- 发现计算部分是SpMV算法的性能瓶颈并且�使用MMA加速单元实现更高的性能
- 提出DASP算法让稀疏矩阵不规则的数据分布变得规则以高效利用MMA单元
- 设计了能够充分利用MMA单元计算模式的数据布局
- 证明在Ampere和Hopper架构的GPU上,DASP算法在大部分矩阵上带来比现有的优秀SpMV算法更好的性能
🧩 Shortcomings
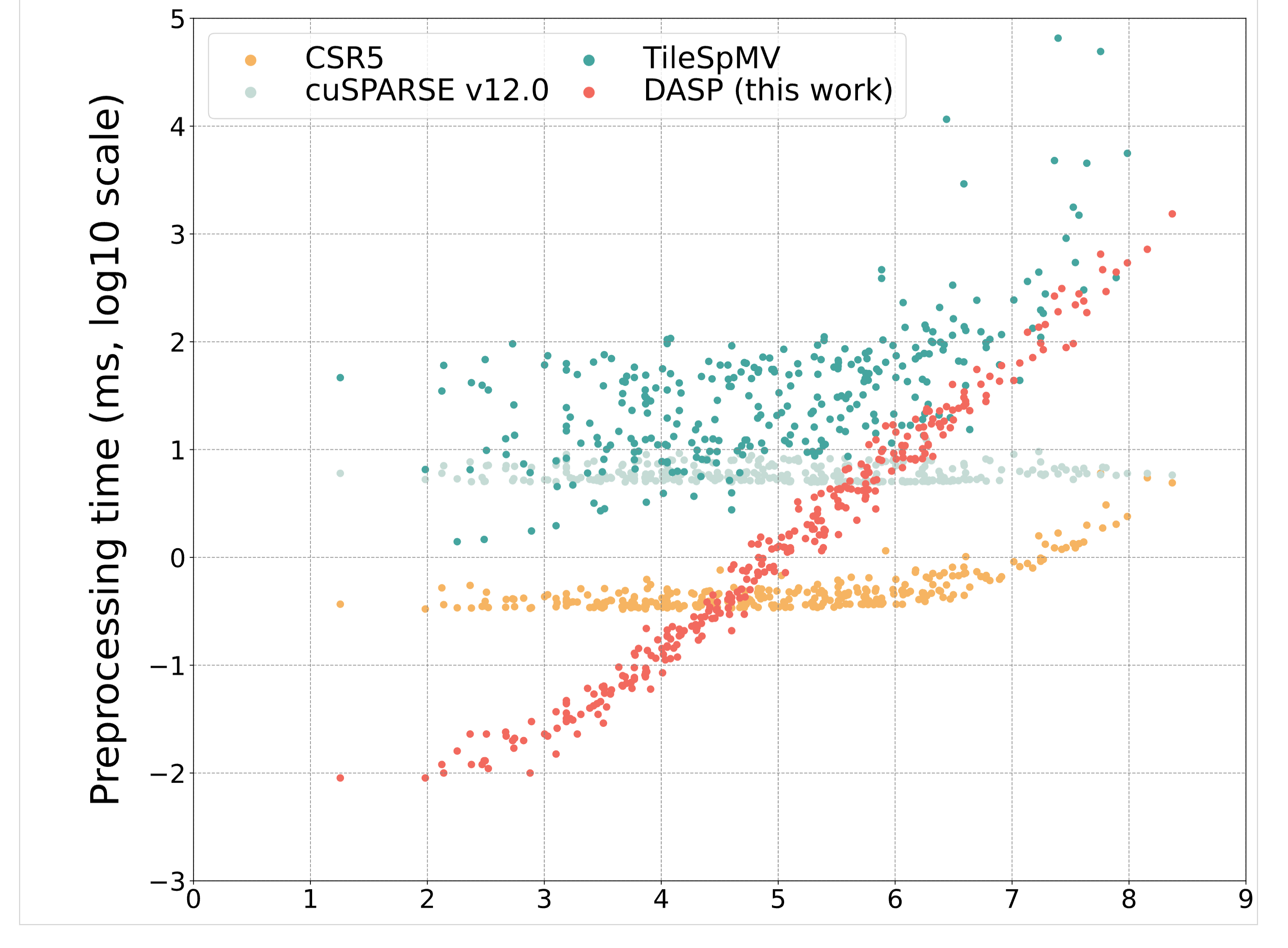
- 预处理开销:数据结构转换需要额外的预处理时间,这部分我测出来的结果是在小于10^6的部分,spmv预处理时间比cuSPARSE短,但是在大于10^6的部分DASP的预处理时间呈现线性增长的趋势,cuSPARSE预处理时间没有明显变化,并且在大于10^6DASP与cuSPARSE的计算速度接近,也就是大于10^6的部分DASP的整体运算时间会比cuDSPARSE多出不少
- 内存消耗增加:新的数据结构可能比原始CSR格式,消耗更多内存空间
- 参数调优复杂性:不同类别的阈值参数(如MAX_LEN、threshold)需要针对不同硬件和矩阵特征进行调优
🔁 Research Content
💧 Data
“using all the 2893 matrices from the SuiteSparse Matrix Collection” (Lu 和 Liu, 2023, p. 2)
测试数据集: "using all the 2893 matrices from the SuiteSparse Matrix Collection" - 使用SuiteSparse矩阵集合中的全部2893个矩阵进行全面评估,这是目前最权威的稀疏矩阵测试集合。
代表性矩阵: 论文还选择了21个在现有SpMV工作中广泛测试的代表性矩阵进行深度分析,涵盖了不同应用领域和矩阵特征。
👩🏻💻 Method
“We first analyze the row-wise distribution of nonzeros and group the rows into three categories to contain long, medium, and short rows, respectively. Then we further divide each long row into chunks of proper sizes to meet the requirement of the MMA computation, and aggregate short rows together to form the regular layout for MMA. For rows of medium sizes, we further distinguish them into regular and irregular parts and use different computational units accordingly. On top of the MMA-friendly data structure, different CUDA kernels utilizing the MMA units are developed for the three groups of rows.” (Lu 和 Liu, 2023, p. 2)
“It consists of two main components: a new data structure that can be efficiently used for the compute pattern of the MMA units, and the corresponding SpMV algorithms.” (Lu 和 Liu, 2023, p. 4)
第三部分DASP首先介绍了DASP算法的组成:能够高效利用MMA单元的数据结构和相应的SpMV算法
“group all rows into three categories according to the number of nonzeros in each row” (Lu 和 Liu, 2023, p. 4)
数据结构部分将所有的行根据非零元素的数量分成了三个部分
🔬 Experiment
-
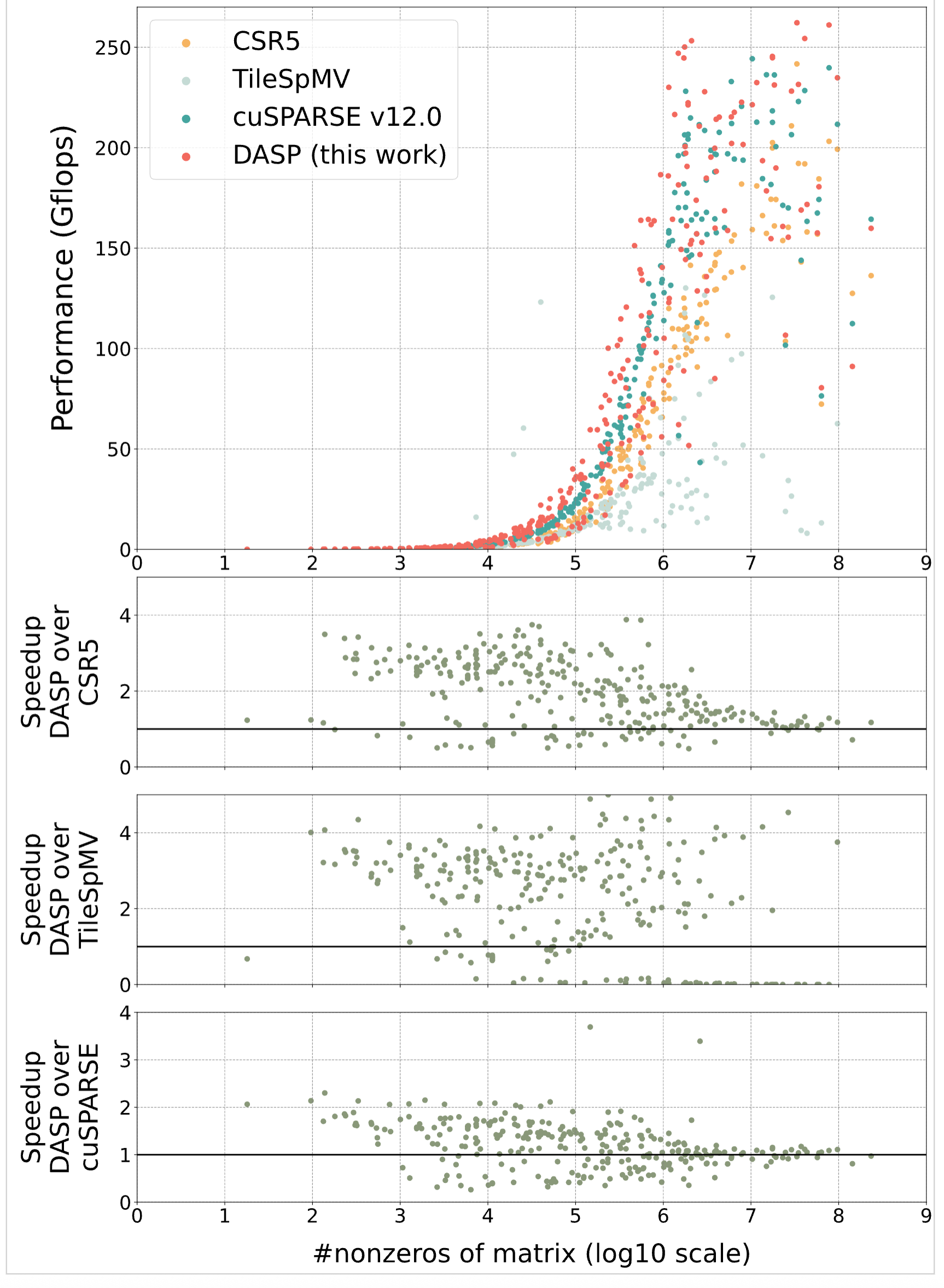
将SpMV操作分为三个部分,测试三个部分的开销,分析出计算占据不小的开销(figure2)
-
测试已有的方法和提出的DASP的带宽吞吐量上的差异(figure1)
📜 Conclusion
DASP算法通过识别并解决SpMV中被忽视的计算瓶颈,创新性地利用MMA单元实现了显著的性能提升。
🤔 Personal Summary
复现结果
复现设备:
CPU: Intel Xeon Gold 6348 Processor 2.6GHz 28 cores * 2
Memory: 64G * 16,DDR4,3200Mhz
NVIDIA A100 NVLink 600 GB/s Gen4 64 GB/s MEMORY:80GB HBM2 BANDWIDTH:1,555 GB/s
a100_f16_bar:

a100_f16_scatter:
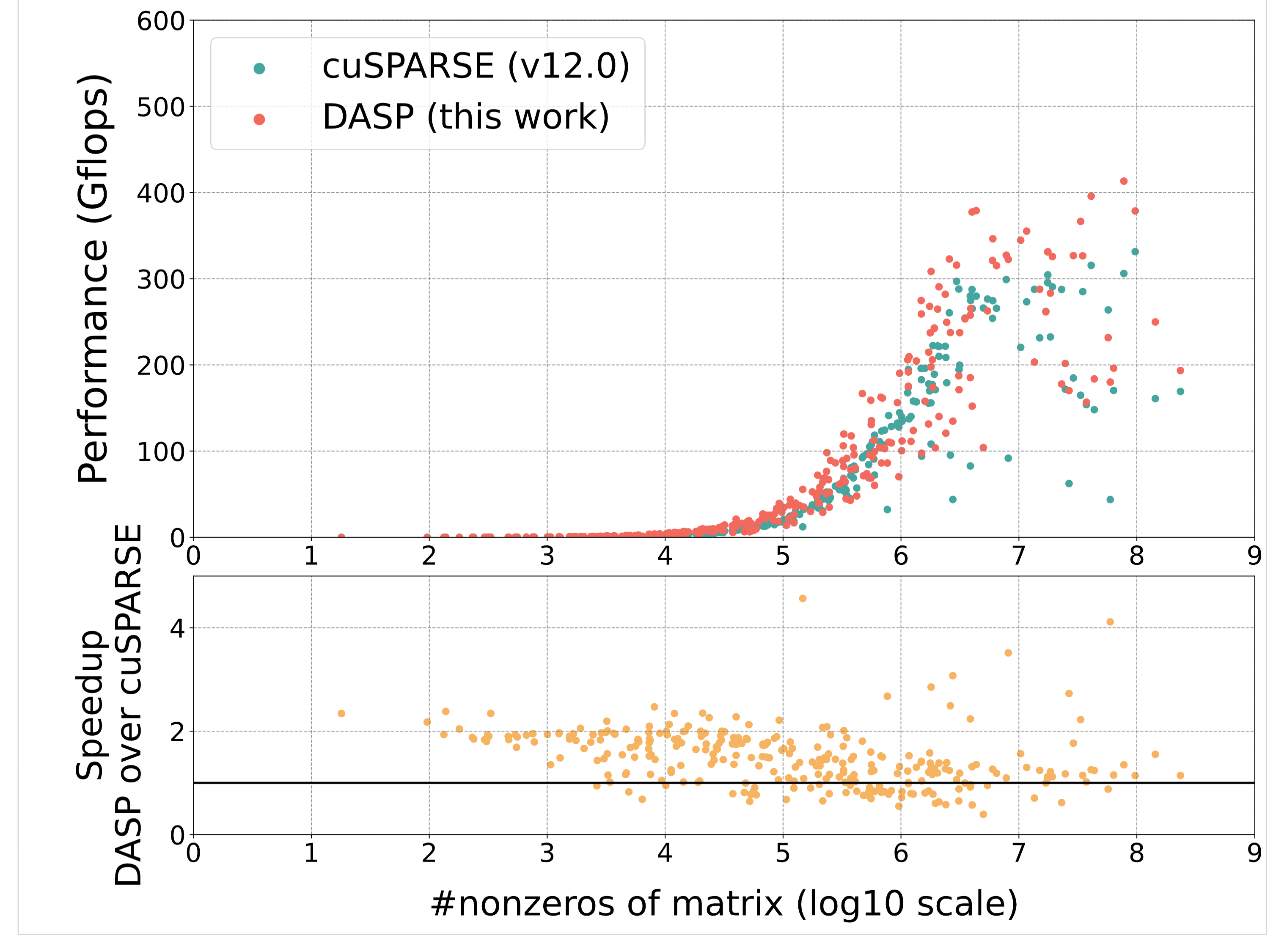
a100_f64_bar:

a100_f64_scatter:
preprocessing_time:
📌 To be resolved
- 预处理时间是否与CPU核心数量相关,以及在相同CPU配置下与其他方法的预处理性能对比
- 不同GPU架构上的参数调优策略和自适应方法
- 算法在更多样化的稀疏矩阵模式上的表现和改进空间
- 内存消耗与性能提升之间的权衡分析
💭 Thought Inspiration
算法设计启发:
- 算法设计配合硬件:充分利用现代处理器的专用计算单元是提升性能的重要途径
- 数据结构与算法协同优化:针对硬件特征重新设计数据结构往往能带来意想不到的性能提升
- 分类处理策略:对不同特征的数据采用不同的处理策略可以兼顾通用性和高效性
研究方法启发:
- 性能瓶颈的重新审视:有时候被认为已经充分优化的领域仍存在被忽视的瓶颈
- 全面的实验验证:大规模的测试数据集对证明算法的通用性至关重要
未来发展方向:
-
在其他架构(AMD、Intel等)上的扩展和优化
-
与深度学习框架的集成和应用
-
多精度计算的进一步优化
📖English Learning
“overhead” (Lu 和 Liu, 2023, p. 1) 开销
“Sparse” (Lu 和 Liu, 2023, p. 1) 疏 英[spɑːs]
“dense” (Lu 和 Liu, 2023, p. 1) 稠密 英[dens]
“propose” (Lu 和 Liu, 2023, p. 1) 提出
“categories” (Lu 和 Liu, 2023, p. 1) 类别
“outperforms” (Lu 和 Liu, 2023, p. 1) 胜过
Accumulate 累积
“granted” 准许、同意
“cornerstones” (Lu 和 Liu, 2023, p. 1) na. 基础;隅石;(奠基礼的)基石; 网络释义: 基础投资者
“locality” (Lu 和 Liu, 2023, p. 1) n. 地点;(围绕所处或提及的)地区; 网络释义: 位置;局部性;所在地
“dash” (Lu 和 Liu, 2023, p. 1) n. 短跑;破折号;匆忙;少量; v. 猛冲;急奔;急驰;猛掷; abbr. (=drone antisubmarine helicopter)无线电遥控反潜艇攻击机; 网络释义: 冲刺;冲撞;突进
“demonstrated” (Lu 和 Liu, 2023, p. 1) v. 示范;证明;表明;【军】示威; 网络释义: 展示;表示;说明
“promising” (Lu 和 Liu, 2023, p. 1) adj. 有希望的;有前途的;有出息的; v. “promise”的现在分词; 网络释义: 有为;有前景的;大有希望的
“indicates” (Lu 和 Liu, 2023, p. 2) v. 指示;指出;【医】表明(症状、原因) 需要(治疗方法等);象征 暗示 预示;简单陈述; 网络释义: 显示;表示
“breakdown” (Lu 和 Liu, 2023, p. 2) n. 分解;损坏;分类;(�关系)破裂; adj. 专门修理故障的; 网络释义: 崩溃;击穿;失败
“representatives” (Lu 和 Liu, 2023, p. 2) n. 代表;〈美〉众议员;典型;继任者; adj. 表示的;表现的;象征的;代理的; 网络释义: 典型的;代表或业务员;代表人
“trivial” (Lu 和 Liu, 2023, p. 2) adj. 不重要的;琐碎的;微不足道的; 网络释义: 琐细的;平常的;平凡的
“exploiting” (Lu 和 Liu, 2023, p. 2) v. 开发;利用;剥削;利用…谋私利; n. 功绩; 网络释义: 开拓;有效利用资源;开发利用
“aggregate” (Lu 和 Liu, 2023, p. 2) n. 骨料;合计;总数; v. 合计;总计; adj. 总数的;总计的; 网络释义: 集合;聚集;聚合
“distinguish” (Lu 和 Liu, 2023, p. 2) v. 区分;辨别;分清;认出; 网络释义: 区别;识别;分辨
utilize v.利用
"State-of-the-art" 是一个英语术语,通常用来形容使用最先进技术或方法的事物,表示某领域中的最高技术水平或者是最新的发展。
“coordinate” (Lu 和 Liu, 2023, p. 3) n. 坐标;(颜色协调的)配套服装; v. 协调;使协调;使相配合;使(身体各部位)动作协调; adj. 同等的;配合的;【语】对等的;【数】坐标的; 网络释义: 座标;调整;并列的
“corresponding” (Lu 和 Liu, 2023, p. 3) adj. 符合的;相应的;相关的; v. “correspond”的现在分词; 网络释义: 相当的;对应的;一致的
“accumulator” (Lu 和 Liu, 2023, p. 3) n. 蓄电池;累加器;累计下注(每赢一次即押于下一轮赌博); 网络释义: 累计期权;蓄能器;蓄压器
the product of:... 的乘积,即两个数相乘的结果。
“proportion” (Lu 和 Liu, 2023, p. 3) n. 比例;部分;份额;均衡; v. 摊派;使相称; 网络释义: 比�率;比重;面积
“portion” (Lu 和 Liu, 2023, p. 3) n. 部分;(食物的)一份;分享的部分;分担的责任; v. 把…分成若干份(或部分); 网络释义: 一部分;分配;客
“arithmetic” (Lu 和 Liu, 2023, p. 3) n. 算术;算术运算;四则运算; 网络释义: 算法;计算;算数
fragments 片段
“components” (Lu 和 Liu, 2023, p. 4) n. 成分;【自】元件;【物】分力; adj. 构成的; 网络释义: 组件;部件;构件
“classify” (Lu 和 Liu, 2023, p. 4) v. 分类;归类;划分;界定; 网络释义: 把…分类;分等;分等级
“extract” (Lu 和 Liu, 2023, p. 4) n. 提取物;摘录;精;节录; v. 提取;摘录;提炼;获得; 网络释义: 抽出;抽取;拔出
“parameter” (Lu 和 Liu, 2023, p. 4) n. 范围;决定因素;规范; 网络释义: 参数;参量;指标参数
“evenly” (Lu 和 Liu, 2023, p. 4) adv. 均匀地;平均地;公平地;不偏不倚地; 网络释义: 平坦地;均匀的;平静地
“remaining” (Lu 和 Liu, 2023, p. 5) adj. 仍需做的;还需处理的; v. “remain”的现在分词; 网络释义: 剩余的;剩下的;遗留的
原句:
As for SpMV in FP16 precision, our DASP outperforms cuSPARSE by a factor of on average 1.70x and 1.75x (up to 26.47x and 65.94x) on A100 and H800, respectively.
As for:这是一个介词短语,意思是“至于”、“关于”,用于引入话题
outperforms:谓语动词,意为“优于”、“胜过”,常用于性能比较。
by a factor of:固定搭配,意思是“以……的倍数”,用于表示数量级或比例。
- 例如:increase by a factor of 3 = 增加到原来的3倍。
respectively:副词,“分别地”,��用于对应前面成对出现的数值。
- 当列举多个项目,并说明它们与前面提到的项目按顺序一一对应时使用。
- 例句:
- Alice and Bob are 25 and 30 years old, respectively. (爱丽丝和鲍勃的年龄分别是25岁和30岁。) → 爱丽丝25岁,鲍勃30岁。
- The first and second prizes went to John and Mary, respectively. (一等奖和二等奖分别由约翰和玛丽获得。) → 约翰得一等奖,玛丽得二等奖。