(2023-11-12) DASP: Specific Dense Matrix Multiply-Accumulate Units Accelerated General Sparse Matrix-Vector Multiplication
| Author: Yuechen Lu; Weifeng Liu; |
|---|
| Journal: , 1-14, 2023. |
| Journal Tags: |
| Local Link: Lu and Liu - 2023 - DASP Specific Dense Matrix Multiply-Accumulate Units Accelerated General Sparse Matrix-Vector Multi.pdf |
| DOI: 10.1145/3581784.3607051 |
| Abstract: Sparse matrix-vector multiplication (SpMV) plays a key role in computational science and engineering, graph processing, and machine learning applications. Much work on SpMV was devoted to resolving problems such as random access to the vector x and unbalanced load. However, we have experimentally found that the computation of inner products still occupies much overhead in the SpMV operation, which has been largely ignored in existing work. In this paper, we propose DASP, a new algorithm using specific dense MMA units for accelerating the compute part of general SpMV. We analyze the row-wise distribution of nonzeros and group the rows into three categories containing long, medium, and short rows, respectively. We then organize them into small blocks of proper sizes to meet the requirement of MMA computation. For the three categories, DASP offers different strategies to complete SpMV by efficiently utilizing the MMA units. |
| Tags: |
| Note Date: 2025/7/22 21:45:09 |
Research Core
Content
Research Background (ABSTRACT)
Sparse matrix-vector multiplication (SpMV) is one of the core operations in computational science and engineering, graph processing, and machine learning applications.
Existing SpMV research mainly focuses on the following two aspects:
- Solving the random access problem of vector x
- Balancing workload by restructuring approximately uniform-sized basic work units
Even though these existing works have shown promising improvements, the achieved performance is still unsatisfactory, unable to bring bandwidth utilization close to peak performance, indicating that there is still room for SpMV algorithm optimization.
Key Finding: The authors decomposed the execution time of standard CSR SpMV into three parts for analysis:
- RANDOM ACCESS: averages 25.1%
- COMPUTE: averages 21.1%
- MISCELLANEOUS: averages 53.8%
Experiments found that the computation part still occupies significant overhead, and this overhead has been largely ignored in existing work.
Research Method
Core Idea: Propose the DASP algorithm, using specific dense MMA units to accelerate the computation part of general SpMV. The core challenge is how to convert the irregular data distribution of sparse matrices into the regular layout required by MMA units.
Classification Strategy: All rows are divided into three categories based on the number of non-zero elements per row:
- Long Rows: Number of non-zero elements > MAX_LEN (256)
- Medium Rows: 4 < Number of non-zero elements ≤ MAX_LEN
- Short Rows: Number of non-zero elements ≤ 4
Targeted Processing: The DASP algorithm uses different strategies for three different row categories:
- Long rows: Split into fixed-size groups, padded with zeros to meet MMA computation requirements
- Medium rows: Distinguish between regular and irregular parts, using different computational units for each
- Short rows: Adopt a concatenation strategy, combining short rows into regular layouts to improve MMA unit utilization
Research Results
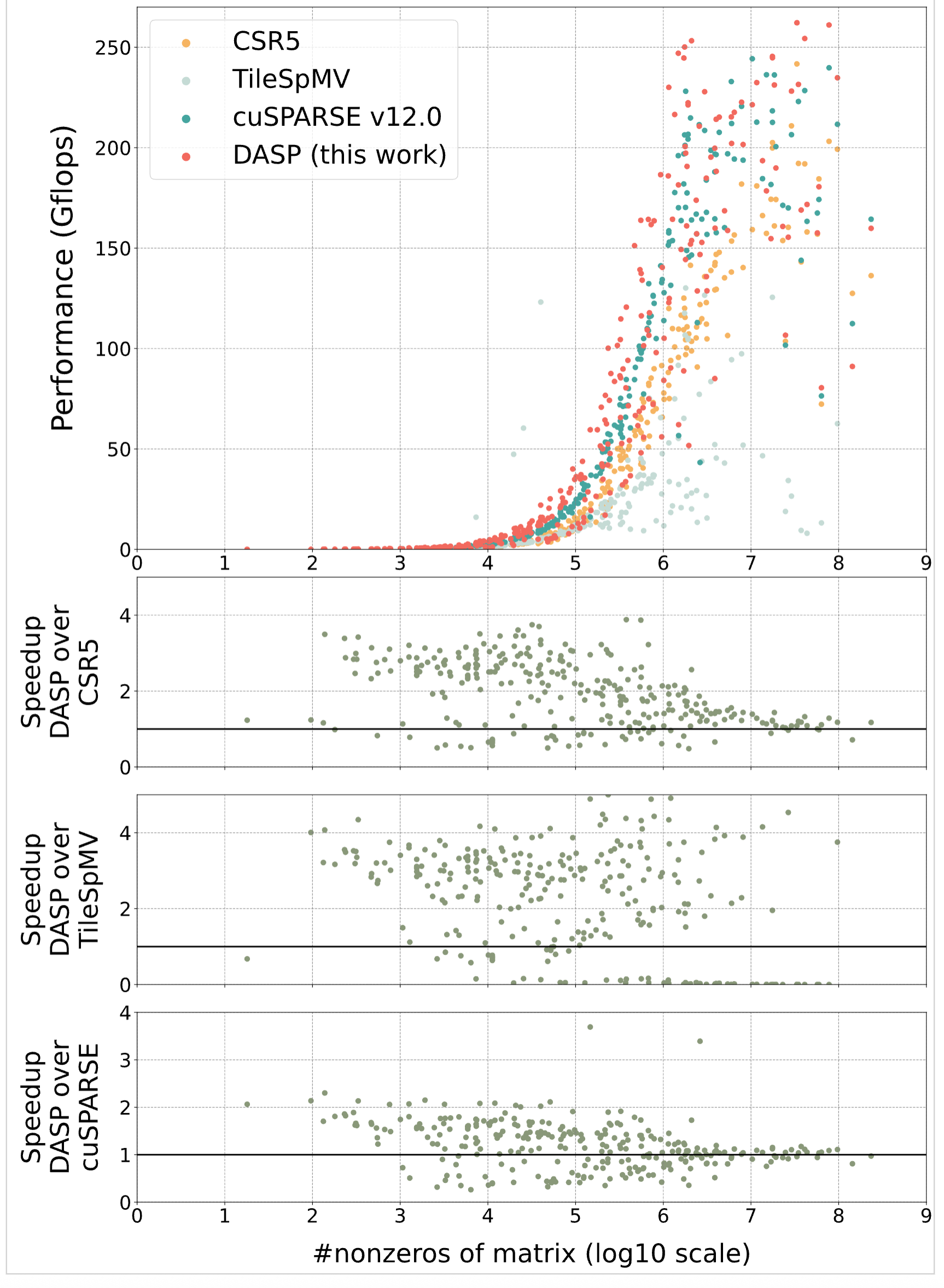
- FP64 Double Precision: On average 1.5-2x faster than existing algorithms, with up to 90x+ speedup
- FP16 Half Precision: On average 1.7x faster than cuSPARSE on A100, and 1.75x faster on H800
Broad Matrix Applicability: Tested on 2893 matrices from the SuiteSparse matrix collection, DASP performed well on the vast majority of matrices, proving the algorithm's generality and robustness.
Innovations
- Discovered that the computation part is the performance bottleneck of SpMV algorithms and used MMA acceleration units to achieve higher performance
- Proposed the DASP algorithm to make the irregular data distribution of sparse matrices regular for efficient utilization of MMA units
- Designed data layouts that can fully utilize the computational patterns of MMA units
- Proved that on Ampere and Hopper architecture GPUs, the DASP algorithm brings better performance than existing excellent SpMV algorithms on most matrices
Shortcomings
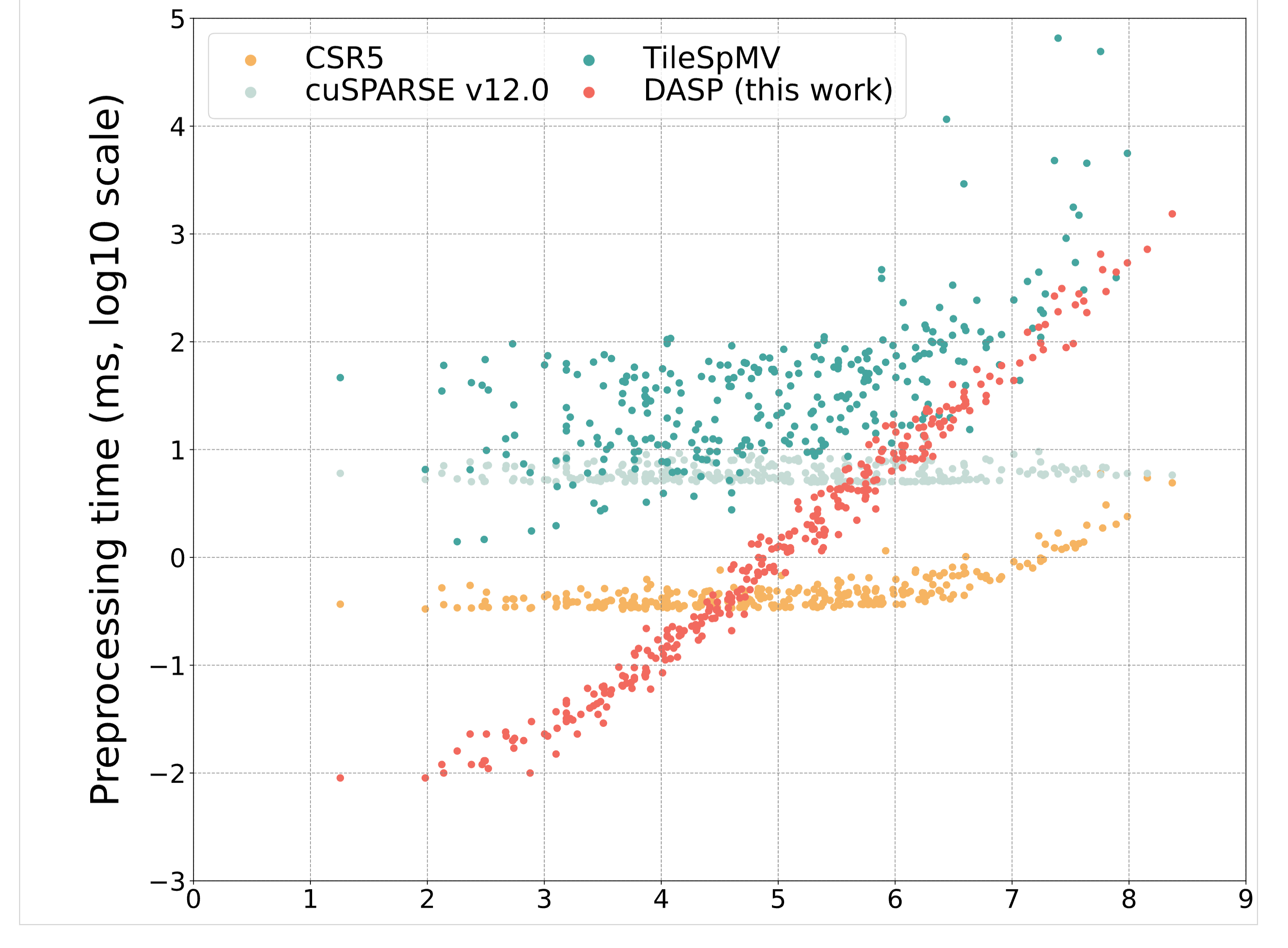
- Preprocessing Overhead: Data structure conversion requires additional preprocessing time. My test results show that for sizes less than 10^6, the SpMV preprocessing time is shorter than cuSPARSE, but for sizes greater than 10^6, DASP's preprocessing time shows a linear growth trend, while cuSPARSE preprocessing time doesn't change significantly. Moreover, for sizes greater than 10^6, DASP and cuSPARSE computation speeds are close, meaning that for sizes greater than 10^6, DASP's overall computation time will be significantly more than cuSPARSE.
- Increased Memory Consumption: The new data structure may consume more memory space than the original CSR format.
- Parameter Tuning Complexity: Threshold parameters for different categories (such as MAX_LEN, threshold) need to be tuned for different hardware and matrix characteristics.
Research Content
Data
"using all the 2893 matrices from the SuiteSparse Matrix Collection" (Lu and Liu, 2023, p. 2)
Test Dataset: "using all the 2893 matrices from the SuiteSparse Matrix Collection" - Using all 2893 matrices from the SuiteSparse Matrix Collection for comprehensive evaluation, which is currently the most authoritative sparse matrix test collection.
Representative Matrices: The paper also selected 21 representative matrices widely tested in existing SpMV work for in-depth analysis, covering different application domains and matrix characteristics.
Method
"We first analyze the row-wise distribution of nonzeros and group the rows into three categories to contain long, medium, and short rows, respectively. Then we further divide each long row into chunks of proper sizes to meet the requirement of the MMA computation, and aggregate short rows together to form the regular layout for MMA. For rows of medium sizes, we further distinguish them into regular and irregular parts and use different computational units accordingly. On top of the MMA-friendly data structure, different CUDA kernels utilizing the MMA units are developed for the three groups of rows." (Lu and Liu, 2023, p. 2)
"It consists of two main components: a new data structure that can be efficiently used for the compute pattern of the MMA units, and the corresponding SpMV algorithms." (Lu and Liu, 2023, p. 4)
The third section of DASP first introduces the composition of the DASP algorithm: a data structure that can efficiently utilize MMA units and the corresponding SpMV algorithm.
"group all rows into three categories according to the number of nonzeros in each row" (Lu and Liu, 2023, p. 4)
The data structure part divides all rows into three parts based on the number of non-zero elements.
Experiment
-
Divided the SpMV operation into three parts, tested the overhead of the three parts, and analyzed that computation occupies significant overhead (figure2)
-
Tested the differences in bandwidth throughput between existing methods and the proposed DASP (figure1)
Conclusion
The DASP algorithm achieves significant performance improvements by identifying and solving the overlooked computation bottleneck in SpMV, innovatively utilizing MMA units.
Personal Summary
Reproduction Results
Reproduction Equipment:
CPU: Intel Xeon Gold 6348 Processor 2.6GHz 28 cores * 2
Memory: 64G * 16,DDR4,3200Mhz
NVIDIA A100 NVLink 600 GB/s Gen4 64 GB/s MEMORY:80GB HBM2 BANDWIDTH:1,555 GB/s
a100_f16_bar:

a100_f16_scatter:
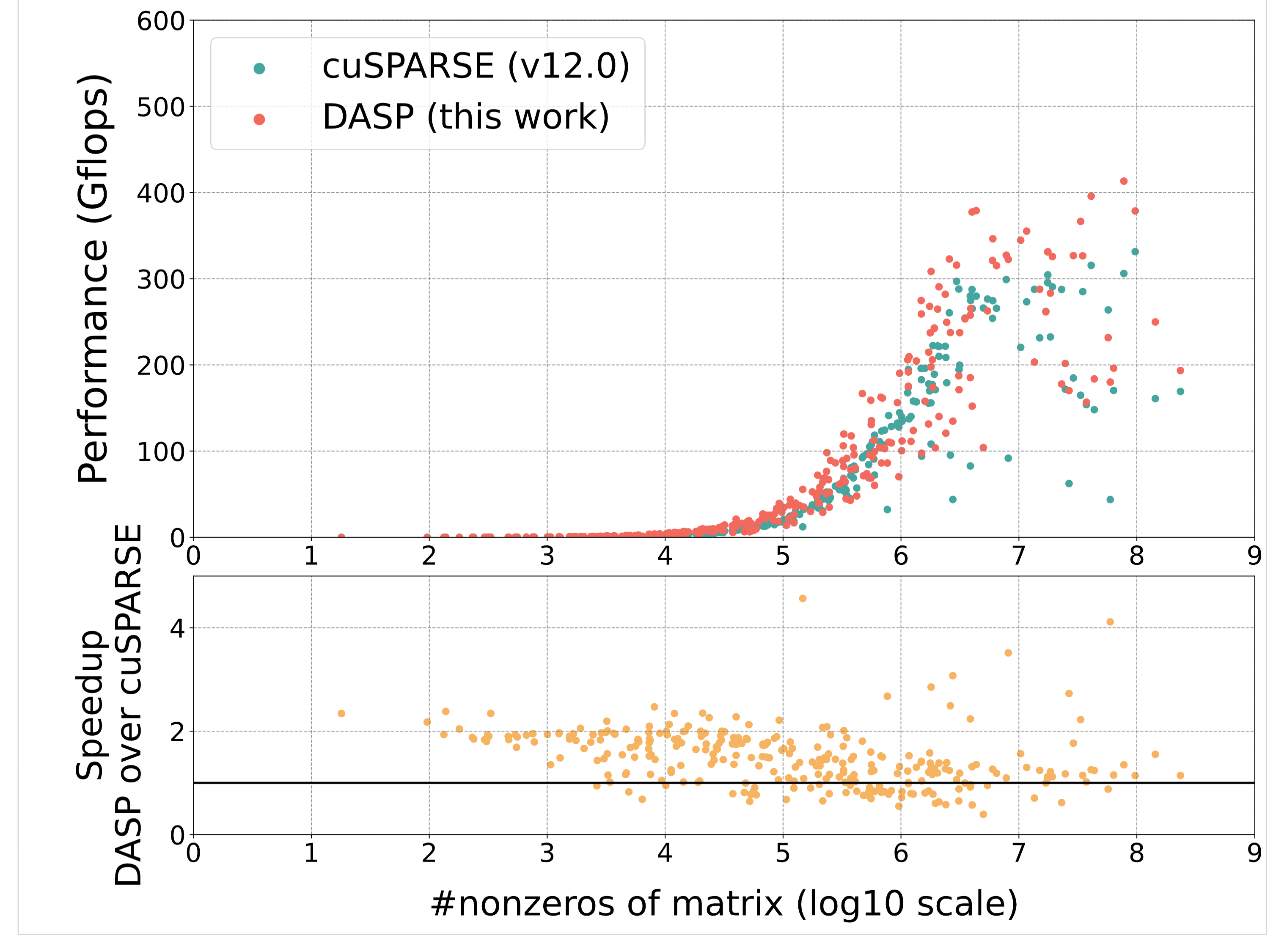
a100_f64_bar:

a100_f64_scatter:
preprocessing_time:
To be resolved
- Whether preprocessing time is related to CPU core count, and preprocessing performance comparison with other methods under the same CPU configuration
- Parameter tuning strategies and adaptive methods on different GPU architectures
- Algorithm performance and improvement space on more diverse sparse matrix patterns
- Trade-off analysis between memory consumption and performance improvement
Thought Inspiration
Algorithm Design Inspiration:
- Algorithm design aligned with hardware: Fully utilizing the specialized computational units of modern processors is an important way to improve performance
- Data structure and algorithm co-optimization: Redesigning data structures for hardware characteristics often brings unexpected performance improvements
- Classification processing strategy: Using different processing strategies for data with different characteristics can balance generality and efficiency
Research Method Inspiration:
- Re-examination of performance bottlenecks: Sometimes domains that are thought to be fully optimized still contain overlooked bottlenecks
- Comprehensive experimental validation: Large-scale test datasets are crucial for proving algorithm generality
Future Development Directions:
-
Extension and optimization on other architectures (AMD, Intel, etc.)
-
Integration and application with deep learning frameworks
-
Further optimization of multi-precision computing
English Learning
"overhead" (Lu and Liu, 2023, p. 1)
"Sparse" (Lu and Liu, 2023, p. 1) sparse
"dense" (Lu and Liu, 2023, p. 1) dense
"propose" (Lu and Liu, 2023, p. 1) propose
"categories" (Lu and Liu, 2023, p. 1) categories
"outperforms" (Lu and Liu, 2023, p. 1) outperforms
Accumulate
"granted" granted
"cornerstones" (Lu and Liu, 2023, p. 1) na. foundation; cornerstone
"locality" (Lu and Liu, 2023, p. 1) n. locality; locality
"dash" (Lu and Liu, 2023, p. 1) n. dash; dash
"demonstrated" (Lu and Liu, 2023, p. 1) v. demonstrate; demonstrate
"promising" (Lu and Liu, 2023, p. 1) adj. promising; promising
"indicates" (Lu and Liu, 2023, p. 2) v. indicate; indicate
"breakdown" (Lu and Liu, 2023, p. 2) n. breakdown; breakdown
"representatives" (Lu and Liu, 2023, p. 2) n. representatives; representatives
"trivial" (Lu and Liu, 2023, p. 2) adj. trivial; trivial
"exploiting" (Lu and Liu, 2023, p. 2) v. exploit; exploit
"aggregate" (Lu and Liu, 2023, p. 2) n. aggregate; aggregate
"distinguish" (Lu and Liu, 2023, p. 2) v. distinguish; distinguish
utilize v. utilize
"State-of-the-art" is an English term, usually used to describe things that use the most advanced technology or methods, indicating the highest technical level or the latest development in a field.
"coordinate" (Lu and Liu, 2023, p. 3) n. coordinate; coordinate
"corresponding" (Lu and Liu, 2023, p. 3) adj. corresponding; corresponding
"accumulator" (Lu and Liu, 2023, p. 3) n. accumulator; accumulator
the product of: the product of two numbers, i.e., the result of multiplying two numbers.
"proportion" (Lu and Liu, 2023, p. 3) n. proportion; proportion
"portion" (Lu and Liu, 2023, p. 3) n. portion; portion
"arithmetic" (Lu and Liu, 2023, p. 3) n. arithmetic; arithmetic
fragments fragments
"components" (Lu and Liu, 2023, p. 4) n. components; components
"classify" (Lu and Liu, 2023, p. 4) v. classify; classify
"extract" (Lu and Liu, 2023, p. 4) n. extract; extract
"parameter" (Lu and Liu, 2023, p. 4) n. parameter; parameter
"evenly" (Lu and Liu, 2023, p. 4) adv. evenly; evenly
"remaining" (Lu and Liu, 2023, p. 5) adj. remaining; remaining
Original sentence:
As for SpMV in FP16 precision, our DASP outperforms cuSPARSE by a factor of on average 1.70x and 1.75x (up to 26.47x and 65.94x) on A100 and H800, respectively.
As for: This is a prepositional phrase meaning "as for" or "regarding," used to introduce a topic.
outperforms: Predicate verb, meaning "outperforms" or "surpasses," commonly used in performance comparisons.
by a factor of: Fixed collocation, meaning "by a factor of," used to express magnitude or proportion.
- For example: increase by a factor of 3 = increased to 3 times the original.
respectively: Adverb, "respectively," used to correspond to pairs of values mentioned earlier.
- Used when listing multiple items and indicating they correspond one-to-one with previously mentioned items in order.
- Example sentences:
- Alice and Bob are 25 and 30 years old, respectively. -> Alice is 25, Bob is 30.
- The first and second prizes went to John and Mary, respectively. -> John got the first prize, Mary got the second prize.