丁致宇第一周学习报告
目录
[TOC]
OpenMP
常用的库函数
// 设置并行区运行的线程数
void omp set num threads(int)
// �获得并行区运行的线程数i
nt omp_get num threads(void)
// 得线程编号
int omp_get_thread num(void)
// 获得openmp walL cLock时间(单位秒)
double omp_get_wtime(void)
// ��获得omp_get_wtime时间精度
double omp_get_wtick(void)
parallel构造、for构造
常用指令
#pragma omp parallel: 会启动一个新的并行区域,创建个包含多个线程的团队。#pragma omp for: 指示一个可以被并行执行的循环(例如CC++中的for循环),它会将循环体分解为多个任务,在多个线程上分别执行这些任务,这个指令需要写在已经创建好的并行区内。#pragma omp parallel for:这个指令结合了“paralle"和“for"两个部分的功能。首先,#pragma omp parallel 会启动一个新的并行区域,创建个包含多个线程的团队。然后,for 部分会在新创建的线程团队上并行化指定的循环。所以, #pragma ompparallel for 不仅会并行执行循环,而且还会确保有一个合适的并行环境来执行循环
parallel for支持的从句
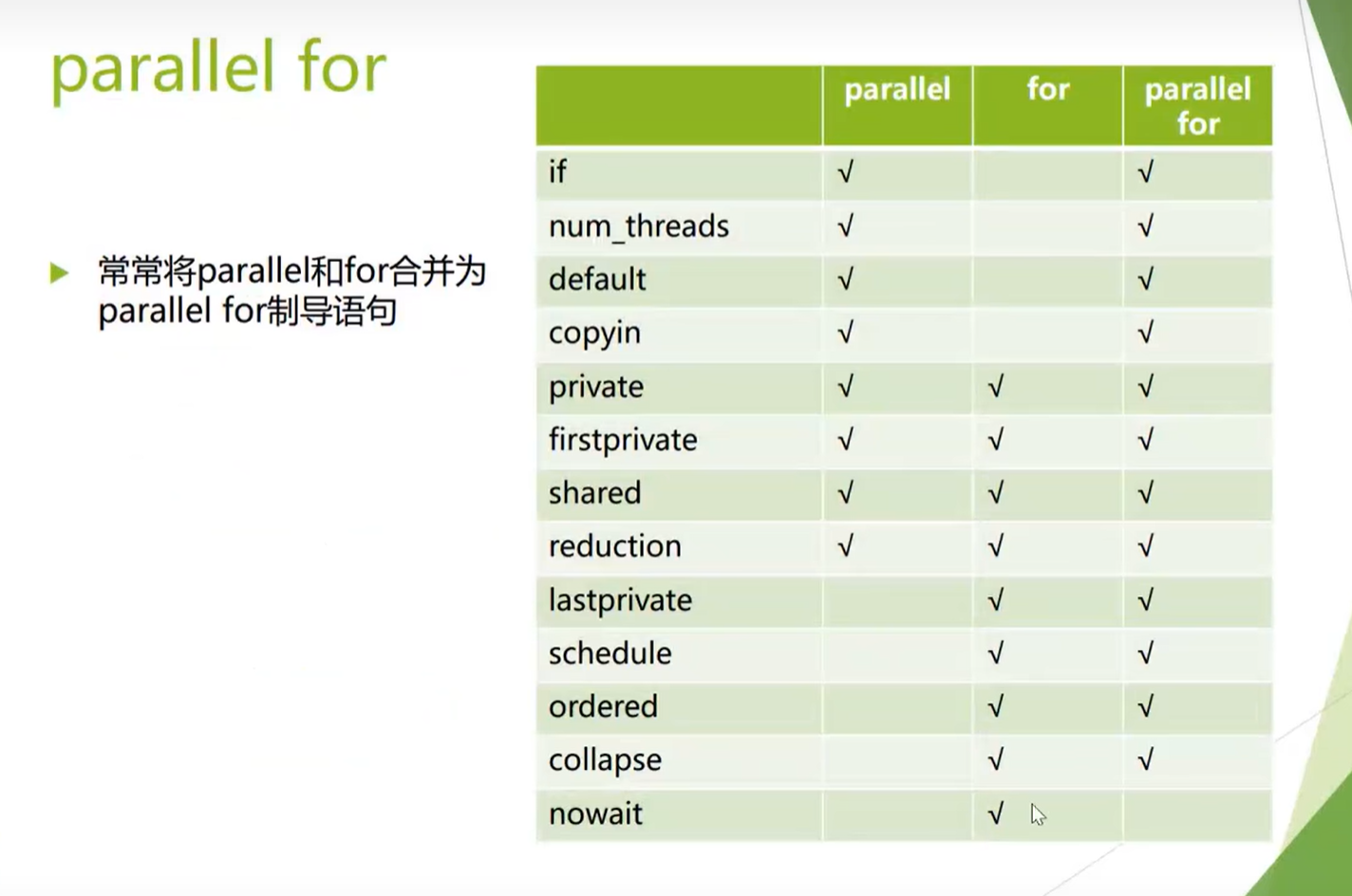
#pragma omp parallel (+从句)
if(scalar expression): 决定是否以并行的方式执行并行区
- 表达式为真(非零):按照并行方式执行并行区
- 否则: 主线程串行执行并行区
num threads(integer expression): 指定并行区的线程数
private(list): 指定私有变量列表
- 每个线程生成一份与该私有变量同类型的数据对象
- 变量需要重新初始化
firstprivate(list):
- 同private
- 对变量根据主线程中的数据进行初始化
#pragma omp for (+从句)
- nowait语句取消隐式同步
- collapse(n)从句处理嵌套循环
- order语句在并行区内的循环中强制执行某种顺序
- reduction语句简化对共享变量操作
schedule()语句定义循环分配给线程的方式
在OpenMP中,schedule子句用于指定并行循环的迭代如何在多个线程之间分配。这对于负载平衡非常重要,尤其是当循环迭代的工作量不均匀时。schedule子句可以应用于#pragma omp for或#pragma omp parallel for指令。下面是几种不同类型的schedule子句:
- Static schedule
这种类型的调度会将迭代分为大小为
#pragma omp for schedule(static[, chunk])chunk的块,并静态分配给线程。如果没有指定chunk大小,默认将循环迭代数除以线程数,每个线程尽量分配到等量的迭代。如果指定了chunk大小,每个线程将以chunk为单位分配迭代。 - Dynamic schedule
#pragma omp for schedule(dynamic[, chunk])dynamic调度允许线程在完成分配的迭代后从迭代池中动态领取新的工作块。chunk大小是可选的,如果未指定,每次默认以1为单位领取新的迭代块。 - Guided schedule
在
#pragma omp for schedule(guided[, chunk])guided调度中,初始的chunk大小较大,但它将随着算法的进行而减小。简而言之,最初,当存在大量的可用工作时,线程会领取较大块的迭代,但当工作接近结束时,领取的块大小逐渐减小以避免最后一些线程工作过多而其他线程空闲。chunk大小设置了下限,防止块变得过小。 - Auto schedule
#pragma omp for schedule(auto)auto调度把决策权交给编译器和运行时系统,它们会根据代码和系统的状况来选择最佳的调度方式。 这里是一个schedule用法的简单示例:
#pragma omp parallel for schedule(dynamic, 10)
for(int i = 0; i < N; i++) {
// 处理迭代中的代码
}
在这个例子中,循环迭代被动态地分配给线程,每个块的chunk大小为10。这意味着线程将执行10个迭代的任务,然后返回到循环的迭代池中获取下一个10迭代的块,直到完成所有迭代。
schedule子句的使用取决于算法特性和工作负载情况,合理地使用schedule可以显著提升并行程序的性能和效率。
Reduction
OpenMP是一种支持多平台共享内存并行编程的API,它可以用于C、C++和Fortran语言。在OpenMP中,reduction是一个指令,它用于在并行区域中对变量进行累积操作,例如求和、求积、找最大值或最小值等。
当你在并行区域中使用reduction指令时,每个线程会得到它自己的私有拷贝副本。这些线程对它们的私有拷贝进行操作,然后在并行区域结束时,所有的私有拷贝会被组合起来("reduce"),并更新到原始变量中。
OpenMP的reduction指令的语法如下:
#pragma omp parallel for reduction(操作:变量)
其中,操作可以是以下之一:
+:求和*:求积-:求差(注意:并行区域内的减法操作通常不是关联的,因此结果可能依赖于线程的执行顺序)&:按位与|:按位或^:按位异或&&:逻辑与||:逻辑或max:最大值min:最小值
下面是一个使用OpenMP reduction指令的例子,该例子计算一个数组所有元素的和:
#include <stdio.h>
#include <omp.h>
int main() {
int arr[] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
int sum = 0;
int i;
#pragma omp parallel for reduction(+:sum)
for (i = 0; i < 10; i++) {
sum += arr[i];
}
printf("Sum = %d\n", sum);
return 0;
}
在这个例子中,sum变量是被归约的变量,+操作表示我们要对数组中的元素求和。#pragma omp parallel for reduction(+:sum)指令告诉OpenMP创建一个并行区域,其中的循环迭代会被分配到不同的线程上执行。每个线程都有自己的sum副本,它们将自己负责的数组元素加到这个副本上。当并行区域结束时,所有副本的值会相加,更新到原始的sum变量中。
需要注意的是,编译时需要开启OpenMP支持,通常使用-fopenmp标志(对于GCC和Clang),例如:
gcc -fopenmp -o sum_reduction sum_reduction.c
运行上面的程序,你将得到数组中所有元素的总和。
其他构造
critical构造
#pragma omp critical
创建线程互斥的代码区域(需要在并行区内创建)
OpenMP中的 critical 语向是用来指定一段代码区域,�该区域内同一时间只能由一个线执行在并行编程中,某些作(更新共享数据)可能需要与斥访问
Sections构造
- 将并行区内的代码块划分为多个section分配执行
- 可以搭配parallel合成为parallel sections构造
- 每个section由一个线程执行 示例代码
#pragma omp parallel sections
{
#pragma omp section{Code}
#pragma omp section{Code}
#pragma omp section{Code}
}
barrier构造 single构造 master构造 atomic构造
对不同从句私有变量的探究
四个线程对一个数循累加,记录每个��线程最后输出的结果 (代码在文件中shared_variable.cpp文件中)

- 如果不写private的话,可以在并行区内进行变量初始化,不然线程对这个共享变量的访问时随机的,结果混乱
- 使用private的话需要注意初始化的问题,变量需要重新进行初始化,如果不初始化就会出现图上的情况
- 使用firstprivate不需要对变量进行初始化,会自动根据据主线程的数据进行初始化,就是主线程的这个变量运行到这里是多少,在并行区中就被初始化为多少
特招题实践
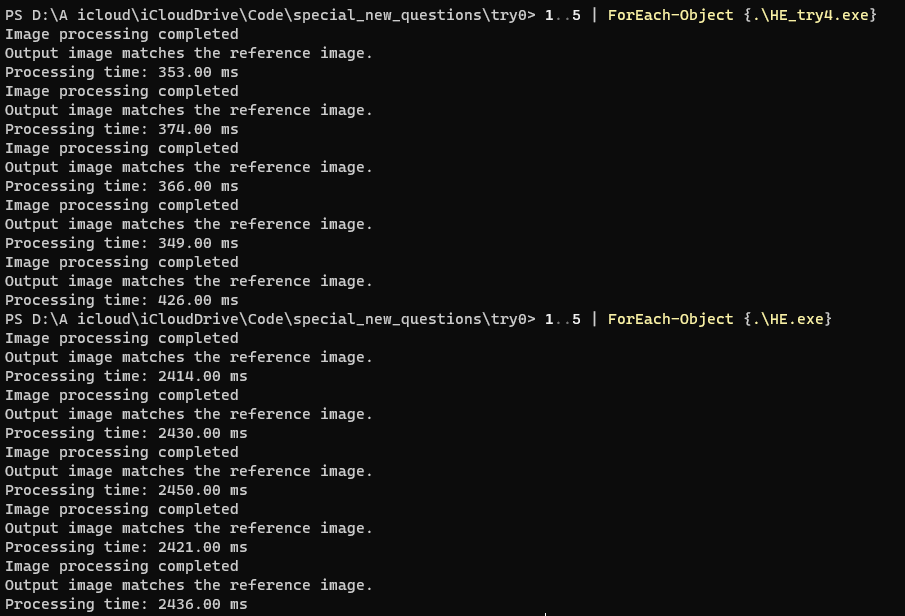
优化效果
原代码:2430ms && try4:380ms && 加速比:639.47%
基本思路
使用OpenMP对不同的部分进行并行化
详细思路
part1 并行化读取图像的直方图信息
// 使用OpenMP并行化直方图计算
#pragma omp parallel
{
int localHistogramRed[256] = {0};
int localHistogramGreen[256] = {0};
int localHistogramBlue[256] = {0};
#pragma omp for nowait
for (int i = 0; i < infoHeader.width * infoHeader.height; i++)
{
localHistogramRed[imageData[i].red]++;
localHistogramGreen[imageData[i].green]++;
localHistogramBlue[imageData[i].blue]++;
}
// 合并局部直方图到全局直方图
#pragma omp critical
{
for (int i = 0; i < 256; i++)
{
histogramRed[i] += localHistogramRed[i];
histogramGreen[i] += localHistogramGreen[i];
histogramBlue[i] += localHistogramBlue[i];
}
}
}
-
初始化局部直方图数组: 在OpenMP并行区域中,为每个线程分别创建三个颜色通道的局部直方图数组,用于存储当前线程所处理像素对应的红色、绿色和蓝色通道的计数。
-
并行计算局部直方图: 使用OpenMP的
#pragma omp for nowait指令对图像中的每个像素进行并行遍历,各线程独立地累加各自负责部分像素在RGB三个通道的直方图 从而将计算任务分解到多个线程上执行,提高处理速度。 -
合并局部直方图至全局直方图: 当所有线程完成局部直方图的计算后,将它们汇总到全局直方图数组中。 这里使用了OpenMP的
#pragma omp critical区域来确保线程安全的同步操作——只有当一个线程进入临界区时,其他线程才会等待,防止同时修改全局直方图数据导致的数据竞争问题。在临界区内,各线程将自己的局部直方图累加到全局直方图中。
part2 分线程累计三个通道的直方图的计算
// 使用OpenMP并行化累积直方图的计算
#pragma omp parallel sections
{
#pragma omp section
{
cumulativeHistogramRed[0] = histogramRed[0];
for (int i = 1; i < 256; i++)
{
cumulativeHistogramRed[i] = cumulativeHistogramRed[i - 1] + histogramRed[i];
}
}
#pragma omp section
{
cumulativeHistogramGreen[0] = histogramGreen[0];
for (int i = 1; i < 256; i++)
{
cumulativeHistogramGreen[i] = cumulativeHistogramGreen[i - 1] + histogramGreen[i];
}
}
#pragma omp section
{
cumulativeHistogramBlue[0] = histogramBlue[0];
for (int i = 1; i < 256; i++)
{
cumulativeHistogramBlue[i] = cumulativeHistogramBlue[i - 1] + histogramBlue[i];
}
}
}
通过#pragma omp parallel sections指令,用三个section分成红绿蓝三个通道的直方图独立的任务,并由三个不同的线程执行。这样可以同时对红色、绿色和蓝色通道的累积直方图进行计算。
part3 并行化归一化直方图和映射
// 并行化计算归一化直方图和映射
float totalPixelsInverse = 1.0f / (infoHeader.width * infoHeader.height);
#pragma omp parallel for
for (int i = 0; i < 256; i++)
{
float normRed = cumulativeHistogramRed[i] * totalPixelsInverse;
float normGreen = cumulativeHistogramGreen[i] * totalPixelsInverse;
float normBlue = cumulativeHistogramBlue[i] * totalPixelsInverse;
normalizedHistogramRed[i] = normRed;
normalizedHistogramGreen[i] = normGreen;
normalizedHistogramBlue[i] = normBlue;
mappingRed[i] = (int)(255 * normRed + 0.5f);
mappingGreen[i] = (int)(255 * normGreen + 0.5f);
mappingBlue[i] = (int)(255 * normBlue + 0.5f);
}
part4 并行化像素值更新
// 使用OpenMP并行化像素值更新
#pragma omp parallel for
for (int i = 0; i < infoHeader.width * infoHeader.height; i++)
{
imageData[i].red = mappingRed[imageData[i].red];
imageData[i].green = mappingGreen[imageData[i].green];
imageData[i].blue = mappingBlue[imageData[i].blue];
}
使用OpenMP的#pragma omp parallel for指令来实现并行化
+++